
时间序列概况在日常生活和专业研究中都很常见。简而言之,时间序列概况是一系列连续的数据点 y(0), y(1), ..., y(t) ,其中时间 t 的点依赖于时间 t-1 的前一个点(或更早的时间点)。
在许多应用中,研究者致力于预测时间序列概况的未来行为。存在各种建模方法。这些模型通常基于过去或现在的信息,对未来概况进行估计。相关研究涉及多个领域,如使用神经网络进行天气预报(Bi et al., 2023)、深度学习在股票价格预测中的应用(Xiao and Su, 2022)以及制药产品需求演变分析(Rathipriya et al., 2023)等。
然而,模型训练需要数据支持。通常,数据质量越高,对研究过程的描述就越准确。
一般而言,模型可以学习预测下一个状态 y(t+1) ,如果给定先前的时间点 y(0), ..., y(t) 。但在某些应用中,我们可能需要模型接收当前观察值 y(0), ..., y(t) ,并预测系统在当前或下一个时间点的变化速率。这就要求我们获得系统的导数 dy ,而非可观察状态 y 。所以要训练此类模型并输出导数 dy ,首先需要收集这些导数数据,这些导数是直接从观察数据 y 计算得出的,因为直接测量导数在很多情况下可能困难或不可行。
这就引出了一个关键问题:噪声。处理过噪声时间序列数据的研究者都知道计算其导数的困难。
有多种方法可以处理时间序列数据中的噪声。本文将介绍一种在我们的研究项目中表现良好的方法,特别适用于时间序列概况中数据点较少的情况。
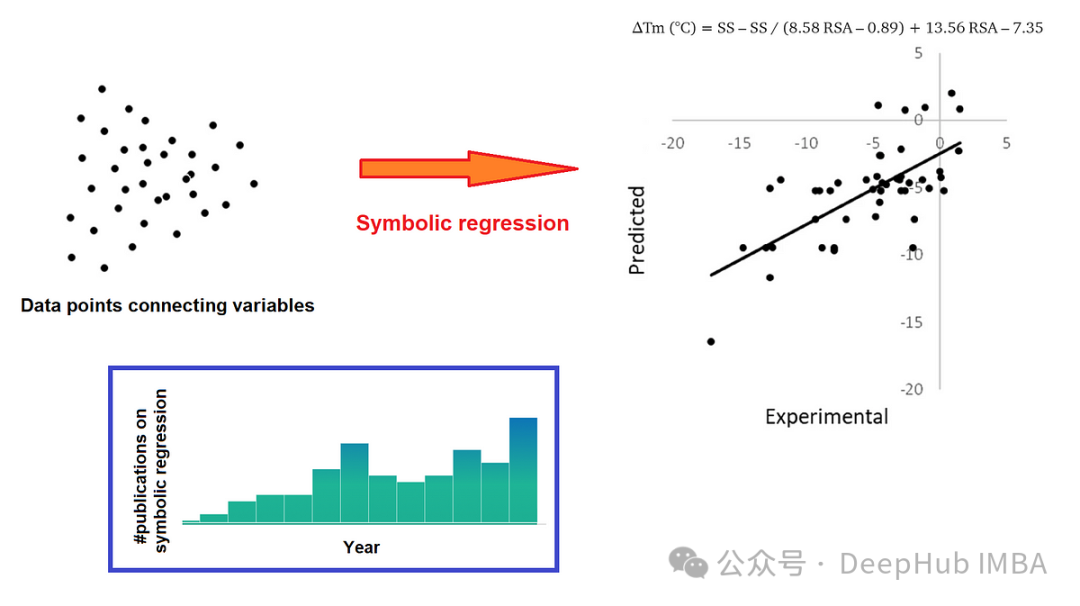
让我们开始使用Python来实现这个方法。
数据生成
首先,我们需要创建一个测试场景,并且希望模拟数据点较少的情况,我们将构建一个简单的生物反应器模型。
在这个反应器中,生物质(如细菌或其他细胞)消耗底物(如糖),并产生一种产品,例如具有药用价值的蛋白质。我们关注"生物质"、"底物"和"产品"这三个变量。这些物质的浓度(以克/升(g/L)为单位)在给定时间点 t 可直接测量,构成了我们的可观察数据 y 。
我们的目标是创建一个能够输出导数的特定形式的模型。需要从观察到的时间序列概况 y 中推导出导数。
让我们使用Python来实现这个过程。首先导入必要的包,并定义一个用于保存图形的函数:
importos
importrandom
random.seed(0)
importnumpyasnp
importmatplotlib.pyplotasplt
fromscipy.integrateimportodeint
fromsklearn.metricsimportmean_squared_error
# 保存图形的函数
FIG_SIZE= (7, 2.5)
FIG_DPI=400
FIG_SAVEPATH='.'
