
一、MOT( mutil-object tracking)步骤
在《DEEP LEARNING IN VIDEO MUTIL-OBJECT TEACKING: A SURVEY》这篇基于深度学习多目标跟踪综述中,描绘了MOT问题的四个主要步骤
1.跟定视频原始帧
2.使用目标检测器如Faster-rcnn, YOLO, SSD等进行检测,获取目标检测框。
3.将所有目标框中对应的目标抠出来,进行特征提取(表观特征或者运动特征)
4.进行相似度计算,计算前后两帧目标之间的匹配程度(前后属于同一个目标的之间距离比较小,不同目标的距离比较大)
5.数据关联,为每一个对象分配目标ID
总结起来,MOT算法主要为四个步骤:1.检测;2.特征提取,运动预测;3.相似度计算;4.数据关联。
二、SORT:Simple Online and Realtime Tracking
1、算法流程:
算法的核心是卡尔曼滤波和匈牙利算法,这两个算法比较偏数学,所以需要学习这两个算法的数学知识,比较有难度。
卡尔曼滤波的基本知识建议看这篇博客:https://blog.csdn.net/u010720661/article/details/63253509,本文不再对其进行数学证明。
匈牙利算法基本知识:https://blog.csdn.net/NIeson2012/article/details/94472313?ops_request_misc,本文不再对其算法细节进行讨论。
如图:
2、卡尔曼滤波:
基于传感器(在目标跟踪中即目标检测器)的测量值与跟踪器(卡尔曼滤波)的预测值,实现更精确的跟踪目标估计。
卡尔曼滤波的假设变量都是随机的,并且都服从高斯分布(正态分布),每一个变量都有一个均值
μ
\mu
μ,表示随机分布的中心(最可能的状态),以及方差
σ
2
\sigma^2
σ2,表示不确定性。
1.目标跟踪中,需要track以下两个状态:
**均值
μ
\mu
μ**:表示目标的位置信息,其由8维向量表示
x
=
[
u
,
v
,
s
,
r
,
u
˙
,
v
˙
,
s
˙
]
x=[u, v, s, r, \dot{u}, \dot{v}, \dot{s}]
x=[u,v,s,r,u˙,v˙,s˙],分别为:bbox的中心坐标
(
u
,
v
)
(u, v)
(u,v),面积
s
s
s,宽高比
r
r
r(SORT中认为
r
r
r是不变的常数,而DeepSORT认为其是一个变量),以及各自的速度变化值组成。
**协方差
P
P
P**:表示目标位置信息的不确定信息,由8×8的对角矩阵
P
P
P表示。
2.目标跟踪时,需要track在
t
+
1
t+1
t+1时刻的状态(卡尔曼滤波器采用匀速模型和线性观测器模型)
x
t
+
1
=
F
x
t
P
t
+
1
=
F
P
t
F
T
+
Q
x_{t+1} = Fx_t \\ P_{t+1} = FP_tF^{T} + Q
xt+1=FxtPt+1=FPtFT+Q
其中,
F
F
F表示预测矩阵,在本算法(匀速模型:
x
t
=
x
t
−
1
+
△
t
x
t
−
1
