
Deephub
更多文章请关注公众号:Deephub-IMBA
基于MCMC的贝叶斯营销组合模型评估方法论: 系统化诊断、校准及选择的理论框架
贝叶斯营销组合建模(Bayesian Marketing Mix Modeling,MMM)作为一种先进的营销效果评估方法,其核心在于通过贝叶斯框架对营销投资的影响进行量化分析。

深度学习工程实践:PyTorch Lightning与Ignite框架的技术特性对比分析
在深度学习框架的选择上,PyTorch Lightning和Ignite代表了两种不同的技术路线。本文将从技术实现的角度,深入分析这两个框架在实际应用中的差异,为开发者提供客观的技术参考。
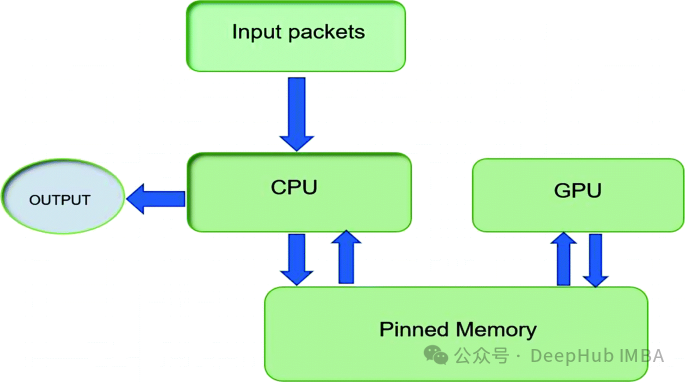
通过pin_memory 优化 PyTorch 数据加载和传输:工作原理、使用场景与性能分析
本文将深入探讨何时以及为何启用这一设置,帮助你优化 PyTorch 中的内存管理和数据吞吐量。
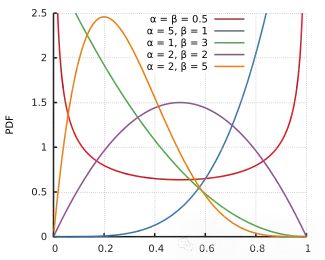
贝叶斯统计中常见先验分布选择方法总结
本文详细介绍了贝叶斯统计中三种常见的先验分布选择方法:经验贝叶斯方法、信息先验和无信息/弱信息先验。
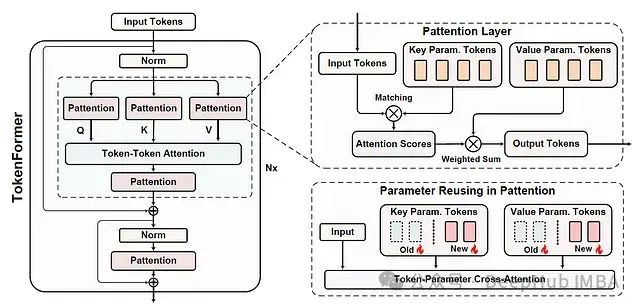
Tokenformer:基于参数标记化的高效可扩展Transformer架构
本文是对发表于arXiv的论文 "TOKENFORMER: RETHINKING TRANSFORMER SCALING WITH TOKENIZED MODEL PARAMETERS" 的深入解读与扩展分析。
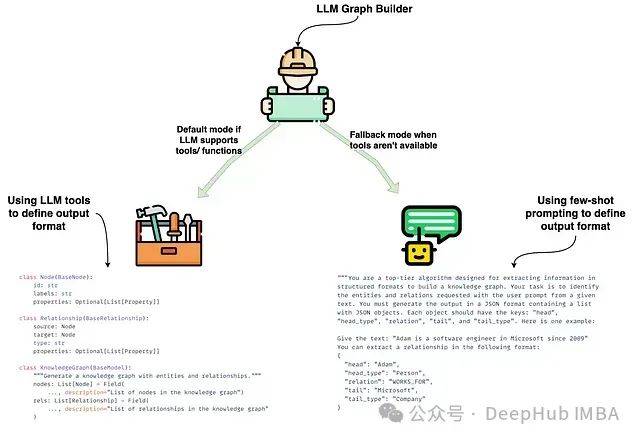
基于LLM Graph Transformer的知识图谱构建技术研究:LangChain框架下转换机制实践
本文是LangChain的一个代码贡献者编写的文章,将对这些内容进行详细介绍,文章最后还包含了作者提供的源代码
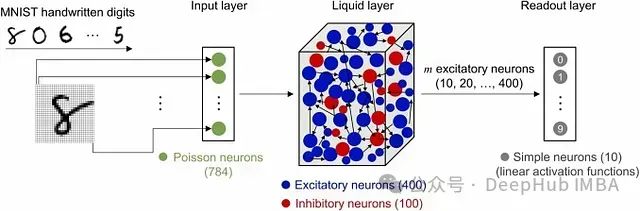
基于Liquid State Machine的时间序列预测:利用储备池计算实现高效建模
**Liquid State Machine (LSM)** 是一种 **脉冲神经网络 (Spiking Neural Network, SNN)** ,在计算神经科学和机器学习领域中得到广泛应用,特别适用于处理 **时变或动态数据**。
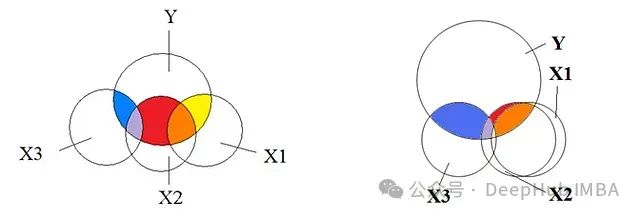
深入理解多重共线性:基本原理、影响、检验与修正策略
本文将深入探讨多重共线性的本质,阐述其重要性,并提供有效处理多重共线性的方法,同时避免数据科学家常犯的陷阱。

