
掀桌子的Segment Anything
本来不打算再发关于分割的相关内容的,但是13小时前,2023年4月5号,Meta AI在Arxiv网站发布了文章《Segment Anything》,并将SAM模型代码和数据开源。作为通用的分割网络,SAM或许将成为,甚至是已经成为了CV届的ChatGPT。简简单单的两个词Segment Anything,简单粗暴却不失优雅。
说一些题外话,大概2023年初这段时间,ChatGPT访问量在国内迅速爆发(当然需要一些魔法),这个基于Transformer的大型预训练模型,直接就把NLP研究者们的饭桌给掀翻了(此处应该有乌鸦哥)。

OpenAI的ChatGPT满足了我小时候对未来科技的幻想,什么小学生写日记,ChatGPT给你写;暑假作业不会做,问ChatGPT;1+1不会算?ChatGPT给你算!ChatGPT就是这么简单粗暴,哪里不会点哪里,比步步高点读机还要牛逼。
随后微软、谷歌也相继发布了类ChatGPT的产品New-Bing、Bard。当然这里鞭尸一下百度的文言一心,一坨答辩。这方面国内确实做的不好,平均落后1-2年。当然,你OpenAI、Google、Microsoft什么公司,我百度什么公司,我有那个能力吗,我能做吗,做不了懂不懂啊(有请Batman)。

当然,不光是钱的问题,钱的问题好解决,难以解决的是大环境下人才的问题,这里的问题就复杂多了,总之,就是缺乏创新、缺乏设备、缺乏数据、不敢想、不敢做或者说敢想敢做却不能做,总是缺乏那一点心气,恰恰差了这点心气难成大事。OpenAI宁有种乎?

话说回来,Meta AI SAM模型的发布,同样掀翻了CV研究者们的饭桌。1100万张训练图像、11亿个mask 标签,如此大规模的训练数据集再加上Alexander Kirillov大神的一系列微操,Segment Anything成为囊中之物。
同样还是哪里不会点哪里,自动一键多任务分割,想要图中任何的东西,SAM都能给你割出来,只要你点一下或者框选一下甚至是提供文本。面对歧义的分割点时,甚至给你多个分割对象供你挑选。什么语义分割、实例分割、全景分割、视频追踪等等,统统拿下。总之就两个字——无敌(其实那两个字是通用)(人家确实无敌)。

一键式全景分割、实例分割

视频分割、追踪

交互式分割、一键分割

人家连文字输入也可以搞定哦!
人家的Demo又帅又多,直接上地址
Segment Anything | Meta AI (segment-anything.com)
你还可以上传你自己的图像
Segment Anything | Demo
简单割一下我自己,效果很不错,眼镜、书包带都给我割好了。还可以进行选框、选点。不过并未在Demo中找到文本输入的选项(再让我找找看)。

SAM

不得不说,人家做的就是好。连网络图还给你个会动的(当然是网页上,不是paper上)
先上一下人家的概念图
光看概念图,就能发现Meta AI的目标还是很远大的,要达到的就是ChatGPT的效果,就是要和人家并驾齐驱,要和你neck and neck。当大家还在考虑怎么发布和ChatGPT相似的聊天机器人时,人家已经独辟蹊径羽化登仙了。

图a,Meta AI想做什么不言而喻。人家就是希望能够通过一些点、框、位置、文字这种prompt提示,帮助model对image进行segment。
图b,prompt通过一个prompt encoder输入,image则是通过一个image encoder进行输入,最后信息在一个轻量的mask decoder中融合,分割出需要的mask。大道至简,简单的模型架构得到优秀的结果。就和我们的大脑,不就是神经元连来连去吗,但是人类的大脑就是如此神奇,如此聪明,还能诞生爱因斯坦这种天才。
图c,数据驱动,Meta收集了1100万张图像,11亿多个标注。不过其中99.1%的标注都是模型完成的,省去了大部分的时间和人力成本,也是基本操作。(再自我发问一下,我们就收集不到1100万张图像吗?可惜。要赚钱的嘛,baidu:莆田系医院,说你呢,你的广告费结一下)

