
在前一篇文章中,我们介绍了如何使用 GPU 运行的并行算法。这些并行任务是那些完全相互独立的任务,这点与我们一般认识的编程方式有很大的不同,虽然我们可以从并行中受益,但是这种奇葩的并行运行方式对于我们来说肯定感到非常的复杂。所以在本篇文章的Numba代码中,我们将介绍一些允许线程在计算中协作的常见技术。
首先还是载入相应的包
from time import perf_counter
import numpy as np
import numba
from numba import cuda
print(np.__version__)
print(numba.__version__)
cuda.detect()
# 1.21.6
# 0.55.2
# Found 1 CUDA devices
# id 0 b'Tesla T4' [SUPPORTED]
# Compute Capability: 7.5
# PCI Device ID: 4
# PCI Bus ID: 0
# UUID: GPU-bcc6196e-f26e-afdc-1db3-6eba6ff160f0
# Watchdog: Disabled
# FP32/FP64 Performance Ratio: 32
# Summary:
# 1/1 devices are supported
# True
不要忘记,我们这里是CUDA编程,所以NV的GPU是必须的,比如可以去colab或者Kaggle白嫖。
线程间的协作
简单的并行归约算法
我们将从一个非常简单的问题开始本节:对数组的所有元素求和。这个算法非常简单。如果不使用NumPy,我们可以这样实现它:
def sum_cpu(array):
s = 0.0
for i in range(array.size):
s += array[i]
return s
这看起来不是很 Pythonic。但它能够让我们了解它正在跟踪数组中的所有元素。如果 s 的结果依赖于数组的每个元素,我们如何并行化这个算法呢?首先,我们需要重写算法以允许并行化, 如果有无法并行化的部分则应该允许线程相互通信。
到目前为止,我们还没有学会如何让线程相互通信……事实上,我们之前说过不同块中的线程不通信。我们可以考虑只启动一个块,但是我们上次也说了,在大多数 GPU 中块只能有 1024 个线程!
如何克服这一点?如果将数组拆分为 1024 个块(或适当数量的threads_per_block)并分别对每个块求和呢?然后最后,我们可以将每个块的总和的结果相加。下图显示了一个非常简单的 2 块拆分示例。
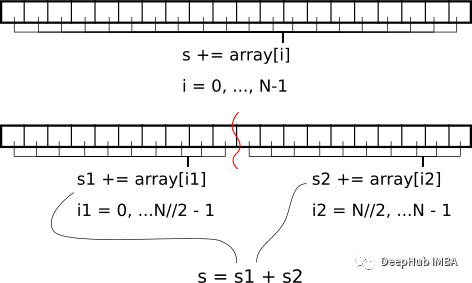
上图就是对数组元素求和的“分而治之”方法。
如何在 GPU 上做到这一点呢?首先需要将数组拆分为块。每个数组块将只对应一个具有固定数量的线程的CUDA块。在每个块中,每个线程可以对多个数组元素求和。然后将这些每个线程的值求和,这里就需要线程进行通信,我们将在下一个示例中讨论如何通信。
由于我们正在对块进行并行化,因此内核的输出应该被设置为一个块。为了完成Reduce,我们将其复制到 CPU 并在那里完成工作。
threads_per_block = 1024 # Why not!
blocks_per_grid = 32 * 80 # Use 32 * multiple of streaming multiprocessors
# Example 2.1: Naive reduction
@cuda.jit
def reduce_naive(array, partial_reduction):
i_start = cuda.grid(1)
threads_per_grid = cuda.blockDim.x * cuda.gridDim.x
s_thread = 0.0
for i_arr in range(i_start, array.size, threads_per_grid):
s_thread += array[i_arr]
# We need to create a special *shared* array which will be able to be read
# from and written to by every thread in the block. Each block will have its
# own shared array. See the warning below!
s_block = cuda.shared.array((threads_per_block,), numba.float32)
