
Aeon 是一个专注于时间序列处理的开源Python库,其设计理念遵循scikit-learn的API风格,为数据科学家和研究人员提供了一套完整的时间序列分析工具。该项目保持活跃开发,截至2024年仍持续更新。
Aeon提供了以下主要功能模块:
- 时间序列分类- 支持多种分类算法实现- 包含基于间隔、字典和距离的分类器- 提供集成学习方法
- 时间序列回归分析- 支持各类回归模型- 提供预测区间估计- 包含模型评估工具
- 时间序列聚类- 实现了多种聚类算法- 支持自定义距离度量- 提供聚类结果可视化
- 预测建模- 包含多种预测模型实现- 支持单变量和多变量预测- 提供预测性能评估工具
- 数据转换与预处理- 提供多种数据转换方法- 支持时间序列特征提取- 包含数据标准化工具
技术特点
- API设计- 采用scikit-learn风格的API设计- 提供统一的fit/predict接口- 支持管道(Pipeline)操作
- 可视化支持- 内置多种可视化工具- 支持时间序列数据探索- 提供聚类和分类结果展示
- 数据兼容性- 与pandas数据结构深度集成- 支持多种数据格式输入- 需注意与pandas版本的兼容性要求
技术兼容性说明:经验证,Aeon目前仅与Pandas 1.4.0版本完全兼容。由于Pandas新版本对索引API进行了重构,可能导致与部分时间序列处理功能产生兼容性问题。
虽然在可视化方面提供了良好的基础功能,但相比Matplotlib等专业可视化库,其灵活性仍有一定限制。以下将通过具体示例,展示Aeon在各个功能模块的实际应用。
Aeon时间序列可视化功能分析
Aeon提供了一套用于探索性数据分析的可视化工具集。以下将展示其基础线图绘制功能。
"""
Aeon时间序列可视化示例
演示Aeon内置的探索性数据分析可视化工具
基础线图绘制
"""
from aeon.datasets import load_airline
from aeon.visualisation import plot_series
%matplotlib inline
# 航空客运量数据集
y = load_airline()
plot_series(y, title="Airline Passenger Numbers")
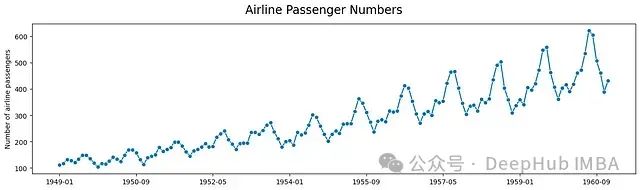
从效果来看,虽然没有特别出众的特点,但绘图结果清晰实用。
时间序列聚类与分类技术实现
在实际应用中,部分时间序列数据遵循特定的模式规律,但对这些序列的模式归类往往具有一定难度。面对随机信号时,如何将其与具有相似特征的信号进行准确分类就成为一个关键问题。
在这种场景下,聚类算法可以提供有效的解决方案。以下示例代码将生成50个随机样本,这些样本分别遵循三种基本模式(正弦函数、余弦函数或2倍频率的正弦函数)。通过Aeon我们可以利用k最近邻算法对这些样本进行模式分类。这种方法能够有效地将不同序列划分到相应的类别中,便于后续对特定类别进行深入分析。若不进行聚类处理,这些序列叠加在一起会呈现出噪声状态,不利于进一步分析。
"""
时间序列聚类实现
基于K-means算法的时间序列分组示例
"""
importnumpyasnp
importmatplotlib.pyplotasplt
fromaeon.clusteringimportTimeSeriesKMeans
defmake_example_dataset(n_samples=50, n_timepoints=30, random_state=42):
np.random.seed(random_state)
# Generate three different patterns
t=np.linspace(0, 2*np.pi, n_timepoints)
patterns= [
lambda: np.sin(t),
lambda: np.cos(t),
lambda: 0.5*np.sin(2*t)
]
X= []
for_inrange(n_samples):
# Randomly choose a pattern function
pattern_func=np.random.choice(patterns)
# Generate the pattern and add some noise
series=pattern_func() +np.random.normal(0, 0.1, n_timepoints)
X.append(series)
returnnp.array(X)
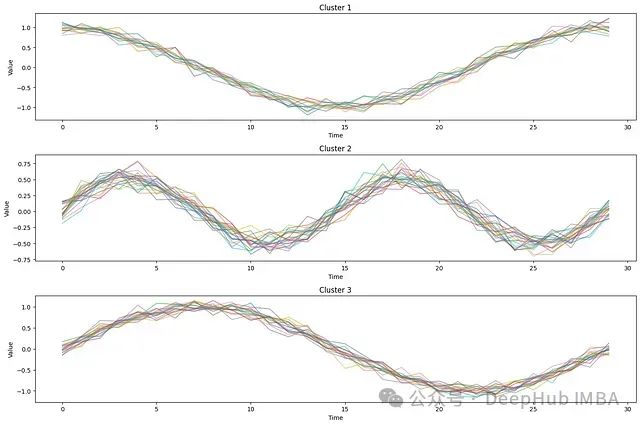
相比前述航空客运量数据集的线图,这组聚类可视化结果展现出更为优秀的图形效果。
利用已获得的类别标签,我们可以进一步通过Aeon的分类器进行数据分类。由于使用的是模拟数据集,算法呈现出的完美分类效果在预期之内。
from aeon.classification.interval_based import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# Initialize and train a classifier
clf = TimeSeriesForestClassifier(random_state=42)
clf.fit(X_train, y_train)
# Make predictions
y_pred = clf.predict(X_test)
# Calculate accuracy
accuracy = np.mean(y_pred == y_test)
print(f"Accuracy: {accuracy:.2f}")
# Print some information about the data
print(f"\nData shape: {X.shape}")
print(f"Number of classes: {len(np.unique(labels))}")
print(f"Class distribution: {np.bincount(labels)}")
实验结果
Accuracy: 1.00
Data shape: (50, 30)
Number of classes: 3
Class distribution: [13 21 16]
需要说明的是,尽管Aeon文档中提到了'ETSForecaster'功能模块,但在实际测试中未能成功运行该模块。
总结
Aeon作为一个时间序列分析工具,在基础功能实现和易用性方面表现良好,特别适合用于数据探索和基础分析任务。虽然在某些高级功能和性能优化方面还有提升空间,但其简洁的API设计和完整的基础功能仍使其成为时间序列分析的有效工具选项。建议根据具体项目需求,合理评估其适用性,必要时可与其他专业工具配合使用,以获得最佳的分析效果。
作者:Kyle Jones