再上网络模型图

让我们来看看模型结构到底是什么。

好吧,人家是Vit!懂不懂Vision Transformer的含金量!
📌What is the structure of the model?
- A ViT-H image encoder that runs once per image and outputs an image embedding
- A prompt encoder that embeds input prompts such as clicks or boxes
- A lightweight transformer based mask decoder that predicts object masks from the image embedding and prompt embeddings
分别是什么呢,1是一个ViT-H用来嵌入图像块。2是一个prompt编码器来嵌入像点、提示框这种提示。3是一个轻量化的Transformer encoder,这个东西可以根据图像嵌入特征和提供的点、框、文本提示来预测对象的分割mask。
好了,整体结构介绍完了,这些模块都是老朋友,都是先前的老工作(什么CLIP、MAE、ViT),但这些work一连起来,效果就是这么好。(国内企业扪心自问一下,为什么别人总是走在前面)。
细节一点说:
Image encoder
这里Image encoder选择ViT-H模型,用了何凯明的MAE方法进行预训练,保证模型能够适应高分辨率的图像。(不得不说,SAM模型的分割分辨率确实比别人优秀,最早Swin Transformer在高分辨率的情况下进行分割,现在SAM在更高的分辨率下获得了更好的效果,这得归功于数据量和MAE)
Prompt encoder
Prompt的输入包含两种,1是稀疏的prompt(点、框、文本),2是密集的prompt(掩码mask)。当然,这些Prompt要通过某种方式嵌入到特征之中才行,这里通过老熟人positional encoding将这些点和框进行嵌入(文中提到的是将这些点、框和学习到的image embeddings进行相加);基于CLIP中的方法(an off-the-shelf text encoder)对文本信息进行嵌入;通过卷积模块对mask进行嵌入(sum element-wise with the image embedding,同样是相加)。
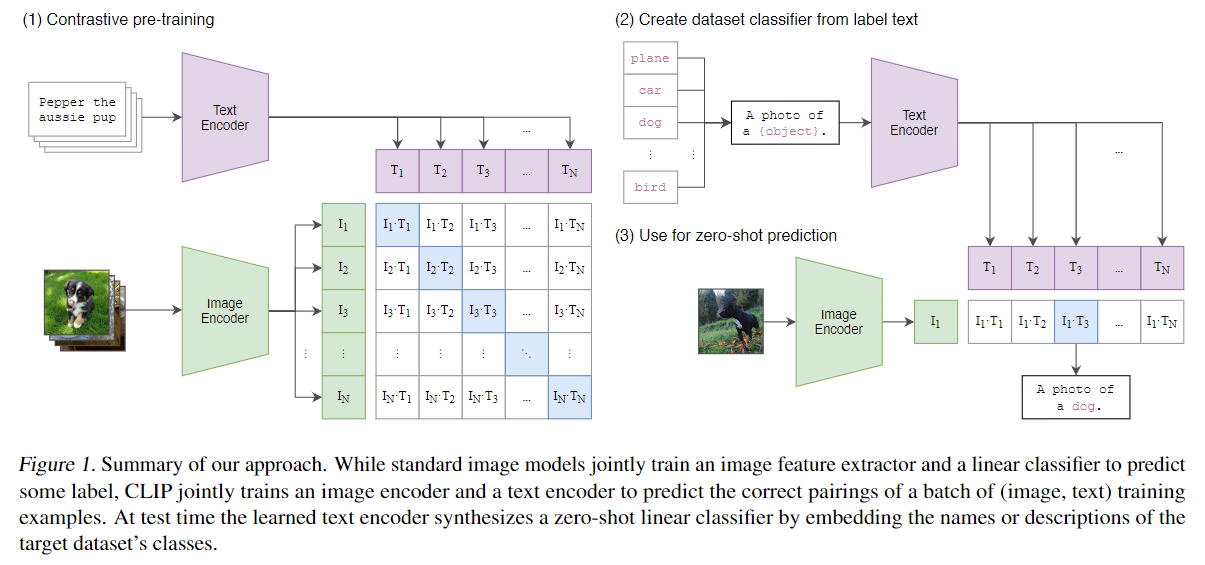
Clip的模型
Mask decoder
Mask decoder可以有效的将image embedding、prompt embedding的信息进行融合,输出mask结果。Mask decoder选择了Transformer结构,并在后面加了一个dynamic mask prediction head。不过这个Transformer中的Attention计算方式有所不同,这里添加了prompt self-attention和cross-attention对两个方向(prompt-to-image和image-to-prompt)进行计算,并更新embeddings特征。
Mask decoder一共包含了两个这样的Transformer block。运行完这两个block后,再对图像嵌入进行上采样,MLP 将输出标记映射到动态线性分类器,然后计算每个图像位置的mask probability。
这三个模块就简单讲完了。人家还做了一些其他工作。
Resolving ambiguity
对于一个输出,如果给出的prompt提示不明确,模型将平均多个有效掩码。这样的话效果可能不好,人还会看走眼呢。
为了解决这个问题,大神们修改了模型以预测单个提示的多个输出掩码(见下图)。基于经验,3 个mask输出就足够满足分割需求(嵌套mask有三个深度:整体、部分和子部分)(输出1个mask可能有错误,那我输出很多个就没错误了吧,属实大聪明,但是人家是真的有效果)。
输出的mask基于IoU分数进行排序。

