
在pytorch中的多GPU训练一般有2种DataParallel(DP)和DistributedDataParallel(DDP) ,DataParallel是最简单的的单机多卡实现,但是它使用多线程模型,并不能够在多机多卡的环境下使用,所以本文将介绍DistributedDataParallel,DDP 基于使用多进程而不是使用多线程的 DP,并且存在 GIL 争用问题,并且可以扩充到多机多卡的环境,所以他是分布式多GPU训练的首选。

这里使用的版本为:python 3.8、pytorch 1.11、CUDA 11.4
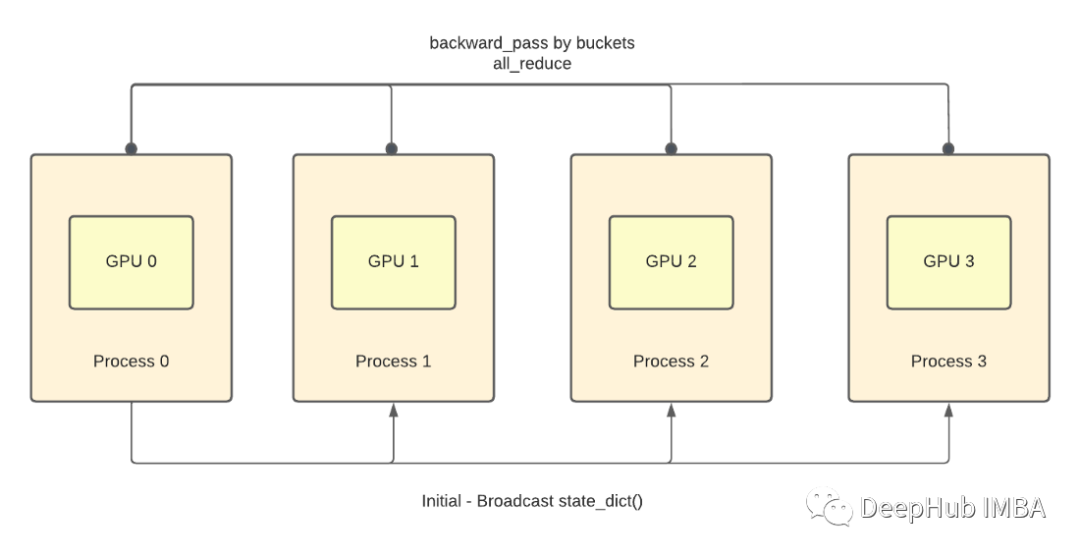
如上图所示,每个 GPU 将复制模型并根据可用 GPU 的数量分配数据样本的子集。
对于 100 个数据集和 4 个 GPU,每个 GPU 每次迭代将处理 25 个数据集。
DDP 上的同步发生在构造函数、正向传播和反向传播上。在反向传播中梯度的平均值被传播到每个 GPU。
有关其他同步详细信息,请查看使用 PyTorch 官方文档:Writing Distributed Applications with PyTorch。
Forking的过程
为了Forking多个进程,我们使用了 Torch 多现成处理框架。一旦产生了进程,第一个参数就是进程的索引,通常称为rank。
在下面的示例中,调用该方法的所有衍生进程都将具有从 0 到 3 的rank值。我们可以使用它来识别各个进程,pytorch会将rank = 0 的进程作为基本进程。
import torch.multiprocessing as mp
// number of GPUs equal to number of processes
world_size = torch.cuda.device_count()
mp.spawn(<selfcontainedmethodforeachproc>, nprocs=world_size, args=(args,))
GPU 进程分配
将 GPU 分配给为训练生成的每个进程。
import torch
import torch.distributed as dist
def train(self, rank, args):
current_gpu_index = rank
torch.cuda.set_device(current_gpu_index)
dist.init_process_group(
backend='nccl', world_size=args.world_size,
rank=current_gpu_index,
init_method='env://'
)
多进程的Dataloader
对于处理图像,我们将使用标准的ImageFolder加载器,它需要以下格式的样例数据。
<basedir>/testset/<categoryname>/<listofimages>
<basedir>/valset/<categoryname>/<listofimages>
<basedir>/trainset/<categoryname>/<listofimages>
下面我们配置Dataloader:
from torchvision.datasets import ImageFolder
train_dataset = ImageFolder(root=os.path.join(<basedir>, "trainset"), transform=train_transform)
当DistributedSample与DDP一起使用时,他会为每个进程/GPU提供一个子集。
from torch.utils.data import DistributedSampler
dist_train_samples = DistributedSampler(dataset=train_dataset, num_replicas =4, rank=rank, seed=17)
DistributedSampler与DataLoader进行整合
from torch.utils.data import DataLoader
train_loader = DataLoader(
train_dataset,
batch_size=self.BATCH_SIZE,
num_workers=4,
sampler=dist_train_samples,
pin_memory=True,
)
模型初始化
对于多卡训练在初始化模型后,还要将其分配给每个GPU。
from torch.nn.parallel import DistributedDataParallel as DDP
