
扩散模型已成为现代文本到图像 (T2I) 生成技术的核心,能够生成高质量图像,但其迭代式推理过程导致生成速度缓慢。多数模型通常需要 20–50 个去噪步骤,这严重制约了其在实时应用中的部署。
现有的蒸馏技术旨在加速扩散模型的采样过程,然而,这些方法往往会引入稳定性问题,在极低步数下出现质量下降,并可能导致显著的内存需求。

Nvidia 提出的 SANA-Sprint 是一种混合蒸馏框架,它整合了连续时间一致性模型 (sCM) 和 **潜在对抗扩散蒸馏 (LADD)**,旨在实现以下目标:
- 无步训练,并支持灵活的 1–4 步推理。
- 卓越的速度与质量平衡,单步推理即可达到 FID 7.59 和 GenEval 0.74 的指标。
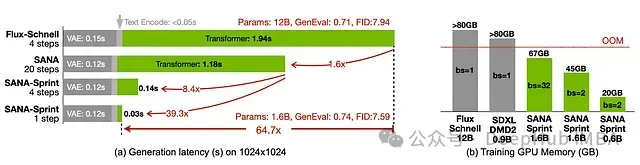
- 在 H100 GPU 上实现 0.1 秒生成 1024×1024 图像,速度比 FLUX-Schnell 快 10 倍,同时保持更高图像质量。
本文将深入探讨 SANA-Sprint 实现上述性能的技术原理。
传统蒸馏方法在超低步数推理中的局限性
扩散模型依赖于随机微分方程 (SDE) 或常微分方程 (ODE) 进行图像生成,该过程通常需要多个步骤。尽管存在多种步数缩减技术,但每种方法都存在其固有的局限性:
- 基于 GAN 的蒸馏方法(例如,LADD) 可以加速推理过程,但容易遭受模式崩溃和泛化能力不足的问题。
- 一致性模型 (CM) 能够实现快速采样,但在超低步数 (少于 4 步) 的情况下,由于轨迹截断误差,语义对齐性能会显著下降。
- 变分分数蒸馏 (VSD) 需要额外训练辅助扩散模型,这会显著增加 GPU 内存占用和计算开销。
SANA-Sprint 通过整合 sCM 和 LADD 到统一框架中,克服了上述挑战,从而在确保快速推理的同时,实现了高图像质量。
基于无训练一致性变换的预训练模型重用
扩散模型通常采用流匹配或基于分数的学习方法进行训练,而一致性模型 (CM) 则基于 TrigFlow 参数化。为了实现无需重新训练的快速蒸馏,SANA-Sprint 引入了一种数学变换,可以将预训练的流匹配模型转化为 TrigFlow 模型。
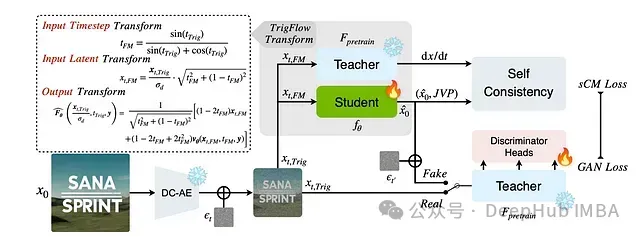
该变换确保了以下关键特性:
- 时域映射的无缝衔接:实现了从 流匹配模型的 [0,1] 区间 到 TrigFlow 模型的 [0, π/2] 区间 的平滑转换。
- 信噪比 (SNR) 的一致性:在模型适配过程中,保持了信噪比的稳定,确保图像保真度。
- 模型输出的正确参数化:保证了转换后模型输出的速度场与 TrigFlow 框架的公式保持一致。
通过上述变换,预训练模型可以直接应用于 SANA-Sprint 框架,无需额外的重新训练,从而显著提升了效率。
解决大规模一致性模型训练不稳定性问题
将一致性模型扩展到更高分辨率和更大模型规模时,常常会面临训练不稳定性的挑战,这主要是由于梯度爆炸现象引起的。SANA-Sprint 通过以下两项关键技术来稳定训练过程:
密集时间嵌入以抑制梯度爆炸
- 传统扩散模型通常使用乘法因子(例如,
1000 * t)来缩放时间嵌入,这种方法会放大时间导数梯度,容易导致训练崩溃。 - SANA-Sprint 采用归一化时间嵌入方法,确保时间步长表示的均匀分布,从而有效提升训练稳定性和样本质量。
- 这种方法使得模型能够更快收敛,并生成更清晰锐利的图像。
QK 归一化实现稳定的自注意力和交叉注意力机制
- 随着模型规模的扩大 (参数量从 0.6B 增至 1.6B),梯度范数变得不稳定 ( >¹⁰³),导致训练失败。
- SANA-Sprint 在注意力层的 Query 和 Key (QK) 组件中引入 RMS 归一化,在不改变模型架构的前提下,有效稳定了梯度。
- 仅需 5,000 次微调迭代,即可显著降低训练不稳定性,从而为大规模扩散模型的稳定蒸馏奠定基础。
结合一致性模型与对抗监督
传统一致性模型主要依赖局部轨迹学习,这导致其收敛速度较慢,并且在单步生成中容易丢失细节信息。SANA-Sprint 通过引入 基于 GAN 的对抗监督机制 (LADD) (Latent Adversarial Diffusion Distillation),对一致性模型进行了增强:
- 使用冻结的教师模型提取高层潜在空间表征,以强制模型学习数据分布的一致性。
- 引入多头判别器学习特征层面的差异,避免了像素空间直接比对可能导致的问题。
- 采用 铰链损失函数,提升了训练稳定性和生成样本的真实感。
该技术显著提升了单步图像生成质量,有效保留了传统一致性模型难以捕捉的高频细节。
评估与结果

SANA-Sprint 在速度和质量方面均达到了新的技术水平。相较于 FLUX-Schnell,SANA-Sprint 的推理速度提升了 10 倍,同时能够生成更高质量的图像。在单步推理下,SANA-Sprint 取得了 7.59 的 FID 值和 0.74 的 GenEval 值,性能超越了需要多步推理的模型。即使在 RTX 4090 等消费级 GPU 上,SANA-Sprint 也能在 0.31 秒内生成 1024×1024 像素的图像,使得高质量 AI 图像生成技术更加普及。在 H100 GPU 上,文本到图像生成仅需 0.1 秒,ControlNet 任务耗时 0.25 秒,实现了近乎实时的视觉反馈。
总结
与需要 20 步以上的传统扩散模型不同,SANA-Sprint 仅需 1-4 步即可生成高质量图像,且无需额外的训练过程。单步推理速度极快,非常适合实时应用场景。两步生成能够在保证速度 (低于 0.25 秒) 的前提下,有效提升图像细节。四步生成则在质量和效率之间实现了最佳平衡。
该论文在数学原理上具有一定的复杂性,但其技术方案堪称杰出,非常值得深入阅读和研究。SANA-Sprint 的工作有望推动 Flow Matching DiT 模型的下游优化,进而实现更快、更低成本的图像生成。
蒸馏推理技术的进步,使得高质量图像生成技术更加普惠化。
https://arxiv.org/pdf/2503.09641
https://github.com/NVlabs/Sana
作者:Pietro Bolcato