
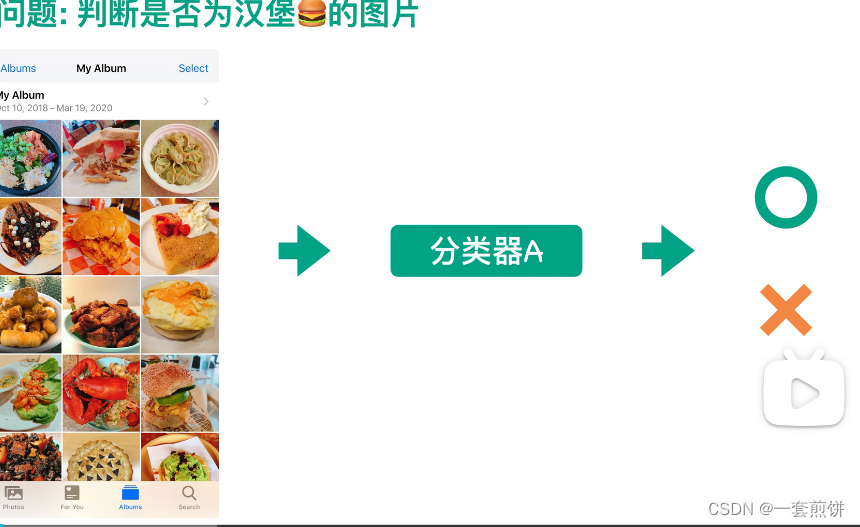
假设现在有一个分类器A,这个分类器A的作用是告诉一张图片是不是汉堡,那我想知道这个分类器A的效果好不好,应该怎么办呢?
最简单的方法是将大量的样本放进到费雷其A当中,让他自己判断这些图片是不是汉堡。
经过上面的过程就可以得到一张表格:

实际上这张表格是非常庞大的。有成千上万的图片,当他的维度十分大的时候是没办法看出来的。现在就是用一种方法能够直观地表示实验结果,但是又不损失其中的信息,那看一下他的输出结果都有什么样的情况,正式的类别就两种情况,他是汉堡和不是汉堡。而预测类别也是两种情况是汉堡和不是汉堡,所以加起来就四种情况:
接下来就是做一个统计,这四种类别所对应的图是多少张。
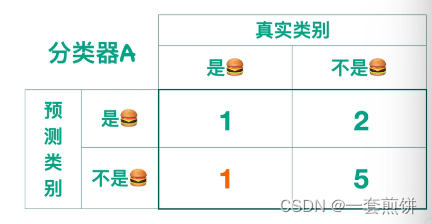
上面这四个数组成的矩阵叫做混淆矩阵

用着四个数来表现出分类器在测试数据集上的效果。颜色是绿色的表示预测的结果是对的,橙色的部分表明预测结果是错的。这个2×2的矩阵是对二分类来说的。
对于多分类的问题,现在是想知道输入的这图片当中有没有我想要的图片。
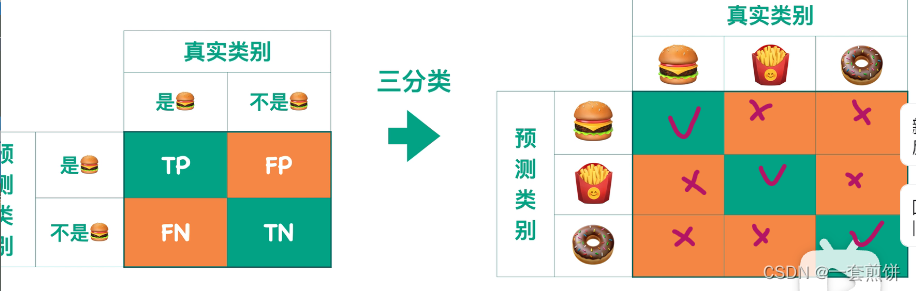
N分类的问题:N×N的矩阵
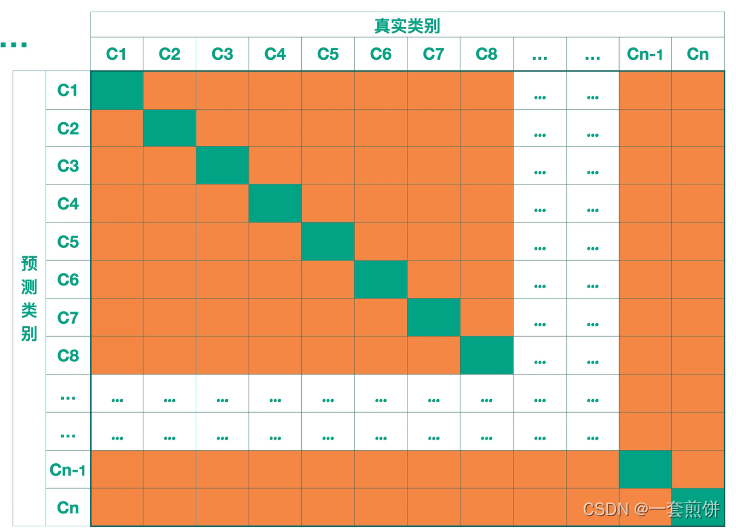
我们希望的是绿色的部分的数值尽可能地大,橙色部分的数值尽可能地小。这样模型的效果是更好的。
补充:
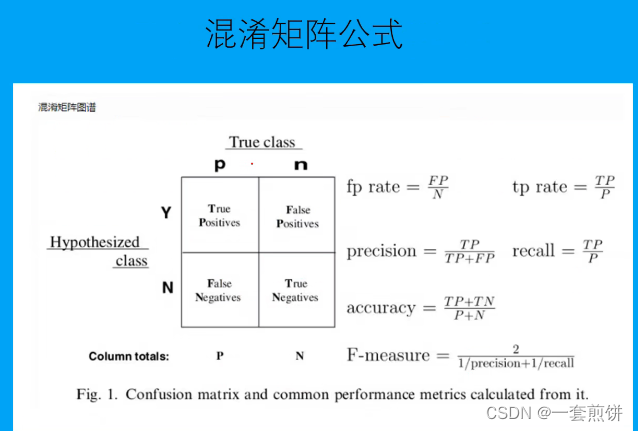
混淆矩阵是对分类问题的预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按照每个类别进行细分,这是混淆矩阵的关键所在。混淆矩阵显示了额分类模型在进行预测时会对那一部分产生混淆,不仅能了解分类模型所犯的错误,更重要的是可以了解发生错误的类型。这是这种对结果的分解客服了仅使用分类准确率所带来的局限性。
从混淆矩阵得到分类指标
跟高级的分类指标:准确度,正确率或者时精确度,召回率,特异性,灵敏度
本文转载自: https://blog.csdn.net/upupyon996deqing/article/details/124768166
版权归原作者 一套煎饼 所有, 如有侵权,请联系我们删除。
版权归原作者 一套煎饼 所有, 如有侵权,请联系我们删除。