
tf-idf作为文体特征提取的常用统计方法之一,适合用于文本分类任务,本文从原理、参数详解及实战全方位详解tf-idf,掌握本篇即可轻松上手并用于文本数据分类。
一、原理
tf 表示****词频****(某单词在某文本中的出现次数/该文本中所有词的词数),idf表示****逆文本频率****(语料库中包含某单词的文本数、的倒数、取log),tf-idf则表示****词频******** ********* 逆文档频率****,tf-idf认为词的重要性随着它在文本中出现的次数成正比增加,但同时会随着它在整个语料库中出现的频率成反比下降。
idf表达式如下,其中k为包含某词的文本数,n为整个语料库的文本数
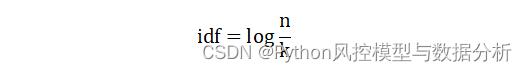
对idf进行平滑、避免出现极大/极小值(smooth_idf=True)
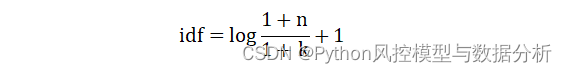
二、实战
sklearn中提供的文本处理方法
实际应用结果如下图(1-grams + 2-grams):
本文通过使用例子实战,展示这几类的使用方法及功能,以及详细的参数解释、方便不同需求下自行使用。

1、导包
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer,TfidfVectorizer
2、初始化词频向量/tf_idf的训练参数
由于存在功能组合的问题,TfidfVectorizer参数=CountVectorizer参数+TfidfTransformer参数,因此初始化参数函数将三部分参数汇总,通过设置传参label、用于确定所需要返回的参数字典。
def init_params(label='TfidfVectorizer'):
params_count={
'analyzer': 'word', # 取值'word'-分词结果为词级、'char'-字符级(结果会出现he is,空格在中间的情况)、'char_wb'-字符级(以单词为边界),默认值为'word'
'binary': False, # boolean类型,设置为True,则所有非零计数都设置为1.(即,tf的值只有0和1,表示出现和不出现)
'decode_error': 'strict',
'dtype': np.float64, # 输出矩阵的数值类型
'encoding': 'utf-8',
'input': 'content', # 取值filename,文本内容所在的文件名;file,序列项必须有一个'read'方法,被调用来获取内存中的字节;content,直接输入文本字符串
'lowercase': True, # boolean类型,计算之前是否将所有字符转换为小写。
'max_df': 1.0, # 词汇表中忽略文档频率高于该值的词;取值在[0,1]之间的小数时表示文档频率的阈值,取值为整数时(>1)表示文档频数的阈值;如果设置了vocabulary,则忽略此参数。
'min_df': 1, # 词汇表中忽略文档频率低于该值的词;取值在[0,1]之间的小数时表示文档频率的阈值,取值为整数时(>1)表示文档频数的阈值;如果设置了vocabulary,则忽略此参数。
'max_features': None, # int或 None(默认值).设置int值时建立一个词汇表,仅用词频排序的前max_features个词创建语料库;如果设置了vocabulary,则忽略此参数。
'ngram_range': (1, 2), # 要提取的n-grams中n值范围的下限和上限,min_n <= n <= max_n。
'preprocessor': None, # 覆盖预处理(字符串转换)阶段,同时保留标记化和 n-gram 生成步骤。仅适用于analyzer不可调用的情况。
'stop_words': 'english', # 仅适用于analyzer='word'。取值english,使用内置的英语停用词表;list,自行设置停停用词列表;默认值None,不会处理停用词
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b', # 分词方式、正则表达式,默认筛选长度>=2的字母和数字混合字符(标点符号被当作分隔符)。仅在analyzer='word'时使用。
'tokenizer': None, # 覆盖字符串标记化步骤,同时保留预处理和 n-gram 生成步骤。仅适用于analyzer='word'
