
本文探讨GoT框架如何通过语义-空间思维链方法提升图像生成的精确性与一致性
计算机视觉领域正经历一次技术革新:一种不仅能将文本转换为图像,还能在生成过程中实施结构化推理的系统。这一系统即为GoT(Generative Thoughts of Thinking,生成式思维链)框架——一种将显式推理机制引入图像生成与编辑领域的创新架构。本文将深入分析GoT的技术原理,详细探讨其架构设计,并评估其在实际应用中的表现。
传统文本到图像系统通常采用直接映射方式,将文本提示转换为视觉内容。这种方法对于简单场景能够取得良好效果,但在处理包含多个对象或复杂空间排列的场景时存在明显局限。GoT框架通过引入"思维链"机制突破了这一限制,该机制在生成图像前会展开结构化推理过程。
此推理过程主要包含两个核心环节:
- 语义推理:将文本提示系统性地分解为对象描述、属性特征和关系逻辑的详细表征。
- 空间推理:为场景中的每个元素分配精确坐标,确保最终图像在空间布局上具有逻辑一致性。
通过整合这两种推理能力,GoT系统实现了类人的场景构思过程,从而生成在视觉质量和逻辑结构上均具备高水平一致性的图像。
GoT范式:基于逐步推理的图像生成方法
GoT的核心技术优势在于利用多模态语言模型的思维链推理能力,将简洁文本提示转化为结构化的生成计划。
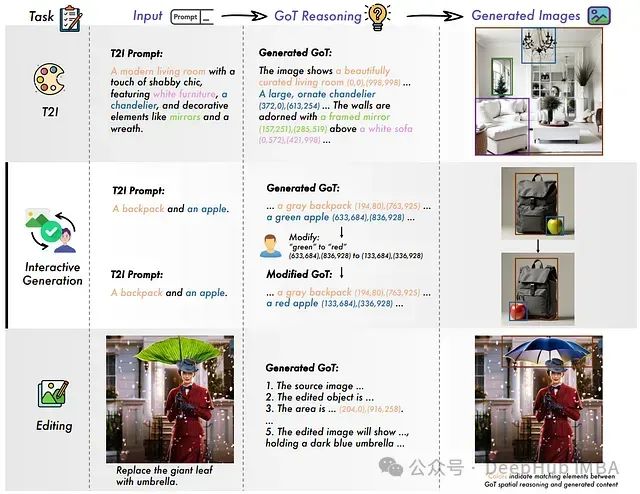
具有语义-空间推理的生成式思维链:此图说明了如何将简单的文本提示转换为详细的推理链,其中包括语义描述和空间坐标。在左侧,输入提示被扩展为逐步计划。在中间,每个步骤都通过精确的坐标进行丰富。在右侧,最终图像反映了详细的计划。
此过程可分解为以下技术环节:
1、文本分析与扩展
系统首先对输入文本提示进行语义解析,将其扩展为结构化描述。例如,"一个具有飞行汽车的未来城市景观"这样的提示会被转换为详细的场景描述,其中不仅明确指定各类对象(建筑物、交通工具),还包括它们的属性特征(颜色、尺寸)及空间位置关系。
2、语义-空间推理
系统为每个识别的对象分配精确坐标参数。例如,系统会确定建筑物在画布中的具体位置范围(如坐标点(100,200)至(400,800))。这种语义内容与空间信息的双重映射构成了GoT框架的核心技术优势。
3、引导式图像生成
完成推理链构建后,系统将这些结构化信息传递给基于扩散模型的图像生成器。与传统生成模型不同,GoT的生成过程受到详细语义描述和空间布局的双重约束,从而确保生成图像的精确性和美学质量。
数据基础:GoT专用数据集的构建与特点
为训练具备深度推理能力的GoT模型,研究团队构建了迄今为止图像生成领域最为全面的专用数据集之一。
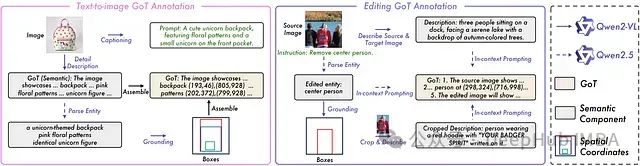
GoT数据集构建过程:在此图中,左侧面板显示了文本到图像的流程:简短的提示如何扩展为详细的语义和空间推理链。右侧面板侧重于图像编辑流程,突出显示了源图像和编辑指令如何被处理成连贯的逐步推理序列。
该数据集包含以下关键组成部分:
1、文本到图像生成样本
数据集包含超过900万个样本,来源于Laion-Aesthetics、JourneyDB和FLUX等高质量视觉数据库。每个样本均配有详尽的推理链注释,将简洁提示与详细描述(通常超过800字符)及空间坐标信息相关联。