Efficiency
在我自己的电脑上(3060GPU)运行了一下,ViT-H的模型还是能用的,把图像resize小一些,效率嘛,还是ViT运行占了时间花销,毕竟计算attention还是需要点时间的。不过整体上而言,足够贫民化,比ChatGPT好用多了。
Losses and training.
损失函数使用了focal loss 和 dice loss,属实是把以前好的工作都带上了。
训练时采用mixture of geometric prompts策略。
还在训练时设置了对prompt的随机采样来模拟交互设置(可以参考Reviving iterative training with mask guidance for interactive segmentation)。
Segment Anything Data Engine
本来数据驱动是没必要说的,而且用的还是大家都能想到的方法,但是人家做了,做的也很好,而且人家也开源了。
Meta收集了1100万张图像、11亿mask。通过渐进的三个阶段对数据进行标注
- Assisted-manual stage:手动标注阶段类似于原始的labelme标注。不过看起来是Meta内部基于初始的SAM模型开发了一个标注框架,使用SAM模型先进行分割,然后在结果上手动调整。这至少比从头开始要快。说明Meta在较早时期就着手开发SAM了。在这一阶段获取了大概12万张图像。
- Semi-automatic stage:在这个阶段,收集的图像往多样性方向发展,以提高模型在各种物品上的分割效果。还是人+SAM结合的标注方法。不过这一阶段SAM输出的mask更多,平均为44-72个,说明SAM能够看到更多的东西了。
- Fully automatic stage:全自动阶段自然就是SAM模型来自动分割。本身SAM已经被喂入足够多的数据,在分割任务上也能得到相对好的效果。 而且在这一阶段加入了Resolving ambiguity,如果一个部位有歧义,那就会返回整体、部分、子部分三个mask。
Segment Anything Dataset
数据集也可以提一嘴。
These images are high resolution (3300×4950 pixels on average), and the resulting data size can present accessibility and storage challenges
看起来Meta收集的图像质量都很高。个人认为,图像分割算法就是得往高分辨率的方向发展,人类的眼睛分辨率远远大于这个数值,模型自然需要获得更高分辨率的输入,当然目前还是受限于计算量,毕竟Attention在高分辨率图像下计算量还是十分之大。以前由于CNN感受野受限,图像分辨率还局限在1024以下。(COCO数据集为480×640,分辨率太低图实在是看不清,我的眼睛和大脑都看不清楚,怎么能指望模型能看清楚呢)
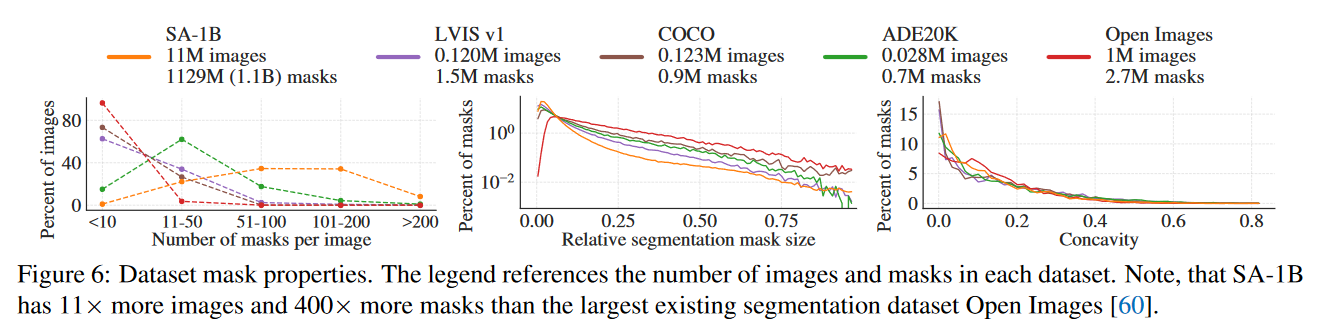
前面讲了,Mask是通过SAM模型输出来的,随机采样了500张图像对Mask进行评估,发现 mask的IoU在85-91%之间,结果还可以。
这里还绘制了数据集SA-1B的物体中心点分布。发现SA-1B和ADE20k分布比较类似,但SA-1B对角点覆盖更广泛。

SA-1B数据中mask的数量也普遍多于其他数据集,mask也相对更加细致。
其他实验部分就看原论文吧。
Discussion and Result
预训练模型
这些年使用预训练模型已经成为一个基本的trick了,以前一般用ImageNet上训练好的ResNet,后来用ViT,再后来何凯明提出MAE用于Transformer模型的预训练。经过在大规模数据集上进行预训练过的模型,往往能获得更好的效果。
组合和扩展
SAM模型可以扩展到其他任何CV相关的任务重,包括像基于RGB-D的3D重建、可穿戴设备对于目标点进行注释和提示(像什么智能眼镜,戴上变身赛文)
Limitation
SAM总体上看似完美,但还是存在一些小问题,毕竟作为通用的架构,保证的是在绝大部分图像上都能进行分割,而不是保证获得较高的IoU。在细节任务上,还是存在不足的,笔者也试了一些生物领域的数据集,至少效果还有待提升。
对于text-to-mask的任务,SAM的性能还是存在一些问题。毕竟CLIP也刚发不久,还有很长的路可以走。相信SAM能够像GPT一样,一飞冲天。
写在最后
因为本文写得比较仓促,部分专业性的描述可能有误。下午得知SAM模型,赶紧去翻了论文。如需考证,请查阅Segment Anything原论文。对于Zero-shot的实验部分也省略了,有兴趣的话还是看原论文,毕竟原文整篇文章写得十分精彩。
加油吧CVers。
最后,饭碗没了,是不是要考虑转行。
版权归原作者 yumaomi 所有, 如有侵权,请联系我们删除。