# We now store the local temporary sum of a single the thread into the
# shared array. Since the shared array is sized
# threads_per_block == blockDim.x
# (1024 in this example), we should index it with `threadIdx.x`.
tid = cuda.threadIdx.x
s_block[tid] = s_thread
# The next line synchronizes the threads in a block. It ensures that after
# that line, all values have been written to `s_block`.
cuda.syncthreads()
# Finally, we need to sum the values from all threads to yield a single
# value per block. We only need one thread for this.
if tid == 0:
# We store the sum of the elements of the shared array in its first
# coordinate
for i in range(1, threads_per_block):
s_block[0] += s_block[i]
# Move this partial sum to the output. Only one thread is writing here.
partial_reduction[cuda.blockIdx.x] = s_block[0]
这里需要注意的是必须共享数组,并且让每个数组块变得“小”
这里的“小”:确切大小取决于 GPU 的计算能力,通常在 48 KB 和 163 KB 之间。请参阅此表中的“每个线程块的最大共享内存量”项。(https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#features-and-technical-specifications__technical-specifications-per-compute-capability)
在编译时有一个已知的大小(这就是我们调整共享数组threads_per_block而不是blockDim.x的原因)。我们总是可以为任何大小的共享数组定义一个工厂函数……但要注意这些内核的编译时间。
这里的数组需要为 Numba 类型指定的 dtype,而不是 Numpy 类型(这个没有为什么!)。
N = 1_000_000_000
a = np.arange(N, dtype=np.float32)
a /= a.sum() # a will have sum = 1 (to float32 precision)
s_cpu = a.sum()
# Highly-optimized NumPy CPU code
timing_cpu = np.empty(21)
for i in range(timing_cpu.size):
tic = perf_counter()
a.sum()
toc = perf_counter()
timing_cpu[i] = toc - tic
timing_cpu *= 1e3 # convert to ms
print(f"Elapsed time CPU: {timing_cpu.mean():.0f} ± {timing_cpu.std():.0f} ms")
# Elapsed time CPU: 354 ± 24 ms
dev_a = cuda.to_device(a)
dev_partial_reduction = cuda.device_array((blocks_per_grid,), dtype=a.dtype)
reduce_naive[blocks_per_grid, threads_per_block](dev_a, dev_partial_reduction)
s = dev_partial_reduction.copy_to_host().sum() # Final reduction in CPU
np.isclose(s, s_cpu) # Ensure we have the right number
# True
timing_naive = np.empty(21)
for i in range(timing_naive.size):
tic = perf_counter()
reduce_naive[blocks_per_grid, threads_per_block](dev_a, dev_partial_reduction)
s = dev_partial_reduction.copy_to_host().sum()
cuda.synchronize()
toc = perf_counter()
assert np.isclose(s, s_cpu)
timing_naive[i] = toc - tic
timing_naive *= 1e3 # convert to ms
print(f"Elapsed time naive: {timing_naive.mean():.0f} ± {timing_naive.std():.0f} ms")
# Elapsed time naive: 30 ± 12 ms
在谷歌Colab上测试,得到了10倍的加速。
题外话:上面这个方法之所以说是简单的规约算法,是因为这个算法最简单,也最容易实现。我们在大数据中常见的Map-Reduce算法就是这个算法。虽然实现简单,但是他容易理解,所以十分常见,当然他慢也是出名的,有兴趣的大家可以去研究研究。
一种更好的并行归约算法
上面的算法最 “朴素”的,所以有很多技巧可以加快这种代码的速度(请参阅 CUDA 演示文稿中的 Optimizing Parallel Reduction 以获得基准测试)。
在介绍更好的方法之前,让我们回顾一下内核函数的的最后一点:
if tid == 0: # Single thread taking care of business
for i in range(1, threads_per_block):
s_block[0] += s_block[i]
partial_reduction[cuda.blockIdx.x] = s_block[0]
我们并行化了几乎所有的操作,但是在内核的最后,让一个线程负责对共享数组 s_block 的所有 threads_per_block 元素求和。为什么不能把这个总和也并行化呢?
