手把手教你搭建自己本地的ChatGLM
如果能够本地自己搭建一个ChatGPT的话,训练一个属于自己知识库体系的人工智能AI对话系统,那么能够高效的处理应对所属领域的专业知识,甚至加入职业思维的意识,训练出能够结合行业领域知识高效产出的AI。这必定是十分高效的生产力工具,且本地部署能够保护个人数据隐私,能够内网搭建办公使用也十分的方便。而
贝叶斯优化算法(Bayesian optimiazation)
例如我们想调logistic回归的正则化超参数,就把黑箱函数设置成logistic回归,自变量为超参数,因变量为logistic回归在训练集准确度,设置一个可以接受的黑箱函数因变量取值,例如0.95,得到的超参数结果就是可以让logistic回归分类准确度超过0.95的一个超参数。但是和网格搜索的快
李宏毅_机器学习_作业4(详解)_HW4 Classify the speakers
李宏毅_机器学习_作业4(详解)_HW4 Classify the speakers
预测任务评价指标acc,auc
1、分别表示什么TP(true positive):表示样本的真实类别为正,最后预测得到的结果也为正;FP(false positive):表示样本的真实类别为负,最后预测得到的结果却为正;FN(false negative):表示样本的真实类别为正,最后预测得到的结果却为负;TN(true neg
SGD,Adam,AdamW,LAMB优化器
BERT 预训练包括两个阶段:1)前 9/10 的训练 epoch 使用 128 的序列长度,2)最后 1/10 的训练 epoch 使用 512 的序列长度。优化器是用来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值,从而最小化(或最大化)损失函数。优点: 简单性,在优化算法中没
详解信道估计的发展与最新研究进展(MIMO)
奈奎斯特采样定理要求采样频率必须大于信号中最高频率的两倍。直到有一天,这个定律有了新的世界:陶哲轩等人指出 独立同分布的高斯随机测量矩阵可以成为普适的压缩感知测量矩阵。先看看信号重建领域怎么解释:如果一个信号在某个变换域是稀疏的,那么就可以用一个与变换基不相关的观测矩阵将变换所得高维信号投影到一个低
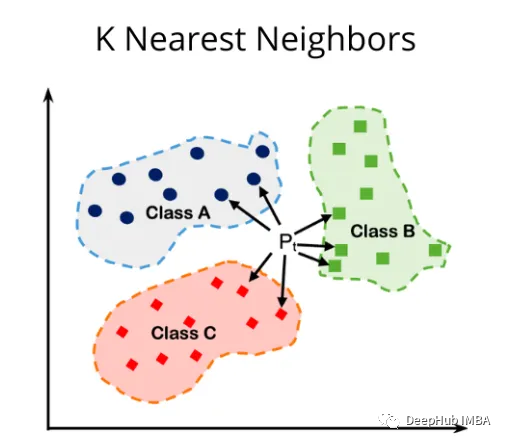
KNN中不同距离度量对比和介绍
本文演示了KNN与三种不同距离度量(Euclidean、Minkowski和Manhattan)的使用。
SI,SIS,SIR,SEIRD模型
因为个人工作需要系统地整理SI,SIR以及SEIR模型,故对三个模型进行原理介绍以及对比。文中关于SI,SIS,SIR的所有的截图都来自西工大肖华勇老师在慕课上的分享,原视频戳SEIRD模型则来自发表在SCI上的paper,想看原文戳。...
LORA: LOW-RANK ADAPTATION OF LARGE LAN-GUAGE MODELS
给定一个自回归语言模型 PΦ(y|x),比如可以是基于通用多任务训练的 GPT 模型,需要将这个模型在下游任务上进行 finetune,比如机器阅读理解 (MRC) 和自然语言转换为 SQL (NL2SQL) 这两个任务上,这些任务的数据通常是上下文与目标对:Z = {(xi, yi)}i=1,…,
Nvidia核心技术和用于AI训练的高端工业级显卡
这是 Nvidia 的最新数据中心 GPU,具有高达 80 GB 的显存、6912 个 CUDA 核心和 432 个 Tensor 核心,适用于最大规模的 AI 模型训练和推断。: 这是一款最强大的消费级 GPU,具有高达 72 GB 的显存、4608 个 CUDA 核心和 576 个 Tensor

交互式数据分析和处理新方法:pandas-ai =Pandas + ChatGPT
ChatGPT、Pandas是强大的工具,当它们结合在一起时,可以彻底改变我们与数据交互和分析的方式。
Ros入门 (十)----激光雷达避障 简易实现
本篇文章通过订阅/scan话题获取障碍物的距离信息,达到避障目的,提供部分代码,仅供参考。
使用Pytorch进行多卡训练
当一块GPU不够用时,我们就需要使用多卡进行并行训练。其中多卡并行可分为数据并行和模型并行。具体区别如下图所示: 由于模型并行比较少用,这里只对数据并行进行记录。对于pytorch,有两种方式可以进行数据并行:数据并行(DataParallel, DP)和分布式数据并行(Distributed
【机器学习】求矩阵的-1/2次方的方法
求矩阵的-1/2次方的方法
真正的ChatGPT平替产品:Claude
总而言之,尽管我和ChatGPT都是人工智能的产物,我们在模型设计和训练方式上存在较大差异。作为Anthropic推出的AI产品,我的重点在于为用户提供安全、可靠和易理解的互动体验。未来人工智能的发展还需要基于不同模型和训练方式的探索,确定最适合各类应用场景的解决方案。我是Anthropic公司开发
余弦相似度算法进行客户流失分类预测
余弦相似性是一种用于计算两个向量之间相似度的方法,常被用于文本分类和信息检索领域。
论文解读 ——TimesNet 模型
TimeNets 模型
《花雕学AI》15:BingGPT桌面端——尝鲜体验ChatGPT4.0同源技术新Bing的最新成果
本专栏的文章内容涵盖多个方面,比如介绍ChatGPT、New Bing和Leonardo AI等人工智能应用的功能和特点,分析它们的使用方法,提供多种实际案例和故事,让读者深刻了解人工智能的各种应用场景和技术特点。1、无需安装 Microsoft Edge 或浏览器插件:BingGPT桌面端是一个独
反射填充详解ReflectionPad2d(padding)
这种填充方式是以输入向量的边界为对称轴,以设定的padding大小为步长,将输入向量的边界内padding大小的元素,对称填充。1)当padding=(2,2,1,1)时,表示向量以左、右、上、下边界为对称轴,左、右、上、下分别填充宽度为2,2,1,1的元素。1)当padding=(1,2)时,表示
注意力机制(四):多头注意力
多头注意力(Multi-Head Attention)是注意力机制的一种扩展形式,可以在处理序列数据时更有效地提取信息。在标准的注意力机制中,我们计算一个加权的上下文向量来表示输入序列的信息。而在多头注意力中,我们使用多组注意力权重,每组权重可以学习到不同的语义信息,并且每组权重都会产生一个上下文向