2、图像编辑样本
数据集同时包含单轮和多轮编辑数据,完整记录了图像修改过程。这些数据包含明确的编辑指令、精确的边界框标注以及顺序化的推理链,详细记录了从原始图像到目标图像的转换逻辑。
数据集构建过程采用了Qwen2-VL和Qwen2.5等先进模型进行自动化生成、优化和验证,确保每个训练样本都具备高度的详细性和准确性。
技术架构:统一的推理与生成框架
GoT的技术优势源于其创新架构,该架构有效结合了大型语言模型的推理能力与扩散模型的图像合成精度。
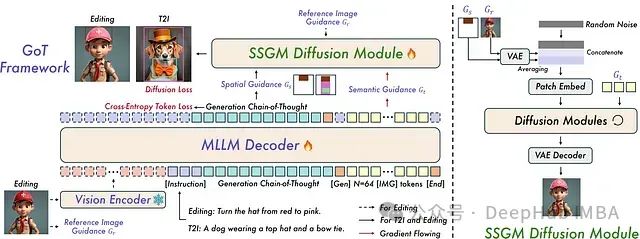
具有语义-空间指导的GoT框架: 在此图中,**左侧部分显示了整体框架,其中MLLM生成推理链并将其馈送到扩散模型。右侧部分**放大了SSGM,显示了如何组合语义、空间和参考指导以生成高保真图像。
框架的核心组件包括:
1、语义-空间多模态语言模型(MLLM)
基础模型:
GoT采用Qwen2.5-VL-3B作为基础模型,该模型在视觉和文本数据的综合理解方面表现卓越。
推理链生成:
MLLM对每个文本提示进行处理,生成包含以下内容的完整推理链:
- 语义标记:对象的详细描述、属性特征及关系逻辑。
- 空间坐标:以标准化格式(如(x1,y1),(x2,y2))表示的位置信息,用于定义各元素在图像中的精确位置。
双重损失监督:
模型训练过程采用交叉熵损失(用于生成推理标记)与扩散均方误差损失(用于保证空间精度)的组合优化方式。
2、语义-空间指导模块(SSGM)
多重指导信号融合:
SSGM整合了三种关键指导信号:
- **语义指导(Gt)**:从推理链中提取的上下文和属性信息。
- **空间指导(Gs)**:从坐标数据中获取的精确位置信息。
- **参考图像指导(Gr)**:在编辑任务中特别重要,用于保持与原始图像的风格一致性。
无分类器指导技术:
在扩散过程中,系统采用上述指导信号的加权组合来优化生成图像。这确保图像合成过程同时受到语义概念和空间布局的双重约束。
3、端到端训练方法
预训练与微调策略:
模型首先在LAHR-GoT和JourneyDB-GoT等大型数据集上进行广泛预训练,随后在专业编辑数据集上进行定向微调。这种两阶段训练策略确保模型同时掌握通用视觉生成能力和精细编辑技能。
参数高效优化:
训练过程采用低秩自适应(LoRA)等技术对MLLM进行微调,在保持模型性能的同时提高计算效率,使模型保持轻量化但功能强大。
总结
GoT:释放多模态大型语言模型在视觉生成和编辑中的推理能力代表了图像合成领域的技术范式转变。通过引入集成语义与空间推理的结构化思维链,GoT框架成功克服了传统文本到图像模型的内在局限。其完备的训练数据集、创新的架构设计和先进的指导机制共同确保了生成图像在技术精确性和视觉表现力方面的卓越品质。
该框架不仅从根本上改变了图像生成与编辑的技术路径,还为多个应用领域开辟了新的可能性——从专业内容创作到教育工具开发。GoT技术框架是人工智能领域的重要进展,展示了结合类人推理与机器智能如何能够创造既具技术突破性又具普适实用性的解决方案。