
GPU(图形处理单元)最初是为计算机图形开发的,但是现在它们几乎在所有需要高计算吞吐量的领域无处不在。这一发展是由GPGPU(通用GPU)接口的开发实现的,它允许我们使用GPU进行通用计算编程。这些接口中最常见的是CUDA,其次是OpenCL和最近刚出现的HIP。
Python中使用CUDA
CUDA最初被设计为与C兼容后来的版本将其扩展到c++和Fortran。在Python中使用CUDA的一种方法是通过Numba,这是一种针对Python的即时(JIT)编译器,可以针对gpu(它也针对cpu,但这不在我们讨论的范围内)。Numba为我们提供了一个可以直接使用Python子集,Numba将动态编译Python代码并运行它。虽然它没有实现完整的CUDA API,但与cpu相比它支持的特性已经可以帮助我们进行并行计算的加速。
Numba并不是唯一的选择。CuPy 提供了通过基于CUDA的并且兼容Numpy的高级函数,PyCUDA提供了对CUDA API更细粒度的控制,英伟达也发布了官方CUDA Python。
本文不是 CUDA 或 Numba 的综合指南,本文的目标是通过用Numba和CUDA编写一些简单的示例,这样可以让你了解更多GPU相关的知识,无论是是不是使用Python,甚至C编写代码,它都是一个很好的入门资源。

GPU 的并行编程简介
GPU 相对于 CPU 的最大优势是它们能够并行执行相同的指令。单个 CPU 内核将一个接一个地串行运行指令。在 CPU 上进行并行化需要同时使用其多个内核(物理或虚拟)。例如一般的计算机有 4-8 个内核,而GPU 拥有数千个计算核心。有关这两者的比较,请参见下面的图 1。GPU 内核通常速度较慢,且只能执行简单的指令,但它们的数量通常可以弥补这些缺点。
GPU 编程有四个主要方面问题:
1、理解如何思考和设计并行的算法。因为一些算法是串行设计的,把这些算法并行化可能是很困难的。
2、学习如何将CPU上的结构(例如向量和图像)映射到 GPU 上例如线程和块。循环模式和辅助函数可以帮助我们解决这个问题。
3、理解驱动 GPU 编程的异步执行模型。不仅 GPU 和 CPU 相互独立地执行指令,GPU的流还允许多个处理流在同一个GPU上运行,这种异步性在设计最佳处理流时非常重要。
4、抽象概念和具体代码之间的关系:这是通过学习 API 及其细微差别来实现的。
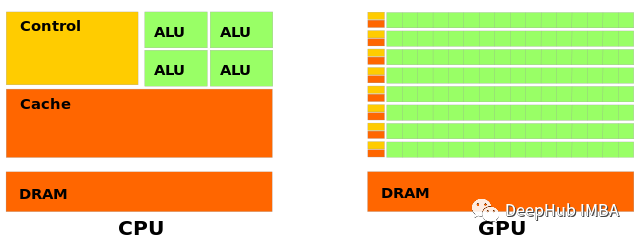
上图为简化的CPU架构(左)和GPU架构(右)。计算发生在ALU(算术逻辑单元)中,DRAM保存数据,缓存保存的数据可以更快地访问,但通常容量更小。
开始编写代码
这里的环境要求是:Numba版本> 0.55和一个GPU。
import numpy as np
import numba
from numba import cuda
print(np.__version__)
print(numba.__version__)
cuda.detect()
# 1.21.6
# 0.55.2
#
# Found 1 CUDA devices
# id 0 b'Tesla T4' [SUPPORTED]
# Compute Capability: 7.5
# PCI Device ID: 4
# PCI Bus ID: 0
# UUID: GPU-e0b8547a-62e9-2ea2-44f6-9cd43bf7472d
# Watchdog: Disabled
# FP32/FP64 Performance Ratio: 32
# Summary:
# 1/1 devices are supported
Numba CUDA的主要操作时是CUDA.jit的装饰器,它定义函数将在GPU中运行。
我们首先写一个简单的函数,它接受两个数字相加然后将它们存储在第三个参数的第一个元素上。
# Example 1.1: Add scalars
@cuda.jit
def add_scalars(a, b, c):
