
条件随机场(CRF)由Lafferty等人于2001年提出,结合了最大熵模型和隐马尔可夫模型的特点,是一种无向图模型,常用于标注或分析序列资料,如自然语言文字或是生物序列。近年来在分词、词性标注和命名实体识别等序列标注任务中取得了很好的效果。
条件随机场是一类最适合预测任务的判别模型,其中相邻的上下文信息或状态会影响当前预测。CRF 在命名实体识别、词性标注、基因预测、降噪和对象检测问题等方面都有应用。
在本文中首先,将介绍与马尔可夫随机场相关的基本数学和术语,马尔可夫随机场是建立在 CRF 之上的抽象。然后,将详细介绍并解释一个简单的条件随机场模型,该模型将说明为什么它们非常适合顺序预测问题。之后,将在 CRF 模型的背景下讨论似然最大化问题和相关推导。最后,还有一个过对手写识别任务的训练和推理来演示 CRF 模型。
马尔可夫随机场
马尔可夫随机场(Markov Random Field)或马尔可夫网络( Markov Network)是一类在随机变量之间具有无向图的图形模型。该图的结构决定了随机变量之间的相关性或独立性。
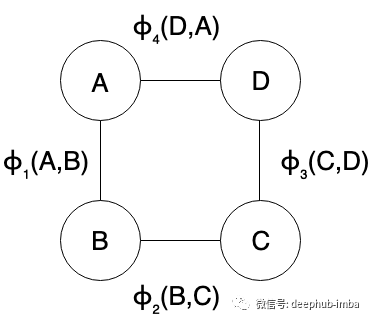
马尔可夫网络由图 G = (V, E) 表示,其中顶点或节点表示随机变量,边表示这些变量之间的依赖关系。
该图可以分解为 J 个不同的团(小的集团 cliques )或因子(factors),每个由因子函数 φⱼ 支配,其范围是随机变量 Dⱼ 的子集。对于 dⱼ 的所有可能值,φⱼ (dⱼ) 应该严格为正。
对于要表示为因子或团的随机变量的子集,它们都应该在图中相互连接。所有团的范围的并集应该等于图中存在的所有节点。
变量的非归一化联合概率是所有因子函数的乘积,即 对于上面显示的 V = (A, B, C, D) 的 MRF,联合概率可以写为:

分母是每个变量可能取的所有可能的因子乘积的总和。它是一个常数表示,也称为配分函数,通常用Z。
Gibbs Notation
还可以通过对对数空间中的因子函数进行操作,将关节表示为Gibbs 分布。使用 β (dⱼ) = log (ϕ (dⱼ)),可以用 Gibbs 表示法表示共同的边,如下所示。X 是图中所有随机变量的集合。β 函数也称为factor potentials。