基于PyTorch的大语言模型微调指南:Torchtune完整教程与代码示例
**Torchtune**是由PyTorch团队开发的一个专门用于LLM微调的库。它旨在简化LLM的微调流程,提供了一系列高级API和预置的最佳实践,使得研究人员和开发者能够更加便捷地对LLM进行调试、训练和部署。

10种数据预处理中的数据泄露模式解析:识别与避免策略
当测试数据在数据准备阶段无意中泄露(渗透)到训练数据时,就会发生数据泄露。这种情况经常出现在常规数据处理任务中,而你可能并未察觉。当泄露发生时,模型会从本不应看到的测试数据中学习,导致测试结果失真。

随机性、熵与随机数生成器:解析伪随机数生成器(PRNG)和真随机数生成器(TRNG)
本文将探讨随机性、熵的概念以及不同类型随机数生成器(random number generator, RNG)的原理,重点介绍伪随机数生成器(PRNG)和真随机数生成器(TRNG)。
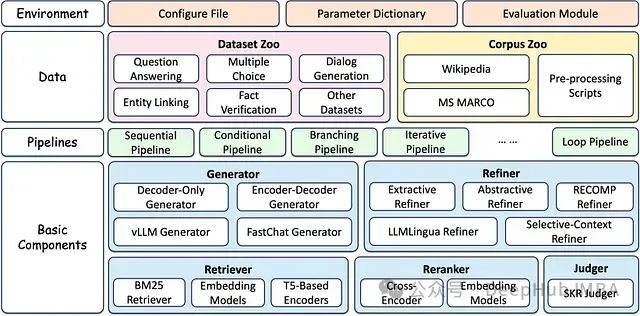
Github上的十大RAG(信息检索增强生成)框架
随着对先进人工智能解决方案需求的不断增长,GitHub上涌现出众多开源RAG框架,每一个都提供了独特的功能和特性。

基于图论的时间序列数据平稳性与连通性分析:利用图形、数学和 Python 揭示时间序列数据中的隐藏模式
在本文中,我们将探讨图论如何洞察时间关系和平稳性,将介绍基于图的变换的基本概念,讨论时间序列数据的平稳性,并展示如何应用这些概念。
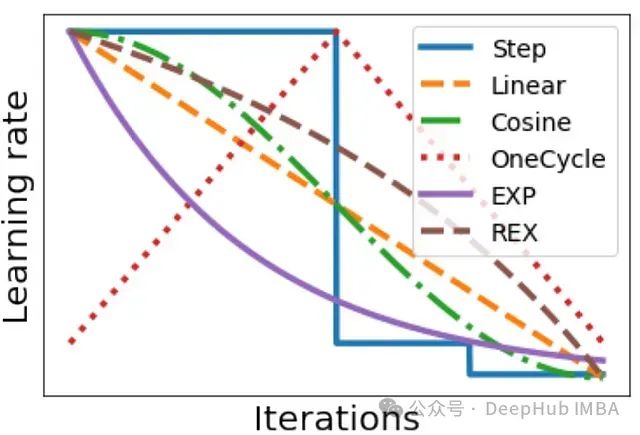
深度学习中的学习率调度:循环学习率、SGDR、1cycle 等方法介绍及实践策略研究
深度学习实践者都知道,在训练神经网络时,正确设置学习率是使模型达到良好性能的关键因素之一。学习率通常会在训练过程中根据某种调度策略进行动态调整。调度策略的选择对训练质量也有很大影响。