c[0] = a + b
dev_c = cuda.device_array((1,), np.float32)
add_scalars[1, 1](2.0, 7.0, dev_c)
c = dev_c.copy_to_host()
print(f"2.0 + 7.0 = {c[0]}")
# 2.0 + 7.0 = 9.0
因为GPU只能处理简单的工作,所以我们的内核只运行一个函数,后面会将这个函数称之为内核。
第一个需要注意的是内核(启动线程的GPU函数)不能返回值。所以需要通过传递输入和输出来解决这个问题。这是C中常见的模式,但在Python中并不常见。
在调用内核之前,需要首先在设备上创建一个数组。如果想要显示返回值则需要将它复制回CPU。这里就有一个隐形的问题:为什么选择float32(单精度浮点数)?这是因为虽然大多数GPU都支持双精度运算,但双精度运算的时间可能是单精度运算的4倍甚至更长。所以最好习惯使用np.float32和np.complex64而不是float / np.float64和complex / np.complex128
我们的函数定义与普通的函数定定义相同,但调用却略有不同。它在参数之前有方括号:add_scalars[1, 1](2.0, 7.0, dev_c)
这些方括号分别表示网格中的块数和块中的线程数,下面使用CUDA进行并行化时,会进一步讨论。
使用CUDA进行并行化编程
CUDA网格
当内核启动时它会得到一个与之关联的网格,网格由块组成;块由线程组成。下图2显示了一维CUDA网格。图中的网格有4个块。网格中的块数保存在一个特殊的变量中,该变量可以在内核中通过gridDim.x直接访问,这里x是指网格的第一维度(在本例中是唯一的维度)。二维网格也有通过y还有三维网格z变量来访问。到目前2022年,还没有四维网格或更高的网格。在内核内部可以通过使用 blockIdx.x 找出正在执行的块,例如我们这个例子它将从 0 运行到 3。
每个块都有一定数量的线程,保存在变量blockDim.x中。线程索引保存在变量 threadIdx.x 中,在这个示例中变量将从 0 运行到 7。
不同块中的线程被安排以不同的方式运行,访问不同的内存区域并在其他一些方面有所不同,本文主要介绍简单的入门所以我们将跳过这些细节。
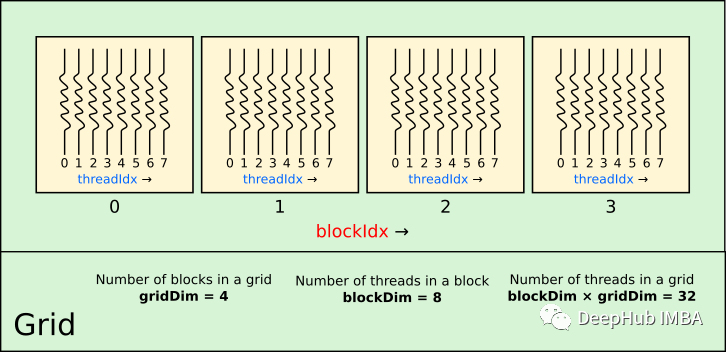
当我们在第一个示例中使用参数[1,1]启动内核时,我们告诉CUDA用一个线程运行一个块。通过修改这两个值可以使用多个块和多现线程多次运行内核。 threadIdx.x 和 blockIdx.x 每个线程的唯一标识。
下面我们对两个数组求和,这比对两个数字求和复杂:假设每个数组都有20个元素。如上图所示,我们可以用每个块8个线程启动内核。如果我们希望每个线程只处理一个数组元素,那么我们至少需要4个块。启动4个块,每个块8个线程,我们的网格将启动32个线程。
对于多线程处理,最需要弄清楚是如何将线程下标映射到数组下标(因为每个线程要独立处理部分数据)。threadIdx.x 从 0 运行到 7,因此它们自己无法索引我们的数组,不同的块也具有相同的threadIdx.x。但是他们有不同的blockIdx.x。为了获得每个线程的唯一索引,我们需要组合这些变量:
i = threadIdx.x + blockDim.x * blockIdx.x
对于第一个块,blockIdx.x = 0,i 将从 0 运行到 7。对于第二个块,blockIdx.x = 1。由于 blockDim.x = 8,将得到 8 运行到 15。类似地,对于 blockIdx. x = 2,将从 16 跑到 23。在第四个也是最后一个区块中,将从 24 跑到 31。见下表 1。

这样虽然将每个线程映射到数组中的每个元素……但是现在我们遇到了一些线程会溢出数组的问题,因为数组有 20 个元素,而 i 的最大值是 32-1。解决方案很简单:对于那些溢出线程,不要做任何事情!
