
我们已经介绍过很多解析机器学习模型的方法,例如如pdp、LIME和SHAP,但是这些方法都是用在表格数据的,他们能不能用在神经网络模型呢?今天我们来LIME解释CNN。
图像与表格数据集有很大不同(显然)。如果你还记得,在之前我们讨论过的任何解释方法中,我们都是根据特征重要性,度量或可视化来解释模型的。比如特征“A”在预测中比特征“B”有更大的影响力。但在图像中没有任何可以命名的特定特征,那么怎么进行解释呢?
一般情况下我们都是用突出显示图像中模型预测的重要区域的方法观察可解释性,这就要求了解如何调整LIME方法来合并图像,我们先简单了解一下LIME是怎么工作的。

LIME在处理表格数据时为训练数据集生成摘要统计:
- 使用汇总统计生成一个新的人造数据集
- 从原始数据集中随机提取样本
- 根据与随机样本的接近程度为生成人造数据集中的样本分配权重
- 用这些加权样本训练一个白盒模型
- 解释白盒模型
就图像而言,上述方法的主要障碍是如何生成随机样本,因为在这种情况下汇总统计将没有任何用处
如何生成人造数据集?
最简单的方法是,从数据集中提取一个随机样本,随机打开(1)和关闭(0)一些像素来生成新的数据集
但是通常在图像中,出现的对象(如狗vs猫的分类中的:狗&猫)导致模型的预测会跨越多个像素,而不是一个像素。所以即使你关掉一两个像素,它们看起来仍然和我们选择样本非常相似。
所以这里需要做的是设置一个相邻像素池的ON和OFF,这样才能保证创造的人工数据集的随机性。所以将图像分割成多个称为超像素的片段,然后打开和关闭这些超像素来生成随机样本。
让我们使用LIME进行二进制分类来解释CNN的代码。例如我们有以下的两类数据。
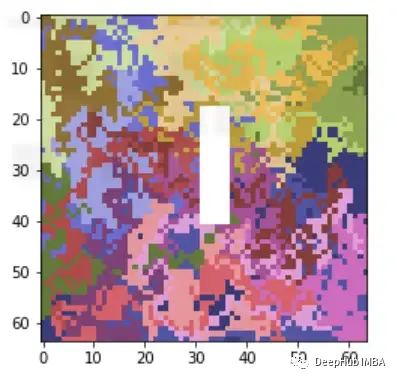
类别0:带有任意大小的白色矩形的随机图像
类别1:随机生成的图像(没有白色矩形)
然后创建一个简单的CNN模型
LIME示例
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.layers import Input, Dense, Embedding, Flatten
from keras.layers import SpatialDropout1D
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.models import Sequential
from randimage import get_random_image, show_array
import random
import pandas as pd
import numpy as np
import lime
from lime import lime_image
from skimage.segmentation import mark_boundaries
#preparing above dataset artificially
training_dataset = []
training_label = []
for x in range(200):
img_size = (64,64)
img = get_random_image(img_size)
a,b = random.randrange(0,img_size[0]/2),random.randrange(0,img_size[0]/2)
c,d = random.randrange(img_size[0]/2,img_size[0]),random.randrange(img_size[0]/2,img_size[0])