˙
x_t = x_{t-1} + \triangle t\dot{x_{t-1}}
xt=xt−1+△txt−1˙)中表示为:
F
=
[
1
0
0
d
t
0
0
0
0
1
0
0
d
t
0
0
0
0
1
0
0
d
t
0
0
0
0
1
0
0
d
t
0
0
0
0
1
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
1
]
F=\begin{bmatrix} 1 & 0 & 0 & dt & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & dt & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & dt & 0 \\ 0 & 0 & 0 & 1 & 0 & 0 & dt \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 1 \\ \end{bmatrix}
F=100000001000000010000dt0010000dt0010000dt0010000dt001
P
P
P是协方差矩阵为经验参数,初始状态为:
P
=
d
i
a
g
(
[
2
σ
p
h
,
2
σ
p
h
,
1
e
−
2
,
2
σ
p
h
,
10
σ
v
h
,
10
σ
v
h
,
1
e
−
5
)
P=diag([2\sigma_ph, 2\sigma_ph, 1e-2, 2\sigma_p h, 10 \sigma_vh, 10 \sigma_v h, 1e-5)
P=diag([2σph,2σph,1e−2,2σph,10σvh,10σvh,1e−5)
Q是系统噪声,初始状态为:
Q
=
d
i
a
g
(
[
σ
p
h
,
σ
p
h
,
1
e
−
2
,
σ
p
h
,
σ
v
h
,
σ
v
h
,
1
e
−
5
)
2
Q = diag([\sigma_ph, \sigma_ph, 1e-2, \sigma_ph, \sigma_vh, \sigma_vh,1e-5)^2
Q=diag([σph,σph,1e−2,σph,σvh,σvh,1e−5)2
3.基于预测结果进行匹配并更新卡尔曼滤波器:
首先利用匈牙利算法关联卡尔曼滤波器的预测阶段(第2步)的估计结果和实际观测结果:若1.匹配成功则更新卡尔曼滤波器;2.匹配失败的跟踪轨迹视为丢失;3.匹配失败的观测量记为新增轨迹。
若匹配成功,则track根据匹配结果进行更新
a)
H
H
H:测量矩阵,将track的均值向量
x
′
x'
x′映射到检测空间
H
x
⇒
[
u
v
s
r
]
=
[
1
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
1
0
0
0
0
0
0
0
1
0
0
0
]
[
u
v
s
r
u
˙
v
˙
s
˙
]