FIG_SAVEEXT= ['png']
defsave_figure(figure_savepath : str=None,
save_figures_extension : list= ['png'],
figure_name : str='Figure',
dpi : int=1200):
figure_name=figure_name
ifisinstance(save_figures_extension, list):
figure_extension_list=save_figures_extension
else:
raiseValueError('[-] The indicated file extension for figures needs to be a list!')
forfigure_extensioninfigure_extension_list:
iffigure_savepathisNone:
figure_savepath=os.getcwd()
savepath=os.path.join(figure_savepath, figure_name+'.'+figure_extension)
plt.savefig(savepath, dpi=dpi)
print(f'[!] Figure saved as: {savepath}')
接下来,定义一个类来模拟上述生物反应器场景。这个类将使用给定的初始条件 y0 和80小时的时间跨度( tspan )求解一个常微分方程(ODE)系统,使用20个时间点。这种设置模拟了每四小时采样一次的低频采样情况。
#%% 生成时间序列数据
# ============================================================================
classdatagen():
# ------------------------------------------------------------------------
def__init__(self,
y0=np.array([0.1, 60, 0]),
tspan=np.linspace(0, 80, 20)):
self.y0=y0
self.tspan=tspan
self.specnames= ['Biomass', 'Substrate', 'Product']
# ------------------------------------------------------------------------
defsolve_ODE_model(self):
'''求解给定样本和时间跨度的ODE模型。 \
返回导数(dydt)作为形状为[n,]的数组和ODE求解器的运行时间。
'''
# 模拟反应器操作直到选定的时间tf
self.y=odeint(func=self.ODEmodel, y0=self.y0, t=self.tspan)
# ------------------------------------------------------------------------
defODEmodel(self, y, t):
'''调整后的批次发酵ODE模型。
'''
# 变量
X=y[0]
S=y[1]
P=y[2]
# 参数
mu_max=0.25; #h^-1
K_S=105.4; #kg/m^3
Y_XS=0.07; #[-]
Y_PS=0.167; #[-]
KXmu=121.8669;#g/L 高细胞密度导致的生物量生长抑制常数
T=273+35; #K
R=0.0083145; #kJ/(K*mol) 通用气体常数
k1_=130.0307; #[-] 生物量生长激活常数
E1_=12.4321; #kJ/mol 生物量生长激活焓
k2_=3.8343e48; #[-] 生物量生长失活常数
E2_=298.5476; #kJ/mol 生物量生长失活焓
# 定义速率常数的温度依赖性
k1=k1_*np.exp(-E1_/(R*T))
k2=k2_*np.exp(-E2_/(R*T))
# 计算生物量的比生长速率
mu= (mu_max*S)/(K_S+S) *k1/(1+k2) * (1-(X/(KXmu+X)))
# 计算底物消耗
sigma=-(1/Y_XS)*mu
# 计算蛋白质的比生产速率
pi=Y_PS/Y_XS*mu
# 速率矢量化
rate=np.hstack((mu.reshape(-1,1), sigma.reshape(-1,1), pi.reshape(-1,1)))
# 生物量、体积和产品的ODE
dydt=rate*X.reshape(-1,1)
# 返回
returndydt.reshape(-1,)
# ------------------------------------------------------------------------
defaddnoise_per_species(self, percentage=5):
'''使用一些基准数据并添加噪声。
'''
self.y_noisy=np.zeros((self.y.shape[0], 0))
forspec_idinrange(self.y.shape[1]):
rmse=mean_squared_error(self.y[:, spec_id], np.zeros(self.y[:, spec_id].shape), squared=False)
y_noisy_spec=self.y[:, spec_id] +np.random.normal(0, rmse/100.0*percentage, self.y[:, spec_id].shape)
self.y_noisy=np.hstack((self.y_noisy, y_noisy_spec.reshape(-1,1)))