value = random.sample([True,False],1)[0]
if value==False:
img[a:c,b:d,0] = 100
img[a:c,b:d,1] = 100
img[a:c,b:d,2] = 100
training_dataset.append(img)
training_label.append(value)
#training baseline CNN model
training_label = [1-x for x in training_label]
X_train, X_val, Y_train, Y_val = train_test_split(np.array(training_dataset).reshape(-1,64,64,3),np.array(training_label).reshape(-1,1), test_size=0.1, random_state=42)
epochs = 10
batch_size = 32
model = Sequential()
model.add(Conv2D(32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
# Output layer
model.add(Dense(32,activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, Y_train, validation_data=(X_val, Y_val), epochs=epochs, batch_size=batch_size, verbose=1)
让我们引入LIME
x=10
explainer = lime_image.LimeImageExplainer(random_state=42)
explanation = explainer.explain_instance(
X_val[x],
model.predict,top_labels=2)
)
image, mask = explanation.get_image_and_mask(0, positives_only=True,
hide_rest=True)
上面的代码片段需要一些解释
我们初始化了LimeImageExplainer对象,该对象使用explain_instance解释特定示例的输出。这里我们从验证集中选取了第10个样本,Get_image_and_mask()返回模型与原始图像一起预测的高亮区域。
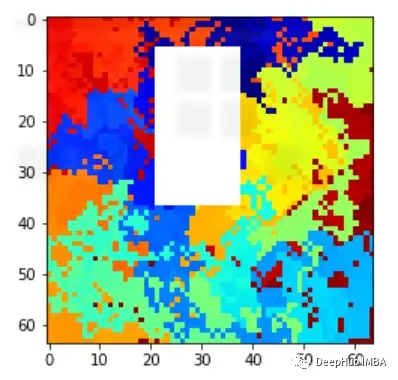
让我们看看一些样本,它们实际上是1(随机图像),但检测到为0(带白框的随机图像)
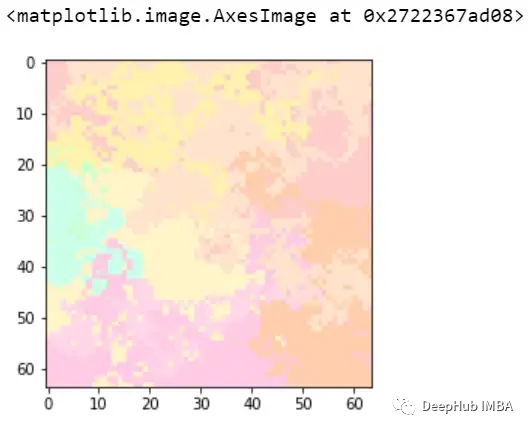
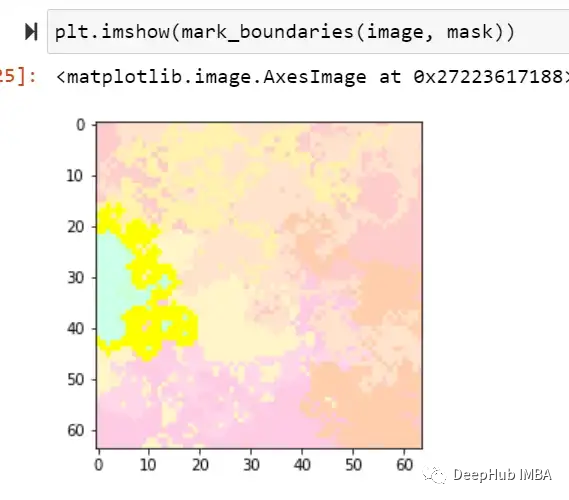
可以看到下图有黄色的突出显示区域,这张图片的标签为1,但被标记为0,这是因为高亮显示的区域看起来像一个矩形,因此让模型感到困惑,也就是说模型错吧黄色标记的部分当成了我们需要判断的白色矩形遮蔽。
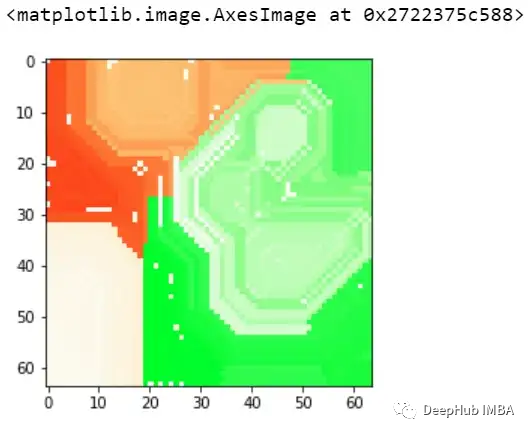
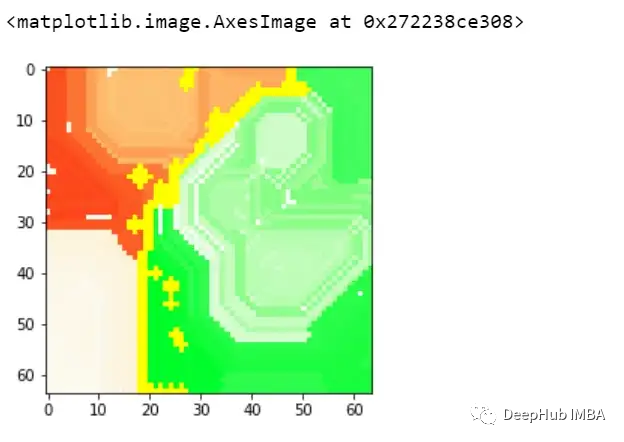
再看看上面两个图,与前面的例子类似,模型也预测了class=0。通过黄色区域可以判断,某种形状可能被模型曲解为白色方框了。
这样我们就可以理解模型导致错误分类的实际问题是什么,这就是为什么可解释和可解释的人工智能如此重要。
作者:Mehul Gupta