'vocabulary': None, # 自行设置词汇表(可设置字典),如果没有给出,则从输入文件/文本中确定词汇表
}
params_tfidf={
'norm': None, # 输出结果是否标准化/归一化。l2:向量元素的平方和为1,当应用l2范数时,两个向量之间的余弦相似度是它们的点积;l1:向量元素的绝对值之和为1
'smooth_idf': True, # 在文档频率上加1来平滑 idf ,避免分母为0
'sublinear_tf': False, # 应用次线性 tf 缩放,即将 tf 替换为 1 + log(tf)
'use_idf': True, # 是否计算idf,布尔值,False时idf=1。
}
if label=='CountVectorizer':
return params_count
elif label=='TfidfTransformer':
return params_tfidf
elif label=='TfidfVectorizer':
params_count.update(params_tfidf)
return params_count
3、CountVectorizer训练及应用函数
def CountVectorizer_train(train_data,params):
cv = CountVectorizer(**params)
# 输入训练集矩阵,每行表示一个文本
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
cv_fit = cv.fit_transform(train_data)
return cv
def CountVectorizer_apply(model):
print('词汇表')
print(model.vocabulary_)
print('------------------------------')
print('特证名/词汇列表')
print(model.get_feature_names())
print('------------------------------')
print('idf_列表')
print(model.idf_)
print('------------------------------')
data=['Tokyo Japan Chinese']
print('{} 文本转化VSM矩阵'.format(data))
print(model.transform(data).toarray())
print('------------------------------')
print('转化结果输出为dataframe')
print(pd.DataFrame(model.transform(data).toarray(),columns=model.get_feature_names()))
print('------------------------------')
print('model参数查看')
print(model.get_params())
print('------------------------------')
4、CountVectorizer使用
train_data = ["Chinese Beijing Chinese",
"Chinese Chinese Shanghai",
"Chinese Macao",
"Tokyo Japan Chinese"]
params=init_params('CountVectorizer')
cv_model=CountVectorizer_train(train_data,params)
CountVectorizer_apply(cv_model)
查看结果可以发现,VSM矩阵并不是词频统计,其实是tf-idf的结果

5、TfidfTransformer训练及应用函数
def TfidfTransformer_train(train_data,params):
tt = TfidfTransformer(**params)
tt_fit = tt.fit_transform(train_data)
return tt
def TfidfTransformer_apply(model):
print('idf_列表')
print(model.idf_)
print('------------------------------')
data=[[1, 1, 0, 2, 1, 1, 0, 1]]