# Example 1.2: Add arrays
@cuda.jit
def add_array(a, b, c):
i = cuda.threadIdx.x + cuda.blockDim.x * cuda.blockIdx.x
if i < a.size:
c[i] = a[i] + b[i]
N = 20
a = np.arange(N, dtype=np.float32)
b = np.arange(N, dtype=np.float32)
dev_c = cuda.device_array_like(a)
add_array[4, 8](a, b, dev_c)
c = dev_c.copy_to_host()
print(c)
# [ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18. 20. 22. 24. 26. 28. 30. 32. 34. 36. 38.]
在较新版本的 Numba 中可能会会收到一条警告,指出我们使用内核使用了非设备上的数据。这条警告的产生的原因是将数据从主机移动到设备非常慢, 我们应该在所有参数中使用设备数组调用内核。所以我们需要预先将数组从主机移动到设备:
dev_a = cuda.to_device(a)
dev_b = cuda.to_device(b)
每个线程唯一索引的计算可能很快就会过期, Numba 提供了非常简单的包装器 cuda.grid,它以网格维度作为唯一参数调用。所以我们新的内核将如下:
# Example 1.3: Add arrays with cuda.grid
@cuda.jit
def add_array(a, b, c):
i = cuda.grid(1)
if i < a.size:
c[i] = a[i] + b[i]
add_array[4, 8](dev_a, dev_b, dev_c)
c = dev_c.copy_to_host()
print(c)
# [ 0. 2. 4. 6. 8. 10. 12. 14. 16. 18. 20. 22. 24. 26. 28. 30. 32. 34. 36. 38.]
如果我们改变数组的大小时会发生什么?我们这里不改变函数而更改网格参数(块数和每个块的线程数),这样就相当于启动至少与数组中的元素一样多的线程。
设置这些参数有一些”科学“和一些”艺术“。对于“科学”:(a)它们应该是 2 的倍数,通常在 32 到 1024 之间,并且(b)它们应该都被使用以最大化占用率(有多少线程同时处于活动状态 )。所以Nvidia 提供了一个可以帮助计算这些的电子表格。(https://docs.nvidia.com/cuda/cuda-occupancy-calculator/index.html) 对于“艺术”而言,没有什么可以预测内核的行为,因此如果真的想优化这些参数,需要根据不同的输入来分析代码。但是根据经验一般GPU 的“合理”线程数是 256。
N = 1_000_000
a = np.arange(N, dtype=np.float32)
b = np.arange(N, dtype=np.float32)
dev_a = cuda.to_device(a)
dev_b = cuda.to_device(b)
dev_c = cuda.device_array_like(a)
threads_per_block = 256
blocks_per_grid = (N + (threads_per_block - 1)) // threads_per_block
# Note that
# blocks_per_grid == ceil(N / threads_per_block)
# ensures that blocks_per_grid * threads_per_block >= N
add_array[blocks_per_grid, threads_per_block](dev_a, dev_b, dev_c)
c = dev_c.copy_to_host()
np.allclose(a + b, c)
# True
代码方面是没有问题了,但是因为硬件限制GPU 不能运行任意数量的线程和块。通常每个块不能超过 1024 个线程,一个网格不能超过 2¹⁶ - 1 = 65535 个块。但是这并不是说可以启动 1024 × 65535 个线程……因为还需要根据寄存器占用的内存量以及其他的因素考虑。还有一点就是处理不适合 GPU RAM 的大型数组(也就是OOM)。在这些情况下,可以使用多个 GPU 分段处理数组(单机多卡)。
在 Python 中,硬件限制可以通过 Nvidia 的 cuda-python 库的函数 cuDeviceGetAttribute 获得,具体请查看该函数说明。
Grid-stride循环
在每个网格的块数超过硬件限制但显存中可以容纳完整数组的情况下,可以使用一个线程来处理数组中的多个元素,这种方法被称为Grid-stride。除了克服硬件限制之外,Grid-stride还受益于重用线程,这样可以将线程创建/销毁开销降到最低。Mark Harris 的文章 CUDA Pro Tip: Write Flexible Kernels with Grid-Stride Loops 详细介绍这个方法,这里就不再介绍了。
在 CUDA 内核中添加一个循环来处理多个输入元素,这个循环的步幅等于网格中的线程数。这样如果网格中的线程总数 (threads_per_grid = blockDim.x * gridDim.x) 小于数组的元素数,则内核处理完索引 cuda.grid(1)它将处理索引 cuda.grid(1) + threads_per_grid,直到处理完所有数组元素,我们来看代码。
# Example 1.4: Add arrays with grid striding
@cuda.jit
def add_array_gs(a, b, c):
i_start = cuda.grid(1)
threads_per_grid = cuda.blockDim.x * cuda.gridDim.x
for i in range(i_start, a.size, threads_per_grid):
c[i] = a[i] + b[i]
threads_per_block = 256
blocks_per_grid_gs = 32 * 80 # Use 32 * multiple of streaming multiprocessors
# 32 * 80 * 256 < 1_000_000 so one thread will process more than one array element
add_array_gs[blocks_per_grid_gs, threads_per_block](dev_a, dev_b, dev_c)
c = dev_c.copy_to_host()
np.allclose(a + b, c)
# True
这段代码与上面的代码非常相似,不同之处在于从cuda.grid(1)开始,但是执行更多的元素,每个threads_per_grid执行一个元素,直到到达数组的末尾。
那么那种方式更快呢?