from torchvision import models as models
model = models.resnet34(pretrained=True)
loss_fn = nn.CrossEntropyLoss()
model.cuda(current_gpu_index)
model = DDP(model)
loss_fn.cuda(current_gpu_index)
optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.module.parameters()), lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7)
训练
训练开始时需要在DistributedSampler上设置 epoch,这样数据在 epoch 之间进行打乱,并且保证在每个 epoch 中使用相同的排序。
for epoch in range(1, self.EPOCHS+1):
dist_train_samples.set_epoch(epoch)
对于DataLoader中的每个批次,将输入传递给GPU并计算梯度。
for cur_iter_data in (loaders["train"]):
inputs, labels = cur_iter_data
inputs, labels = inputs.cuda(current_gpu_index, non_blocking=True),labels.cuda(current_gpu_index, non_blocking=True)
optimizer.zero_grad(set_to_none=True)
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step()
对比训练轮次的精度,如果更好则存储模型的权重。
if rank % args.n_gpus == 0 :
torch.save(model.module.state_dict(), os.path.join(os.getcwd(), "scripts/model", args.model_file_name))
在训练结束时把模型权重保存在' pth '文件中,这样可以将该文件加载到CPU或GPU上进行推理。
推理
从文件加载模型:
load_path = os.path.join(os.getcwd(), "scripts/model", args.model_file_name)
model_image_classifier = ImageClassifier()
model_image_classifier.load_state_dict(
torch.load(load_path), strict=False
)
model_image_classifier.cuda(current_gpu_index)
model_image_classifier = DDP(model_image_classifier)
model_image_classifier = model_image_classifier.eval()
这样就可以使用通常的推理过程来使用模型了。
总结
以上就是PyTorch的DistributedDataParallel的基本知识,DistributedDataParallel既可单机多卡又可多机多卡。
DDP在各进程梯度计算完成之后各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其广播到所有进程,各进程用该梯度来独立的更新参数。由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次广播),而每次用于更新参数的梯度也一致的,所以各进程的模型参数始终保持一致。
DP的处理则是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余的GPU。在DP中,全程维护一个 optimizer,对各个GPU上梯度进行汇总,在主卡进行参数更新,之后再将模型参数 广播到其他GPU。
所以相较于DP, DDP传输的数据量更少,因此速度更快,效率更高。并且如果你使用过DP就会发现,在使用时GPU0的占用率始终会比其他GPU要高,也就是说会更忙一点,这就是因为GPU0做了一些额外的工作,所以也会导致效率变低。所以如果多卡训练建议使用DDP进行,但是如果模型比较简单例如2个GPU也不需要多机的情况下,那么DP的代码改动是最小的,可以作为临时方案使用。
作者:Kaustav Mandal