【AI大模型】讯飞版大模型来了!首发通用人工智能评测体系,现场发布四大行业应用成果
科大讯飞推出的新一代认知智能大模型,拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务。从海量数据和大规模知识中持续进化,实现从提出、规划到解决问题的全流程闭环。
深入理解机器学习——偏差(Bias)与方差(Variance)
即刻画了学习问题本身的难度。给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小一般来说,偏差与方差是有冲突的,这称为偏差方差窘境(Bias-Variance Dilemma)。随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的
强化学习——多智能体强化学习
文章目录前言多智能体系统的设定合作关系设定下的多智能体系统策略学习的目标函数合作关系下的多智能体策略学习算法MAC-A2C前言本文总结《深度强化学习》中的多智能体强化学习相关章节,如有错误,欢迎指出。多智能体系统的设定多智能体系统包含有多个智能体,多个智能体共享环境,智能体之间相互影响。一个智能体的
损失函数——交叉熵损失(Cross-entropy loss)
对于每个类别i,yi表示真实标签x属于第i个类别的概率,y^i表示模型预测x属于第i个类别的概率。对于每个输入数据x,我们定义一个C维的向量y^,其中y^i表示x属于第i个类别的概率。假设真实标签y是一个C维的向量,其中只有一个元素为1,其余元素为0,表示x属于第k个类别。该函数将输入数
强化学习分类与汇总介绍
强化学习分类与汇总介绍
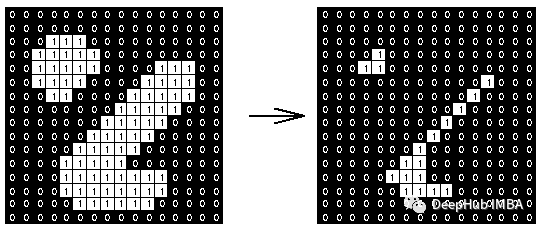
形态学运算与仿真:图像处理中形态学操作的简单解释
形态学是图像处理领域的一个分支,主要用于描述和处理图像中的形状和结构。形态学可以用于提取图像中的特征、消除噪声、改变图像的形状等。其中形态学的核心操作是形态学运算。
很佩服的一个Google大佬,离职了。。
除此之外,他的高曾祖父George Boole还是著名的逻辑学家,也是现代计算科学的基础布尔代数的发明人,而他的叔叔Colin Clark则是一个著名的经济学家。除此之外,Hinton在他的学术生涯中发表了数百篇论文,这些论文中提出了许多重要的理论和方法,涵盖了人工智能、机器学习、神经网络、计算机视
gpt.4.0-gpt 国内版
GPT(Generative Pre-trained Transformer)是一种预训练的语言模型,可用于多种自然语言处理任务,如情感分析、文本分类、文本生成等。下面是使用GPT的一些步骤和建议:确定任务和数据集:首先,需明确自己的任务和应用场景,选择合适的数据集进行训练和测试。例如,如果要生成诗
深度学习的定义和未来发展趋势
深度学习的定义及原理📜📜深度学习是一种基于神经网络、具有多个隐藏层来提取高级抽象特征进行模式识别和决策的机器学习技术。其核心思想与人脑神经元相似,通过逐层的计算和学习,将输入数据转化为具有更高级别的表示,从而实现对复杂数据结构的建模和分析。📜深度学习中最重要的思想是构建可训练的人工神经网络模型
ChatGPT重量级对手产品:Claude对外发布
什么是ClaudeClaude是下一代人工智能助手,基于 Anthropic 对训练有用、诚实和无害的人工智能系统的研究。Claude 可通过我们的开发人员控制台中的聊天界面和 API 进行访问,能够执行各种对话和文本处理任务,同时保持高度的可靠性和可预测性。克劳德可以帮助处理总结、搜索、创意和协作
前沿探索,AI 在 API 开发测试中的应用
Apikit 是结合 API 设计、文档管理、自动化测试、监控、研发管理和团队协作的一站式 API 生产平台,可以快速、规范地管理所有 API,已经成为当前 API 研发管理的主流产品。
【五一创作】自动驾驶技术未来大有可为
自动驾驶技术是指通过计算机技术和各种传感器,使得汽车可以在不需要人类干预的情况下完成行驶任务。这项技术在近年来得到了快速的发展,并在汽车制造业、城市规划和交通管理等领域引起了广泛的关注和讨论。传感器技术、计算机视觉技术和人工智能技术。
激活函数ReLU和SiLU的区别
在这里,我就简单写一下两个激活函数的概念以及区别,详细的过程可以看看其他优秀的博主,他们写的已经非常好了,我就不必再啰嗦了
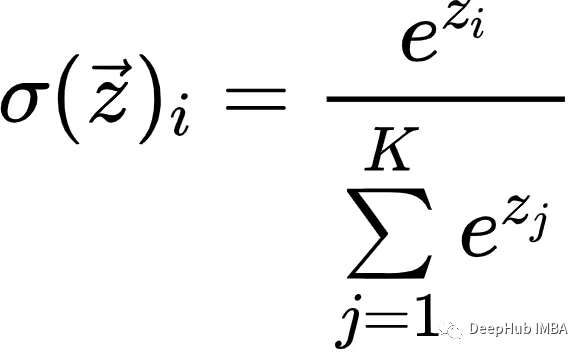
Softmax简介
Softmax是一种数学函数,通常用于将一组任意实数转换为表示概率分布的实数。
gpt模型训练-gpt3模型详解
目前,GPT-3已经成为最流行、最常用的GPT模型,它集成了1750亿个参数,能够执行一系列的自然语言处理任务,包括翻译、问答、文本摘要、对话生成等。具体而言,GPT模型将Transformer中的编码器部分作为自己的网络架构,实现了一个多层的、自回归的语言模型。总之,GPT模型是一种强大的、通用的
Prompt Engineering 入门(一)
大语言模型 (LLM) 是一种基于Transformer的深度学习模型,可以处理大量的自然语言文本,并从中学习知识和语言规律,从而提高对自然语言的理解和生成能力。LLM可以用于各种自然语言处理 (NLP)任务,如文本生成、阅读理解、常识推理等,这些任务在传统的方法下很难实现。LLM还可以帮助开发人员
人工智能实践: 基于T-S 模型的模糊推理
模糊推理是一种基于行为的仿生推理方法, 主要用来解决带有模糊现象的复杂推理问题。由于模糊现象的普遍存在, 模糊推理系统被广泛的应用。模糊推理系统主要由模糊化、模糊规则库、模糊推理方法以及去模糊化组成, 其基本流程如图1所示。■ 图1 模糊推理流程图传统的模糊推理是一种基于规则的控制, 它通过语言表
狂追ChatGPT:开源社区的“平替”热潮
目前,不少优质的类ChatGPT模型都只能通过API接入,而一些开源LLM的效果与ChatGPT相比差距不小。不过,近期开源社区开始密集发力了。其中,Meta的LLaMA模型泄漏是开源“ChatGPT”运动的代表性事件。基于LLaMA模型,开源社区近期接连发布了ChatLLaMa、Alpaca、Vi
玩转ChatGPT:文献总结工具
玩转ChatGPT:文献总结工具
Python实现逻辑回归(Logistic Regression)
逻辑回归是一种经典机器学习分类算法,它被广泛应用于二元分类问题中,该算法的目的是预测二元输出变量(比如0和1),逻辑回归算法有很多应用,比如预测股票市场、客户购买行为、疾病诊断等等。它被广泛应用于医学、金融、社交网络、搜索引擎等各个领域。