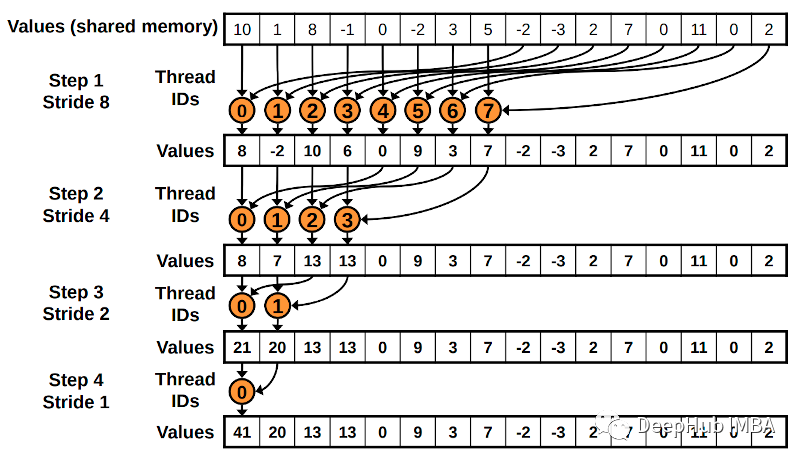
听起来不错对吧,下图显示了如何在 threads_per_block 大小为 16 的情况下实现这一点。我们从 8 个线程开始工作,第一个将对 s_block[0] 和 s_block[8] 中的值求和。第二个求和s_block[1]和s_block[9]中的值,直到最后一个线程将s_block[7]和s_block[15]的值相加。
在下一步中,只有前 4 个线程需要工作。第一个线程将对 s_block[0] 和 s_block[4] 求和;第二个,s_block[1] 和 s_block[5];第三个,s_block[2] 和 s_block[6];第四个也是最后一个,s_block[3] 和 s_block[7]。
第三步,只需要 2 个线程来处理 s_block 的前 4 个元素。
第四步也是最后一步将使用一个线程对 2 个元素求和。
由于工作已在线程之间分配,因此它是并行化的。这不是每个线程的平等划分,但它是一种改进。在计算上,这个算法是 O(log2(threads_per_block)),而上面“朴素”算法是 O(threads_per_block)。比如在我们这个示例中是 1024 次操作,用于 了两个算法差距有10倍
最后还有一个细节。在每一步,我们都需要确保所有线程都已写入共享数组。所以我们必须调用 cuda.syncthreads()。
# Example 2.2: Better reduction
@cuda.jit
def reduce_better(array, partial_reduction):
i_start = cuda.grid(1)
threads_per_grid = cuda.blockDim.x * cuda.gridDim.x
s_thread = 0.0
for i_arr in range(i_start, array.size, threads_per_grid):
s_thread += array[i_arr]
# We need to create a special *shared* array which will be able to be read
# from and written to by every thread in the block. Each block will have its
# own shared array. See the warning below!
s_block = cuda.shared.array((threads_per_block,), numba.float32)
# We now store the local temporary sum of the thread into the shared array.
# Since the shared array is sized threads_per_block == blockDim.x,
# we should index it with `threadIdx.x`.
tid = cuda.threadIdx.x
s_block[tid] = s_thread
# The next line synchronizes the threads in a block. It ensures that after
# that line, all values have been written to `s_block`.
cuda.syncthreads()
i = cuda.blockDim.x // 2
while (i > 0):
if (tid < i):
s_block[tid] += s_block[tid + i]
cuda.syncthreads()
i //= 2
if tid == 0:
partial_reduction[cuda.blockIdx.x] = s_block[0]
reduce_better[blocks_per_grid, threads_per_block](dev_a, dev_partial_reduction)
s = dev_partial_reduction.copy_to_host().sum() # Final reduction in CPU
np.isclose(s, s_cpu)
# True
timing_naive = np.empty(21)
for i in range(timing_naive.size):
tic = perf_counter()
reduce_better[blocks_per_grid, threads_per_block](dev_a, dev_partial_reduction)
s = dev_partial_reduction.copy_to_host().sum()
cuda.synchronize()
toc = perf_counter()
assert np.isclose(s, s_cpu)
timing_naive[i] = toc - tic
timing_naive *= 1e3 # convert to ms