CUDA 内核的计算时间
GPU 编程的目标就是提高速度。因此准确测量代码执行时间非常重要。
CUDA内核是由主机(CPU)启动的设备函数但它们是在GPU上执行的,GPU和CPU不通信(除非我们让它们通信)。因此当GPU内核被启动时,CPU将简单地继续运行后续指令,不管它们是启动更多的内核还是执行其他CPU函数。所以如果在内核启动前后分别调用time.time(),则只获得了内核启动所需的时间,而不是计算运行所需的时间。
所以这里就需要进行同步,也就是调用 cuda.synchronize()函数,这个函数将停止主机执行任何其他代码,直到 GPU 完成已在其中启动的每个内核的执行。
为了计算内核执行时间,可以简单地计算内核运行然后同步所需的时间,但是需要使用 time.perf_counter() 或 time.perf_counter_ns() 而不是 time.time()。
在使用 Numba 时,我们还有一个细节需要注意:Numba 是一个 Just-In-Time 编译器,这意味着函数只有在被调用时才会被编译。因此计时函数的第一次调用也会计时编译步骤,这通常要慢得多。所以必须首先通过启动内核然后对其进行同步来编译代码,确保了下一个内核无需编译即可立即运行,这样得到的时间才是准确的。
from time import perf_counter_ns
# Compile and then clear GPU from tasks
add_array[blocks_per_grid, threads_per_block](dev_a, dev_b, dev_c)
cuda.synchronize()
timing = np.empty(101)
for i in range(timing.size):
tic = perf_counter_ns()
add_array[blocks_per_grid, threads_per_block](dev_a, dev_b, dev_c)
cuda.synchronize()
toc = perf_counter_ns()
timing[i] = toc - tic
timing *= 1e-3 # convert to μs
print(f"Elapsed time: {timing.mean():.0f} ± {timing.std():.0f} μs")
# Elapsed time: 201 ± 109 μs
# Compile and then clear GPU from tasks
add_array_gs[blocks_per_grid_gs, threads_per_block](dev_a, dev_b, dev_c)
cuda.synchronize()
timing_gs = np.empty(101)
for i in range(timing_gs.size):
tic = perf_counter_ns()
add_array_gs[blocks_per_grid_gs, threads_per_block](dev_a, dev_b, dev_c)
cuda.synchronize()
toc = perf_counter_ns()
timing_gs[i] = toc - tic
timing_gs *= 1e-3 # convert to μs
print(f"Elapsed time: {timing_gs.mean():.0f} ± {timing_gs.std():.0f} μs")
# Elapsed time: 178 ± 141 μs
对于简单的内核,还可以测量算法的整个过程获得每秒浮点运算的数量。通常以GFLOP/s (giga-FLOP /s)为度量单位。加法操作只包含一个触发器:加法。因此,吞吐量由:
# G * FLOP / timing in s
gflops = 1e-9 * dev_a.size * 1e6 / timing.mean()
gflops_gs = 1e-9 * dev_a.size * 1e6 / timing_gs.mean()
print(f"GFLOP/s (algo 1): {gflops:.2f}")
print(f"GFLOP/s (algo 2): {gflops_gs:.2f}")
# GFLOP/s (algo 1): 4.99
# GFLOP/s (algo 2): 5.63
一个二维的例子
下面使用一个更复杂的例子,我们创建一个2D内核来对图像应用对数校正。
给定一个值在0到1之间的图像I(x, y),对数校正图像由
Iᵪ(x, y) = γ log₂(1 + I(x, y))
首先让我们获取一些数据!
import matplotlib.pyplot as plt
from skimage import data
moon = data.moon().astype(np.float32) / 255.