这个公式很重要,因为本文将在后面使用 Gibbs 符号来推导似然最大化问题。
条件随机场模型
让我们假设一个马尔可夫随机场并将其分为两组随机变量 Y 和 X。
条件随机场是马尔可夫随机场的一个特例,其中图满足以下属性:“当我们在 X 全局条件下,即 当X中随机变量的值固定或给定时,集合Y中的所有随机变量都遵循马尔可夫性质p(Yᵤ/X,Yᵥ,u≠v)=p(Yᵤ/X,Yₓ,Yᵤ~Yₓ ),其中 Yᵤ ~ Yₓ 表示 Yᵤ 和 Yₓ 是图中的邻居。” 变量的相邻节点或变量也称为该变量的马尔可夫毯(MarkovBlanket)。
满足上述属性的一个这样的图是下面共享的链结构图:
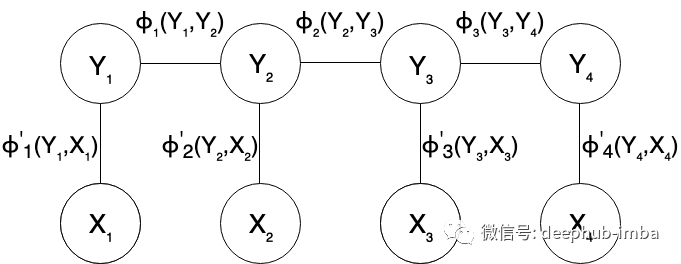
由于 CRF 是一个判别模型,即 它对条件概率 P (Y / X) 进行建模,即 X 总是给出或观察到。因此,该图最终简化为一条简单的链。
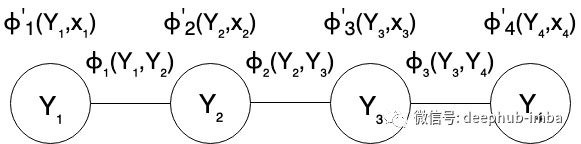
当我们以 X 为条件并试图为每个 Xᵢ 找到相应的 Yᵢ 时,X 和 Y 也分别称为证据变量和标签变量。
验证上面显示的“因子缩减”CRF模型符合下面为可变Y₂所示的马尔可夫属性。由此可见,给定所有其他变量的Y₂的条件概率最终只取决于相邻节点。
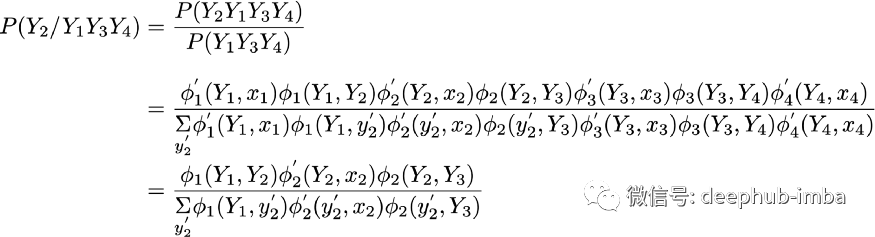
满足马尔可夫性质的变量 Y₂,条件仅取决于相邻变量
CRF 理论和似然优化
让我们首先定义参数,然后使用 Gibbs 表示法建立联合(和条件)概率的方程。
- Label domain:假设集合 Y 中的随机变量有一个域:{m ϵ ℕ | 1≤m≤M}即前 M 个自然数。
- Evidence structure and domain:假设集合 X 中的随机变量是大小为 F 的实值向量,即∀ Xᵢ ϵ X, Xᵢ ϵ Rˢ。
- 设 CRF 链的长度为 L,即L 个标签和 L 个证据变量。
- 令 βᵢ (Yᵢ, Yⱼ) = Wcc '如果 Yᵢ = c, Yⱼ = c' 并且 j = i + 1, 否则为 0。
- 令 β'ᵢ (Yᵢ, Xᵢ) = W'c。Xᵢ,如果 Yᵢ = c,否则为 0,其中。表示点积,即W’c ε Rˢ。
- 请注意,参数的总数是 M x M + M x S,即每个标签转换有一个参数(M x M 个可能的标签转换)和每个标签(M 个可能的标签)的 S 个参数,这些参数将乘以该标签处的观察变量(大小为 S 的向量)。
- 令 D = {(xn, yn)} for n = 1 to N,为由 N 个示例组成的训练数据。
其中似然表达式可以表示如下:

所以训练问题归结为最大化所有模型参数 Wcc'和 W'cs 的对数似然。
关于 W'cs 的对数似然梯度推导如下:-

上面等式中的第二项表示y'ᵢ等于c的边际概率之和(在y'可以取的所有可能值上),由xnis加权。y'-i 这里表示除位置 i 之外每个位置的标签 / y 变量的集合。
可以为 dL / dWcc '计算出类似的推导,结果如下:
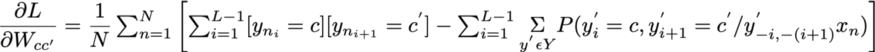
这就是标签-标签权重的似然导数
现在已经有了导数和对数似然的表达式,实际上就可以从头开始编写 CRF 模型。可以使用上面提到的方程进行编码,使用置信传播来计算边际并计算出导数,然后使用现成的优化算法(如 L-BFGS)优化。
但是为了简单起见,我们不会重新发明轮子,我们使用使用现有的 CRFSuite 库进行演示。
演示 - 手写识别
到目前为止,应该相当清楚 CRF 的结构为什么以及如何使它们成为捕获顺序关系的任务的理想选择,例如 POS 标记句子、命名实体识别等。在这个本文中将使用 CRF 进行笔迹检测任务。
为了准备这个演示的数据集,使用了斯坦福 OCR 数据集和Gutenberg项目存档的组合。
数据集准备
斯坦福 OCR 数据集总共包含 6877 个手写单词,分为 9 折。每个单词的第一个字符都不是小写字符。对于每个单词中的每个手写字符,数据集包含一个长度为 128 的二进制数组,可以将其转换为大小为 16x8 的图像。数据集中的一些单词可视化结果如下:-