Hx \Rightarrow \begin{bmatrix}u\\ v\\s\\r \end{bmatrix} = \begin{bmatrix} 1 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 0 & 0 & 0 \end{bmatrix} \begin{bmatrix} u\\v\\s\\r\\\dot{u}\\\dot{v}\\\dot{s}\\ \end{bmatrix}
Hx⇒uvsr=1000010000100001000000000000uvsru˙v˙s˙
检测结果
z
z
z与track的均值误差:
y
=
z
−
H
x
′
y=z - Hx'
y=z−Hx′
b)将协方差矩阵
P
t
+
1
P_{t+1}
Pt+1映射到检测空间,加上噪声矩阵
R
R
R
S
=
H
P
′
H
T
+
R
S=HP'H^{T} + R
S=HP′HT+R
其中,检测器噪声矩阵:
R
=
d
i
a
g
(
[
σ
p
h
,
σ
p
h
.
1
e
−
1
,
σ
p
h
]
T
)
2
R=diag([\sigma_ph, \sigma_ph. 1e-1, \sigma_ph]^T)^2
R=diag([σph,σph.1e−1,σph]T)2
c)计算卡尔曼增益
K
K
K(关于
K
K
K的定义请查看推荐博文):
K
=
P
′
H
T
S
−
1
K = P'H^TS^{-1}
K=P′HTS−1
d)计算跟新后的均值向量个协方差矩阵:
x
=
x
′
+
K
y
P
=
(
I
−
K
H
)
P
′
x = x' + Ky \\ P = (I - KH)P'
x=x′+KyP=(I−KH)P′
e)进行下一轮的跟踪,直至当前轨迹跟踪结束。
3、匈牙利算法:
匈牙利算法在多目标跟踪中解决数据关联(检测框和预测框与实际框的匹配)的问题。
将当前帧目标检测的框和上一帧通过卡尔曼滤波预测的框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix)。而代价矩阵作为匈牙利算法的输入,得到线性的匹配结果。
缺点:造成了Sort算法无法解决行人重叠的问题。所以其IDSW(ID switch)这个指标很差。(IDSW(ID switch),对于同一个目标,由于跟踪算法误判,导致其ID发生切换的次数称为IDSW。跟踪算法中理想的ID switch应该为0。)且其直接丢弃掉IOU小于阈值的作法也导致了无法解决遮挡的问题。
4、总结:
1.SORT算法原文使用匀速直线运动模型,故在一些应用场景下可能不适用。
2.关联匹配中没有使用特征,造成物体间在重合度比较高的情况下会发生ID-Switch。
3.速度非常快而且计算量小。
二、DeepSORT
1、算法流程:
卡尔曼滤波+匈牙利算法+级联匹配+状态估计
其中,卡尔曼滤波和匈牙利算法在SORT中已经介绍,在此不在赘述
算法流程如图: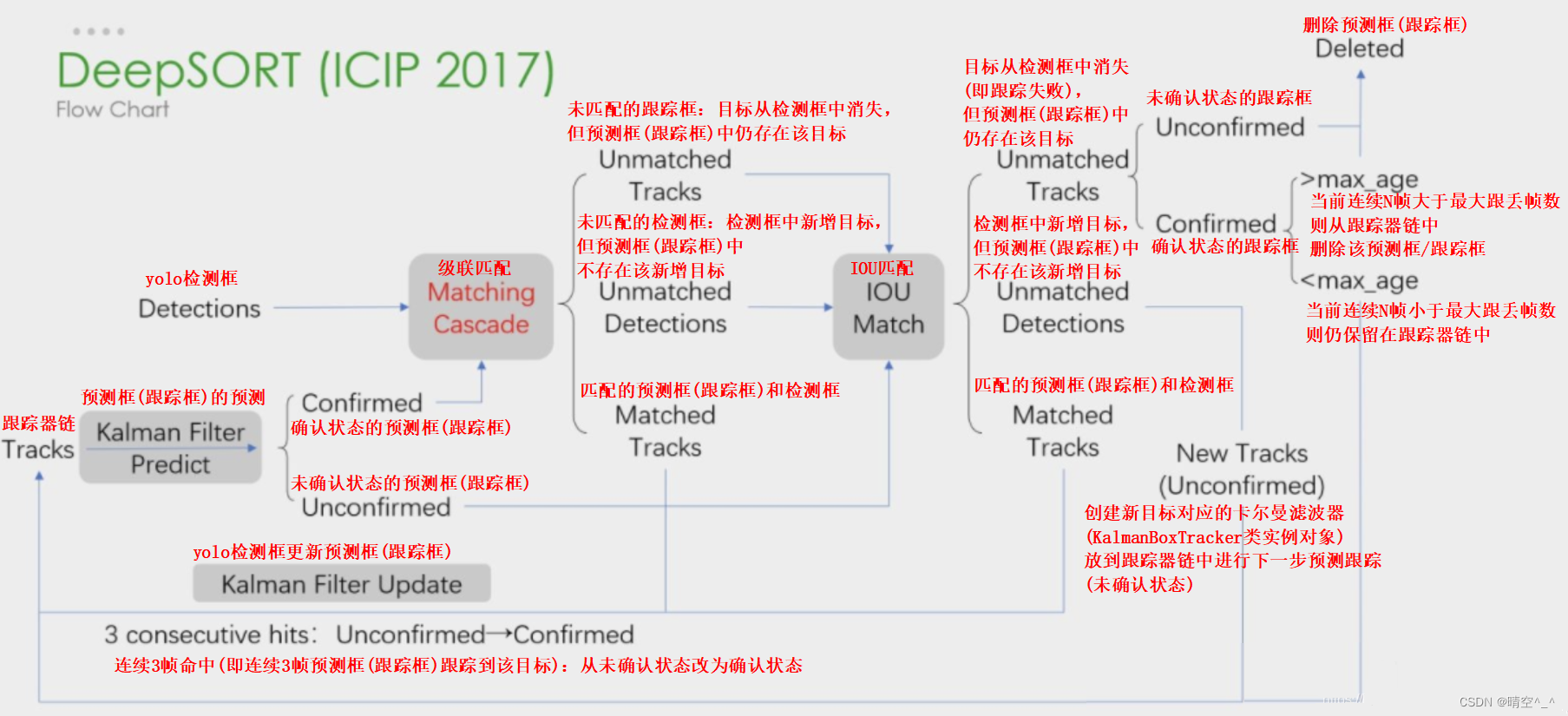
DeepSORT算法在SORT算法的基础上增加了级联匹配(matching cascade)和状态估计(confirmed)。因此,本文只介绍级联匹配和状态估计。