print(f"Elapsed time better: {timing_naive.mean():.0f} ± {timing_naive.std():.0f} ms")
# Elapsed time better: 22 ± 1 ms
可以看到,这比原始方法快25%。
重要说明:你可能很想将同步线程移动到 if 块内,因为在每一步之后,超过当前线程数一半的内核将不会被使用。但是这样做会使调用同步线程的 CUDA 线程停止并等待所有其他线程,而所有其他线程将继续运行。因此停止的线程将永远等待永远不会停止同步的线程。如果您同步线程,请确保在所有线程中调用 cuda.syncthreads()。
i = cuda.blockDim.x // 2
while (i > 0):
if (tid < i):
s_block[tid] += s_block[tid + i]
#cuda.syncthreads() 这个是错的
cuda.syncthreads() # 这个是对的
i //= 2
Numba 自动归约
其实归约算法并不简单,所以Numba 提供了一个方便的 cuda.reduce 装饰器,可以将二进制函数转换为归约。所以上面冗长而复杂的算法可以替换为:
@cuda.reduce
def reduce_numba(a, b):
return a + b
# Compile and check
s = reduce_numba(dev_a)
np.isclose(s, s_cpu)
# True
# Time
timing_numba = np.empty(21)
for i in range(timing_numba.size):
tic = perf_counter()
s = reduce_numba(dev_a)
toc = perf_counter()
assert np.isclose(s, s_cpu)
timing_numba[i] = toc - tic
timing_numba *= 1e3 # convert to ms
print(f"Elapsed time better: {timing_numba.mean():.0f} ± {timing_numba.std():.0f} ms")
# Elapsed time better: 45 ± 0 ms
上面的运行结果我们可以看到手写代码通常要快得多(至少 2 倍),但 Numba 给我们提供的方法却非常容易使用。这对我们来说是格好事,因为终于有我们自己实现的Python方法比官方的要快了😂
这里还有一点要注意就是默认情况下,要减少复制因为这会强制同步。为避免这种情况可以使用设备上数组作为输出调用归约:
dev_s = cuda.device_array((1,), dtype=s)
reduce_numba(dev_a, res=dev_s)
s = dev_s.copy_to_host()[0]
np.isclose(s, s_cpu)
# True
二维规约示例
并行约简技术是非常伟大的,如何将其扩展到更高的维度?虽然我们总是可以使用一个展开的数组(array2 .ravel())调用,但了解如何手动约简多维数组是很重要的。
在下面这个例子中,将结合刚才所学的知识来计算二维数组。
threads_per_block_2d = (16, 16) # 256 threads total
blocks_per_grid_2d = (64, 64)
# Total number of threads in a 2D block (has to be an int)
shared_array_len = int(np.prod(threads_per_block_2d))
# Example 2.4: 2D reduction with 1D shared array
@cuda.jit
def reduce2d(array2d, partial_reduction2d):
ix, iy = cuda.grid(2)
threads_per_grid_x, threads_per_grid_y = cuda.gridsize(2)
s_thread = 0.0
for i0 in range(iy, array2d.shape[0], threads_per_grid_x):
for i1 in range(ix, array2d.shape[1], threads_per_grid_y):
s_thread += array2d[i0, i1]
# Allocate shared array
s_block = cuda.shared.array(shared_array_len, numba.float32)
# Index the threads linearly: each tid identifies a unique thread in the
# 2D grid.
tid = cuda.threadIdx.x + cuda.blockDim.x * cuda.threadIdx.y
s_block[tid] = s_thread
cuda.syncthreads()