经过分析,我发现整个数据集中的唯一词数量只有 24 个。
我们希望 CRF 模型能够学习标记观察值 (xᵢ),这些观察结果是同时出现的字符像素向量。尽管就字符像素向量而言,数据集中有 6,877 个独特的样本,对于 24 个单词组合来说数据量非常的小,可能无法以概率的方式捕捉一般英语中的字符共现和进行单词识别器。
为了解决这个问题,我决定使用所有字符向量表示来创建一个新的数据集。我为字典中的每个字符捕获了数据集中可用的所有不同字符像素向量变体。在完成后,导入了名著《白鲸记》中出现的所有单词,并过滤掉所有长度小于 3 或包含字母集以外的内容,然后将过滤后的标记转换为小写。这种方式总共提取了 18,859 个单词,然后按词长分成训练集和测试集,。
为了构成 CRF 模型的实际训练和测试集,我使用了我一开始创建的字符到像素数组矢量图。为了创建单词图像 / x,我使用统一采样从字典中为该字符挑选了一个像素数组向量变体。创建的数据集的结果如下:

训练和测试数据集准备好后,就可以训练模型并根据任务对其进行评估了。
模型训练与评估
这里只粘贴主要代码,全部代码请看最后:
def train_model(X, Y, max_iter_count, model_store = "handwriting-reco.crfsuite"):
trainer = pycrfsuite.Trainer(verbose=False)
for xseq, yseq in zip(X, Y):
trainer.append(xseq, yseq)
trainer.set_params({
'c1': 1.0, # coefficient for L1 penalty
'c2': 1e-3, # coefficient for L2 penalty
'max_iterations': max_iter_count, # stop earlier
# include transitions that are possible, but not observed
'feature.possible_transitions': True
})
trainer.train(model_store)
print(trainer.logparser.last_iteration)
def get_preds(X, model_store = "handwriting-reco.crfsuite"):
tagger = pycrfsuite.Tagger()
tagger.open(model_store)
Y_pred = [tagger.tag(x) for x in X]
return Y_pred
def test_model(X_test, Y_test):
Y_test_pred = get_preds(X_test)
lb = LabelBinarizer()
y_test_combined = lb.fit_transform(list(chain.from_iterable(Y_test)))
y_pred_combined = lb.transform(list(chain.from_iterable(Y_test_pred)))
print "Test accuracy : {}".format(accuracy_score(y_test_combined, y_pred_combined))
使用上面的脚本,我在包含15088个单词的训练集上训练了一个CRF模型,在测试集上达到了接近85%的准确率,看样子还是很不错的。
CRF 与隐马尔可夫模型有何不同
机器学习模型有两个常见的分类,生成式和判别式。条件随机场是一种判别分类器,它对不同类之间的决策边界进行建模。而生成模型是建立数据如何生成的模型,在学习后可用于进行分类。举个简单的例子,朴素贝叶斯是一种非常简单且流行的概率分类器,是一种生成算法,而逻辑回归是一种基于最大似然估计的分类器,是一种判别模型,同理条件随机场也是。
CRF 与隐马尔可夫模型都用于对顺序数据进行建模,但它们是不同的算法。
隐马尔可夫模型是生成式的,它通过对联合概率分布建模来给出输出。而条件随机场具有判别性,对条件概率分布进行建模。CRF 不依赖独立性假设(即标签相互独立),并且避免标签偏差。隐马尔可夫模型是条件随机场的一个非常具体的例子,使用的转移概率是一个常数。hmm基于朴素贝叶斯(Naive Bayes),说朴素贝叶斯可以从逻辑回归(Logistic Regression)中导出,而逻辑回归是crf的衍生。
CRF 的应用
由于crf具有对顺序数据建模的能力,因此在自然语言处理中经常使用crf,并且在该领域有许多应用。例如词性标记,句子的词性依赖于先前的单词,通过使用利用这一点的特征函数,可以使用 CRF 来学习如何区分句子中的哪些词对应于哪个 POS。另一个类似的应用是命名实体识别,或从句子中提取专有名词。条件随机场可用于预测多个变量相互依赖的任何序列。其他应用包括图像中的部分识别和基因预测。
代码:
数据预处理
https://gist.github.com/adiprasad/8125e2bc68f167eda965571e15fb2948#file-stanford_ocr_nltk-ipynb
训练
https://gist.github.com/adiprasad/6305306e9ea55732e38c038880742b4c#file-crf-model-prediction-ipynb
作者:Aditya Prasad & Ravish Chawla