fig, ax = plt.subplots()
im = ax.imshow(moon, cmap="gist_earth")
ax.set_xticks([])
ax.set_yticks([])
ax.set_xticklabels([])
ax.set_yticklabels([])
fig.colorbar(im)
fig.tight_layout()
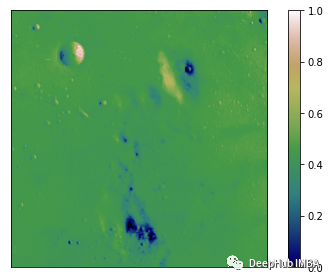
数据在较低端饱和了。几乎没有高于0.6的值。
现在编写核函数。
import math
# Example 1.5: 2D kernel
@cuda.jit
def adjust_log(inp, gain, out):
ix, iy = cuda.grid(2) # The first index is the fastest dimension
threads_per_grid_x, threads_per_grid_y = cuda.gridsize(2) # threads per grid dimension
n0, n1 = inp.shape # The last index is the fastest dimension
# Stride each dimension independently
for i0 in range(iy, n0, threads_per_grid_y):
for i1 in range(ix, n1, threads_per_grid_x):
out[i0, i1] = gain * math.log2(1 + inp[i0, i1])
threads_per_block_2d = (16, 16) # 256 threads total
blocks_per_grid_2d = (64, 64)
moon_gpu = cuda.to_device(moon)
moon_corr_gpu = cuda.device_array_like(moon_gpu)
adjust_log[blocks_per_grid_2d, threads_per_block_2d](moon_gpu, 1.0, moon_corr_gpu)
moon_corr = moon_corr_gpu.copy_to_host()
fig, (ax1, ax2) = plt.subplots(1, 2)
ax1.imshow(moon, cmap="gist_earth")
ax2.imshow(moon_corr, cmap="gist_earth")
ax1.set(title="Original image")
ax2.set(title="Log-corrected image")
for ax in (ax1, ax2):
ax.set_xticks([])
ax.set_yticks([])
ax.set_xticklabels([])
ax.set_yticklabels([])
fig.tight_layout()
第一个for循环从iy开始,第二个最里面的循环从ix开始。为什么选择这个顺序呢?这种选择的内存访问模式更有效。因为第一个网格索引是最快的,所以我们想让它匹配最快的维度:最后一个维度。
结果如下:

总结
本文中介绍了Numba和CUDA的基础知识,我们可以创建简单的CUDA内核,并将其从内存移动到GPU的显存来使用它们。还介绍了如何使用Grid-stride技术在1D和2D数组上迭代。
附录:使用Nvidia的cuda-python来查看设备属性
要对GPU的确切属性进行细粒度控制,可以使用Nvidia提供的较低级别的官方CUDA Python包,代码如下:
# Need to: pip install --upgrade cuda-python
from cuda.cuda import CUdevice_attribute, cuDeviceGetAttribute, cuDeviceGetName, cuInit
# Initialize CUDA Driver API
(err,) = cuInit(0)
# Get attributes
err, DEVICE_NAME = cuDeviceGetName(128, 0)
DEVICE_NAME = DEVICE_NAME.decode("ascii").replace("\x00", "")
err, MAX_THREADS_PER_BLOCK = cuDeviceGetAttribute(
CUdevice_attribute.CU_DEVICE_ATTRIBUTE_MAX_THREADS_PER_BLOCK, 0
)
err, MAX_BLOCK_DIM_X = cuDeviceGetAttribute(
CUdevice_attribute.CU_DEVICE_ATTRIBUTE_MAX_BLOCK_DIM_X, 0
)
err, MAX_GRID_DIM_X = cuDeviceGetAttribute(
CUdevice_attribute.CU_DEVICE_ATTRIBUTE_MAX_GRID_DIM_X, 0
)
err, SMs = cuDeviceGetAttribute(
CUdevice_attribute.CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT, 0
)
print(f"Device Name: {DEVICE_NAME}")
print(f"Maximum number of multiprocessors: {SMs}")
print(f"Maximum number of threads per block: {MAX_THREADS_PER_BLOCK:10}")
print(f"Maximum number of blocks per grid: {MAX_BLOCK_DIM_X:10}")
print(f"Maximum number of threads per grid: {MAX_GRID_DIM_X:10}")
# Device Name: Tesla T4
# Maximum number of multiprocessors: 40
# Maximum number of threads per block: 1024
# Maximum number of blocks per grid: 1024
# Maximum number of threads per grid: 2147483647
作者:Carlos Costa