# We can use the same smart reduction algorithm by remembering that
# shared_array_len == blockDim.x * cuda.blockDim.y
# So we just need to start our indexing accordingly.
i = (cuda.blockDim.x * cuda.blockDim.y) // 2
while (i != 0):
if (tid < i):
s_block[tid] += s_block[tid + i]
cuda.syncthreads()
i //= 2
# Store reduction in a 2D array the same size as the 2D blocks
if tid == 0:
partial_reduction2d[cuda.blockIdx.x, cuda.blockIdx.y] = s_block[0]
N_2D = (20_000, 20_000)
a_2d = np.arange(np.prod(N_2D), dtype=np.float32).reshape(N_2D)
a_2d /= a_2d.sum() # a_2d will have sum = 1 (to float32 precision)
s_2d_cpu = a_2d.sum()
dev_a_2d = cuda.to_device(a_2d)
dev_partial_reduction_2d = cuda.device_array(blocks_per_grid_2d, dtype=a.dtype)
reduce2d[blocks_per_grid_2d, threads_per_block_2d](dev_a_2d, dev_partial_reduction_2d)
s_2d = dev_partial_reduction_2d.copy_to_host().sum() # Final reduction in CPU
np.isclose(s_2d, s_2d_cpu) # Ensure we have the right number
# True
timing_2d = np.empty(21)
for i in range(timing_2d.size):
tic = perf_counter()
reduce2d[blocks_per_grid_2d, threads_per_block_2d](dev_a_2d, dev_partial_reduction_2d)
s_2d = dev_partial_reduction_2d.copy_to_host().sum()
cuda.synchronize()
toc = perf_counter()
assert np.isclose(s_2d, s_2d_cpu)
timing_2d[i] = toc - tic
timing_2d *= 1e3 # convert to ms
print(f"Elapsed time better: {timing_2d.mean():.0f} ± {timing_2d.std():.0f} ms")
# Elapsed time better: 15 ± 4 ms
设备函数
到目前为止,我们只讨论了内核函数,它是启动线程的特殊GPU函数。内核通常依赖于较小的函数,这些函数在GPU中定义,只能访问GPU数组。这些被称为设备函数(Device functions)。与内核函数不同的是,它们可以返回值。
我们将展示一个跨不同内核使用设备函数的示例。该示例还将展示在使用共享数组时同步线程的重要性。
在CUDA的新版本中,内核可以启动其他内核。这被称为动态并行,但是Numba 的CUDA API还不支持。
我们将在固定大小的数组中创建波纹图案。首先需要声明将使用的线程数,因为这是共享数组所需要的。
threads_16 = 16
import math
@cuda.jit(device=True, inline=True) # inlining can speed up execution
def amplitude(ix, iy):
return (1 + math.sin(2 * math.pi * (ix - 64) / 256)) * (
1 + math.sin(2 * math.pi * (iy - 64) / 256)
)
# Example 2.5a: 2D Shared Array
@cuda.jit
def blobs_2d(array2d):
ix, iy = cuda.grid(2)
tix, tiy = cuda.threadIdx.x, cuda.threadIdx.y
shared = cuda.shared.array((threads_16, threads_16), numba.float32)
shared[tiy, tix] = amplitude(iy, ix)
cuda.syncthreads()
array2d[iy, ix] = shared[15 - tiy, 15 - tix]
# Example 2.5b: 2D Shared Array without synchronize
@cuda.jit
def blobs_2d_wrong(array2d):
ix, iy = cuda.grid(2)
tix, tiy = cuda.threadIdx.x, cuda.threadIdx.y
shared = cuda.shared.array((threads_16, threads_16), numba.float32)
shared[tiy, tix] = amplitude(iy, ix)
# When we don't sync threads, we may have not written to shared
# yet, or even have overwritten it by the time we write to array2d
array2d[iy, ix] = shared[15 - tiy, 15 - tix]
N_img = 1024
blocks = (N_img // threads_16, N_img // threads_16)
threads = (threads_16, threads_16)
dev_image = cuda.device_array((N_img, N_img), dtype=np.float32)
dev_image_wrong = cuda.device_array((N_img, N_img), dtype=np.float32)
blobs_2d[blocks, threads](dev_image)
blobs_2d_wrong[blocks, threads](dev_image_wrong)
image = dev_image.copy_to_host()
image_wrong = dev_image_wrong.copy_to_host()
import matplotlib.pyplot as plt
fig, (ax1, ax2) = plt.subplots(1, 2)
ax1.imshow(image.T, cmap="nipy_spectral")
ax2.imshow(image_wrong.T, cmap="nipy_spectral")
for ax in (ax1, ax2):
ax.set_xticks([])
ax.set_yticks([])
ax.set_xticklabels([])
ax.set_yticklabels([])
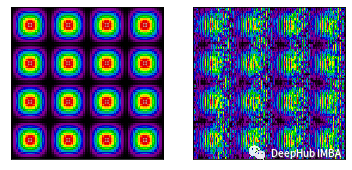
左:同步(正确)内核的结果。正确:来自不同步(不正确)内核的结果。
总结
本文介绍了如何开发需要规约模式来处理1D和2D数组的内核函数。在这个过程中,我们学习了如何利用共享数组和设备函数。如果你对文本感兴趣,请看源代码:
https://colab.research.google.com/drive/1GkGLDexnYUnl2ilmwNxAlWAH6Eo5ZK2f?usp=sharing
作者:Carlos Costa, Ph.D.