DeepSORT相对SORT的主要改进为:
考虑两个目标遮挡的情况。匹配的目标的Track无法匹配Detection,目标暂时从图像中消失。之后被遮挡的目标再次出现的时候,应该让被遮挡的目标分配的ID不再变化,减少ID-Switch的次数。
2、Deep由来:
为了减少ID-Switch的次数,在跟踪框跟丢且max age仍没达到最大阈值时,track应保存该跟踪框的外观特征,以便其再出现时仍能对其跟踪。DeepSORT通过一个小型的CNN网络来提取跟踪目标的外观特征,在每次(每帧)检测+追踪后,进行一次物体外观特征的提取并保存。后面每执行一步,都要执行一次当前帧被检测物体外观特征与之前存储的外观特征的相似度计算,这个相似度将作为一个重要的判别依据(不是唯一的,因为作者说是将运动特征与外观特征结合作为判别依据,这个运动特征就是SORT中卡尔曼滤波做的事)。
如图,CNN网络最终输出为128维的特征向量。注意:DeepSORT的原文数据集是行人检测,在其他应用场景时可以修改网络输入框的大小。
3、状态估计

对于一个轨迹,都计算当前帧距上次匹配成功帧的差值,该变量在卡尔曼滤波器predict的时候递增,在轨迹和detection关联的时候重置为0。
超过max age的轨迹被认为离开图片区域,从轨迹集合中删除,设置为删除状态。代码中max age默认值为70,是级联匹配中的循环次数。
如果detection没有和现有track匹配上的,那么将对这个detection进行初始化,转变为新的Track。新的Track初始化的时候的状态是未确定态,只有满足连续三帧都成功匹配,才能将未确定态转化为确定态。如果处于未确定态的Track没有在n_init帧中匹配上detection,将变为删除态,从轨迹集合中删除。
4、级联匹配
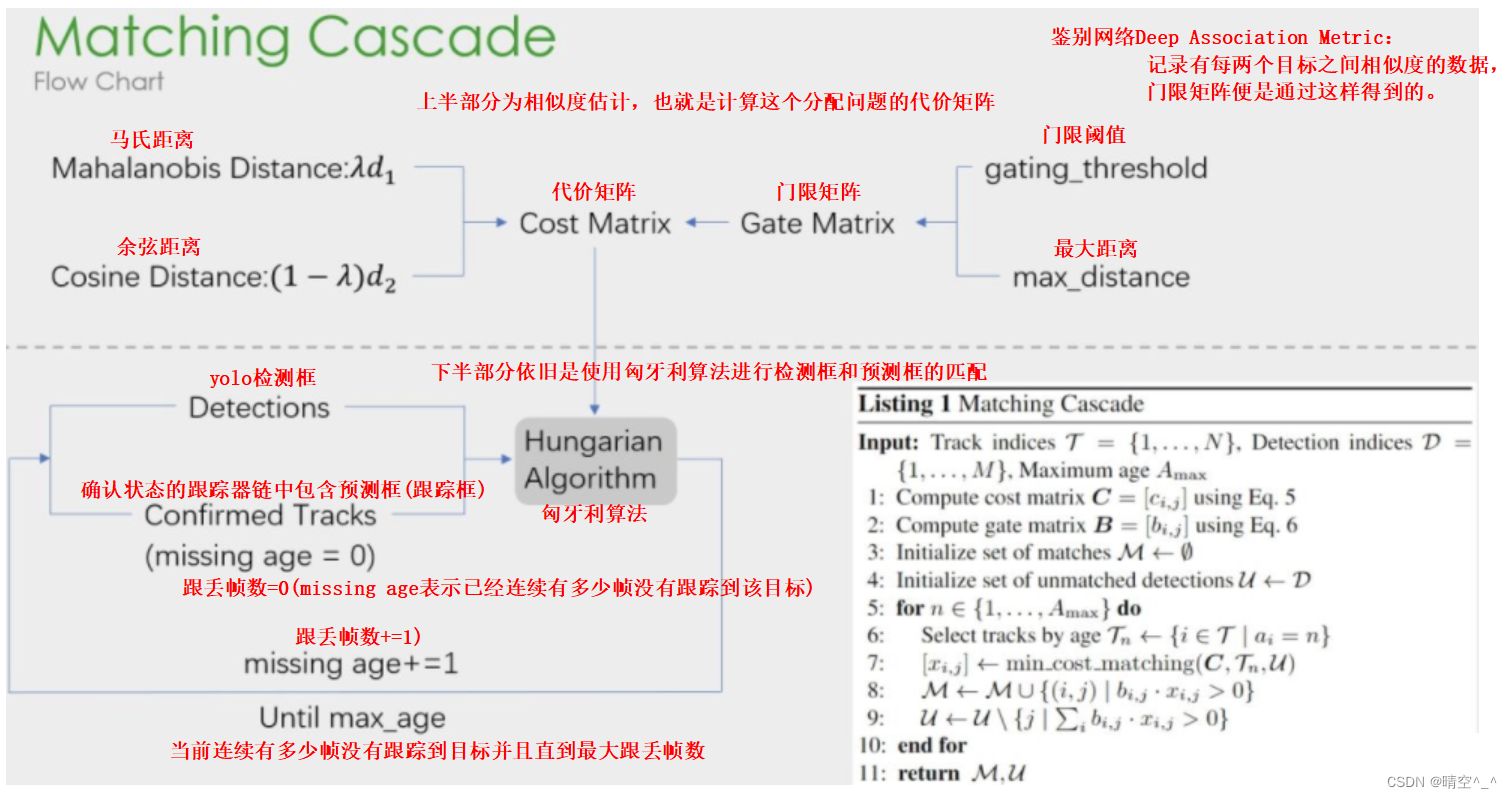
如图:
1.上半部分计算相似度矩阵的方法使用了外观模型(ReID)和运动模型(马氏距离)来计算相似度,得到代价矩阵;另一个则是门控矩阵,用于限制代价矩阵中过大的值。
2.下半部分是级联匹配的数据关联步骤,匹配过程是一个循环(max_age个迭代,默认为70),从missing age=0到missage age=70的轨迹和Detection进行匹配,没有丢失过的轨迹优先被匹配,丢失较为较为久远的靠后匹配。通过这部分处理,可以重新将遮挡目标找回,降低被遮挡然后再出现目标发生的ID Switch次数。
运动特征:
使用马氏距离,衡量预测到的卡尔曼滤波状态和新获得的检测框之间的距离。
d
1
(
i
,
j
)
=
(
d
j
−
y
j
)
T
S
i
−
1
(
d
j
−
y
i
)
d_1(i, j)=(d_j-y_j)^TS_i^{-1}(d_j-y_i)
d1(i,j)=(dj−yj)TSi−1(dj−yi)
其中:
(
y
i
,
S
i
)
(y_i,S_i)
(yi,Si)表示第
i
i
i个跟踪分布(卡尔曼滤波分布)在测量空间的投影,
y
i
y_i
yi为均值,
S
i
S_i
