
码字不易,如果各位看官感觉该文章对你有所帮助,麻烦点个关注,如果有任何问题,请留言交流。如需转载,请注明出处,谢谢。
文章链接:https://blog.csdn.net/herocheney/article/details/118300553
一、深度学习的数据
在深度学习或机器学习的过程中,数据无疑是驱动模型的主要能量,通过训练现有数据,得到相应的网络参数,使得我们所设计的模型具有泛化性,能够预测一些未知的,没有出现的样本,并将该参数应用到实际当中,是模型训练的主要流程,数据的干净程度,完备程度等,是网络学习好坏的重中之重。

二、训练集、测试集和验证集
我们通常把训练的数据分为三个文件夹:**训练集、测试集和验证集**。
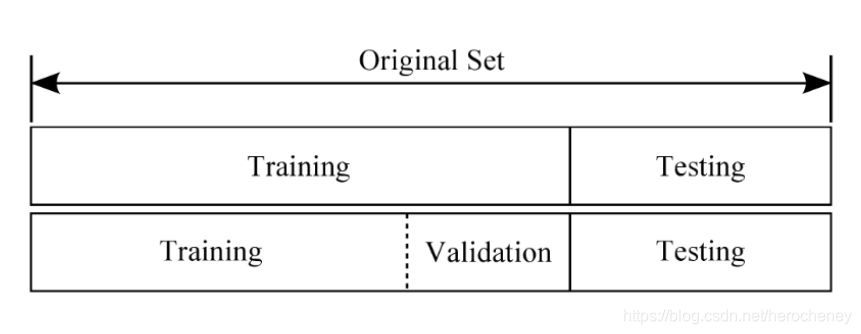
下面这个比喻非常恰当:模型的训练与学习,类似于老师教学生学知识的过程。
1、训练集(train set):用于训练模型以及确定参数。相当于老师教学生知识的过程。
2、验证集(validation set):用于确定网络结构以及调整模型的超参数。相当于月考等小测验,用于学生对学习的查漏补缺。
3、测试集(test set):用于检验模型的泛化能力。相当于大考,上战场一样,真正的去检验学生的学习效果。
参数(parameters)是指由模型通过学习得到的变量,如权重和偏置
。
超参数(hyperparameters)是指根据经验进行设定的参数,如迭代次数,隐层的层数,每层神经元的个数,学习率等。
三、训练集、测试集和验证集的比例
根据吴恩达的视频所述,如果当数据量不是很大的时候(万级别以下)的时候将训练集、验证集以及测试集划分为6:2:2;若是数据很大,可以将训练集、验证集、测试集比例调整为98:1:1。
本文转载自: https://blog.csdn.net/herocheney/article/details/118300553
版权归原作者 莫克_Cheney 所有, 如有侵权,请联系我们删除。
版权归原作者 莫克_Cheney 所有, 如有侵权,请联系我们删除。