
自从yolov5-5.0加入se、cbam、eca、ca发布后,反响不错,也经常会有同学跑过来私信我能不能出一期6.0版本加入注意力的博客。个人认为是没有必要专门写一篇来讲,因为步骤几乎一样,但是问的人也慢慢多了,正好上一篇加入注意力的文章写的略有瑕疵,那就再重新写一篇。
yolo加入注意力三部曲
1.common.py中加入注意力模块
2.yolo.py中增加判断条件
3.yaml文件中添加相应模块
所有版本都是一致的,加入注意力机制能否使模型有效的关键在于添加的位置,这一步需要视数据集中目标大小的数量决定。
第一部曲:common.py加入注意力模块
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
第二部曲:yolo.py中增加判断条件
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost,CBAM,CoordAtt,SE]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
第三部曲:yaml文件中添加注意力
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, CoordAtt,[1024]],
[-1, 1, SPPF, [1024, 5]], # 9
这是6.0版本的yolov5的骨干层,CoordAtt的位置可以换成以上任意一个注意力,其他参数不需要调整,傻瓜式复制粘贴,即可跑通。
以上就是具体将注意力添加至yolov5-6.0版本中的步骤。注意力模块并没有刻板规定一定要加在什么地方,使用者可随意调整。
接下来是理论部分。关于注意力的理论部分,各位博主大佬已经讲的非常细致了(这个地方想了半天成语想不出来),但是为了证明本人出色的复制粘贴能力,决定再写一下。
SE(挤压-激励注意力)
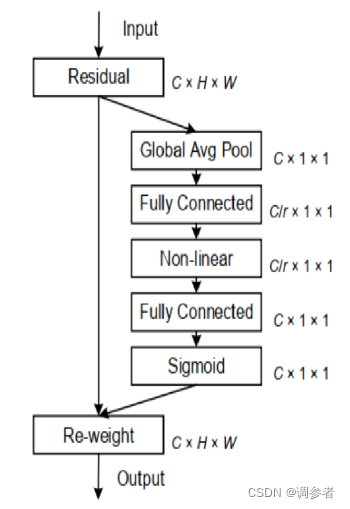
se注意力增强模型关注对象的方法分为两步:
挤压
对输入的特征图进行通道信息的全局平均池化,即挤压

激励
将挤压之后的信息通过两个全连接层、激活函数再归一化后乘到输入特征图上

CA(位置注意力)
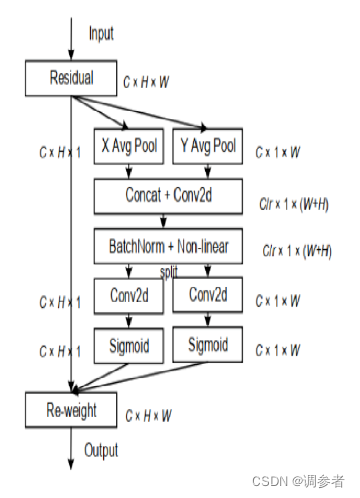
位置注意力将通道注意力分解为两个1维特征编码过程,分别沿2个空间方向聚合特征。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。
coordinate信息嵌入

coordinate attention生成

(注:理论部分非本人原创,如有侵权,请联系我删除。)
总结
各个注意力机制使用后的感受,yolov5中个人感觉CA效果最好。
本文转载自: https://blog.csdn.net/zqt321/article/details/123647444
版权归原作者 调参者 所有, 如有侵权,请联系我们删除。
版权归原作者 调参者 所有, 如有侵权,请联系我们删除。