Si为协方差。马氏距离通过测量卡尔曼滤波器的追踪位置均值(mean track location)之间的标准差与检测框来计算状态估计间的不确定性,即
d
i
(
i
,
j
)
d_i(i, j)
di(i,j)为第i个追踪分布和第j个检测框之间的马氏距离(不确定度)。对马氏距离设定一定的阈值,可以排除那些没有关联的目标,原文以倒卡方分布计算出来的95%置信区间作为阈值。
外观特征:
外观特征使用CNN残差网络提取,返回128维的特征向量。对于每个检测框(编号为j)内物体
d
j
d_j
dj ,其128维度的向量设为
r
j
r_j
rj ,该向量的模长为1,即
∣
∣
r
j
∣
∣
=
1
||r_j||=1
∣∣rj∣∣=1。
接着作者对每个目标k创建了一个gallery,该gallery用来存储目标在每一帧中的外观特征(128维向量),论文中用
R
k
R_k
Rk表示。注意,这里的k的含义是追踪的目标k,也就是object-in-track的序号,不是物体的ID号。
R
k
=
{
r
k
(
i
)
}
k
=
1
(
L
k
)
R_k = \{r^{(i)}_{k}\}^{(L_k)}_{k=1}
Rk={rk(i)}k=1(Lk)就是gallery。作者限定了
L
k
L_k
Lk的大小最大为100,即最多只能存储目标
k
k
k时刻前100帧的目标外观特征。
i
i
i为跟踪的编号。
之后,获得检测框
j
j
j的外观特征
r
j
r_j
rj,求解所有已知gallery中的外观特征与检测框(编号为
j
j
j)的外观特征的最小余弦距离。
d
2
(
i
,
j
)
=
m
i
n
{
1
−
r
j
T
r
k
(
i
)
∣
r
k
(
i
)
∈
R
i
}
d_2(i, j)=min\{ 1-r_j^Tr_k^{(i)} | r_k^{(i)} \in R_i \}
d2(i,j)=min{1−rjTrk(i)∣rk(i)∈Ri}
运动(motion)特征和外观(appearance)特征的融合:
motion提供了物体定位的可能信息,这在短期预测中非常有效;
appearance(余弦距离计算)可在目标被长期遮挡后恢复ID的编号。
C
i
,
j
=
λ
d
1
(
i
,
j
)
+
(
1
−
λ
)
d
2
(
i
,
j
)
C_{i, j}= \lambda d_1(i, j) + (1 - \lambda)d_2(i, j)
Ci,j=λd1(i,j)+(1−λ)d2(i,j)
其中,
d
1
d_1
d1为马氏距离,
d
2
d_2
d2为余弦距离,
λ
\lambda
λ为权重系数。
对刚初始化的目标等无法确认(匹配)的追踪,因为没有之前的运动信息和外观信息,采用IOU匹配关联进行追踪。
5、总结:
1.目标检测的效果对结果影响非常非常大,并且Recall和Precision都应该很高才可以满足要求。
2.表观特征:也就是ReID模型,原论文中用的是CNN残差神经网络,含有的参数量比较大,可以考虑用新的、性能更好、参数量更低的ReID模型来完成这部分工作。
版权归原作者 晴空^_^ 所有, 如有侵权,请联系我们删除。