过采样与欠采样技术原理图解:基于二维数据的常见方法效果对比
本文详细探讨了在不平衡数据集上进行分类任务时常用的过采样和欠采样技术。通过二维数据可视化示例,直观展现了各类采样方法的原理和效果差异。
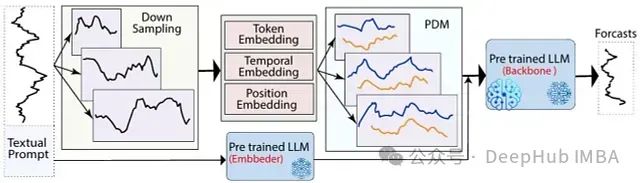
LLM-Mixer: 融合多尺度时间序列分解与预训练模型,可以精准捕捉短期波动与长期趋势
LLM-Mixer通过结合多尺度时间序列分解和预训练的LLMs,提高了时间序列预测的准确性。它利用多个时间分辨率有效地捕捉短期和长期模式,增强了模型的预测能力
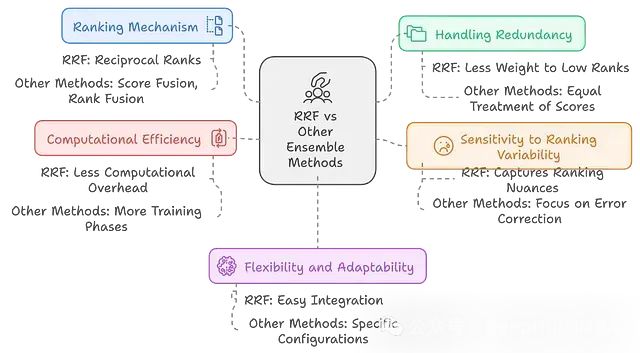
RAPTOR:多模型融合+层次结构 = 检索性能提升20%,结果还更稳健
RAPTOR通过结合多个检索模型,构建层次化的信息组织结构,并采用递归摘要等技术,显著提升了检索系统的性能和适应性。
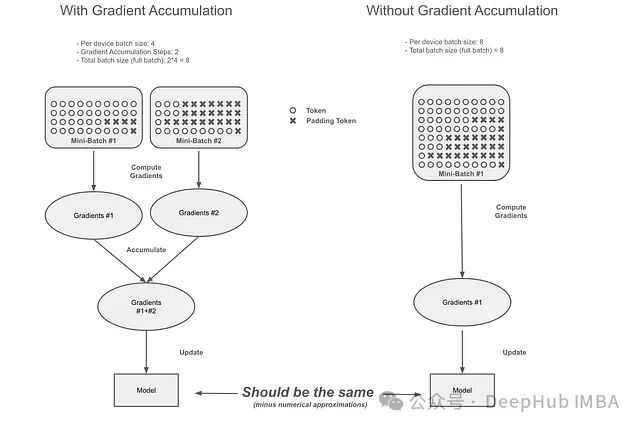
梯度累积的隐藏陷阱:Transformer库中梯度累积机制的缺陷与修正
本文将从以下几个方面展开讨论:首先阐述梯度累积的基本原理,通过实例说明问题的具体表现和错误累积过程;其次分析不同训练场景下该问题的影响程度;最后评估Unsloth提出并已被Hugging Face在Transformers框架中实现的修正方案的有效性。
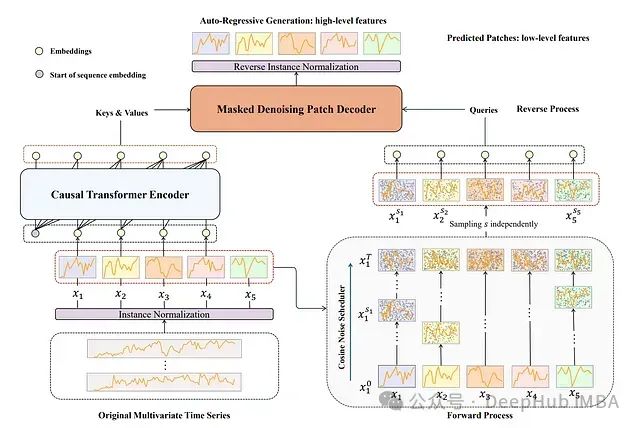
TimeDART:基于扩散自回归Transformer 的自监督时间序列预测方法
TimeDART是一种专为**时间序列预测**设计的自**监督学习**方法。它的核心思想是通过从时间序列历史数据中学习模式来改进未来数据点的预测。
11种经典时间序列预测方法:理论、Python实现与应用
本文将总结11种经典的时间序列预测方法,并提供它们在Python中的实现示例。