print('词频列表{} 转化VSM矩阵'.format(data))
print(model.transform(data).toarray())
print('------------------------------')
print('model参数查看')
print(model.get_params())
print('------------------------------')
train_data=[[1, 1, 1, 0, 1, 1, 1, 0],
[1, 1, 0, 1, 1, 1, 0, 1]]
params=init_params('TfidfTransformer')
tt_model=TfidfTransformer_train(train_data,params)
TfidfTransformer_apply(tt_model)
6、TfidfTransformer训练及应用函数
def TfidfVectorizer_train(train_data,params):
tv = TfidfVectorizer(**params)
# 输入训练集矩阵,每行表示一个文本
# 训练,构建词汇表以及词项idf值,并将输入文本列表转成VSM矩阵形式
tv_fit = tv.fit_transform(train_data)
return tv
def TfidfVectorizer_apply(tv_model):
print('tv_model词汇表')
print(tv_model.vocabulary_)
print('------------------------------')
print('tv_model特证名/词汇列表')
print(tv_model.get_feature_names())
print('------------------------------')
print('idf_列表')
print(tv_model.idf_)
print('------------------------------')
data=['Tokyo Japan Chinese']
print('{} 文本转化VSM矩阵'.format(data))
print(tv_model.transform(data).toarray())
print('------------------------------')
print('转化结果输出为dataframe')
print(pd.DataFrame(tv_model.transform(data).toarray(),columns=tv_model.get_feature_names()))
print('------------------------------')
print('tv_model参数查看')
print(tv_model.get_params())
print('------------------------------')
train_data = ["Chinese Beijing Chinese",
"Chinese Chinese Shanghai",
"Chinese Macao",
"Tokyo Japan Chinese"]
params=init_params('TfidfVectorizer')
tv_model=TfidfVectorizer_train(train_data,params)
TfidfVectorizer_apply(tv_model)
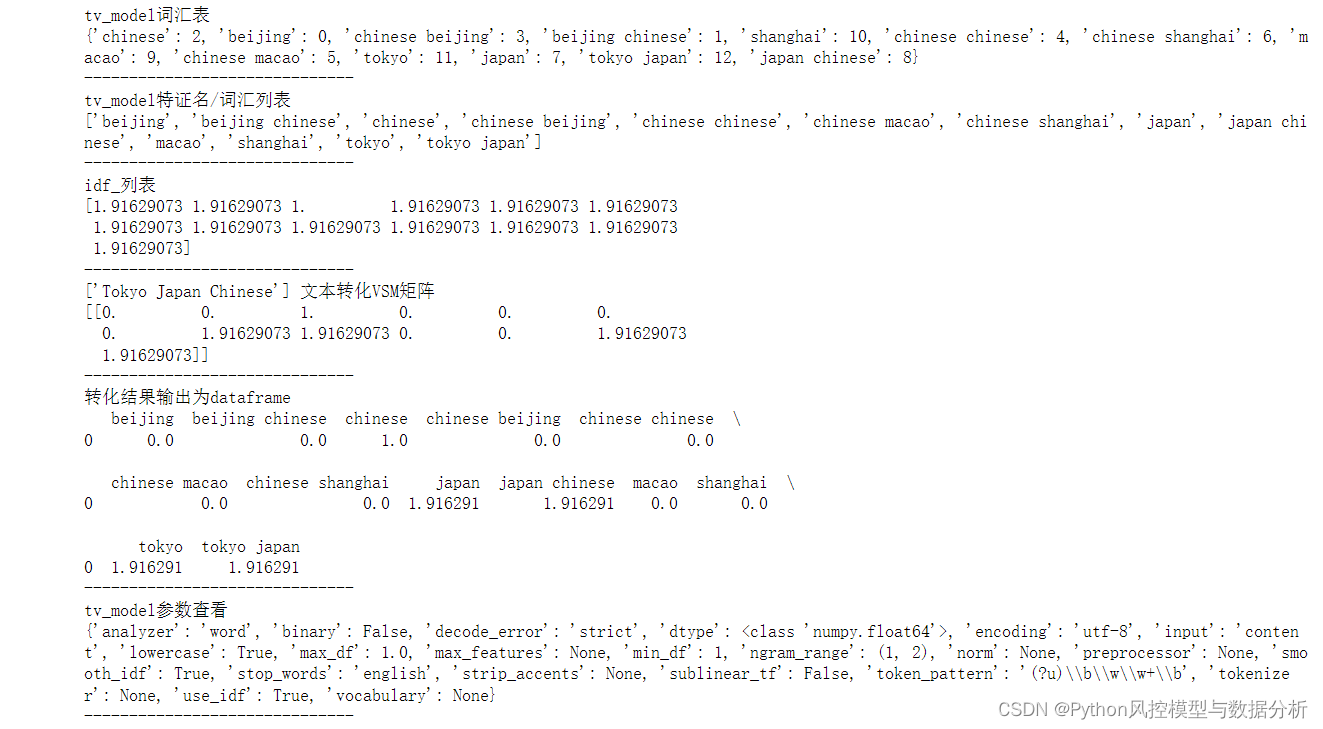
将train_data的tf-idf矩阵转化为dataframe结果
pd.DataFrame(tv_model.transform(train_data).toarray(),
columns=tv_model.get_feature_names())

三、划重点
少走10年弯路
**** ****关注公众号Python风控模型与数据分析,回复 tfidf实战 获取本篇的.py代码,不用动手直接调用、它不香吗?
还有更多理论、代码分享,没有任何保留的输出、不值得一个关注吗?
本文转载自: https://blog.csdn.net/a7303349/article/details/126575663
版权归原作者 Python风控模型与数据分析 所有, 如有侵权,请联系我们删除。
版权归原作者 Python风控模型与数据分析 所有, 如有侵权,请联系我们删除。