# ----------------------------------------
defevaluate_true_derivatives(self):
'''评估生成数据的真实导数。
'''
self.y_true_diff=np.zeros((0, self.y.shape[1]))
fort_id, tinenumerate(self.tspan):
self.y_true_diff=np.vstack((self.y_true_diff, self.ODEmodel(y=self.y[t_id, :], t=t).reshape(1,-1)))
有了这个类,我们可以实例化它,通过求解ODE系统生成数据,并添加噪声。以下代码展示了如何生成数据并可视化结果:
# 实例化类
data=datagen()
# 创建数据并添加噪声
data.solve_ODE_model()
data.addnoise_per_species()
data.evaluate_true_derivatives()
# 绘制真实和噪声数据
fig, ax=plt.subplots(figsize=FIG_SIZE, ncols=3)
foriinrange(len(data.specnames)):
ax[i].plot(data.tspan, data.y[:, i], marker='', linestyle='--', color='black', label='Ground truth')
ax[i].plot(data.tspan, data.y_noisy[:, i], marker='o', markersize=4, linestyle='', color='black', alpha=0.6, label='Observed')
ax[i].set_xlabel('Time / h', fontsize=8)
ax[i].set_ylabel('{} / g/L'.format(data.specnames[i]), fontsize=8)
ax[i].tick_params(axis='both', which='major', labelsize=8)
ifi==1:
ax[i].legend(frameon=False, fontsize=8, loc='lower left')
plt.tight_layout()
save_figure(figure_savepath=FIG_SAVEPATH, save_figures_extension=FIG_SAVEEXT, figure_name='True_and_noisy_data', dpi=FIG_DPI)
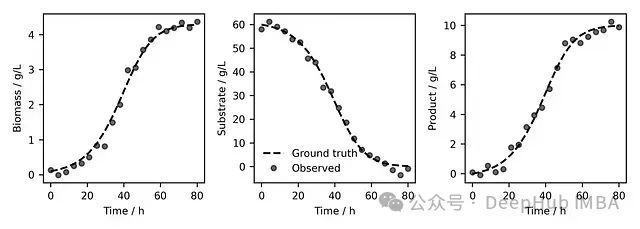
图1. 研究系统的基准真实情况(虚线)与观察到的噪声数据点(黑色圆圈)。
图1展示了生成的数据。虚线表示无噪声的真实数据,而黑点表示添加噪声后的观察数据。从左到右的三个图分别显示了生物质增长、底物消耗和产品形成的过程。
接下来,我们将探讨几种不同的方法来计算这些噪声数据的导数,并比较它们的性能。
有限差分法的直接应用
首先,我们将直接对噪声数据应用有限差分(FD)法。这是一种计算函数导数的基本方法,定义如下:
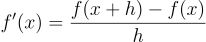
其中 f'(x) 是函数 f(x) 在点 x 处的导数, h 是一个小步长。
以下是有限差分法的Python实现:
deffinite_difference(x_data, y_data):
x_diff=np.zeros((y_data.shape[0]-1, y_data.shape[1]))
y_diff=np.zeros((y_data.shape[0]-1, y_data.shape[1]))
dt= (x_data[1] -x_data[0])/2
forspec_idinrange(y_data.shape[1]):
y_diff_FD= []
x_diff_FD= []
fort_inrange(len(x_data)-1):
x_diff_FD.append(x_data[t_] +dt)
y_diff_FD.append((y_data[t_+1, spec_id] -y_data[t_, spec_id])/(x_data[t_+1] -x_data[t_]))
x_diff[:, spec_id] =np.array(x_diff_FD)
y_diff[:, spec_id] =np.array(y_diff_FD)
returnx_diff[:,0].reshape(-1,), y_diff
# 执行有限差分
data.x_diff_FD, data.y_diff_FD=finite_difference(data.tspan, data.y_noisy)
让我们比较FD法计算的导数与真实导数:
fig, ax=plt.subplots(figsize=FIG_SIZE, ncols=3)
foriinrange(len(data.specnames)):
ax[i].plot(data.tspan, data.y_true_diff[:, i], marker='', linestyle='--', color='black', label='True')
ax[i].plot(data.x_diff_FD, data.y_diff_FD[:, i], marker='', markersize=4, linestyle='-', color='blue', label='FD')
ax[i].set_xlabel('Time / h', fontsize=8)
ax[i].set_ylabel('Derivative {} / g/L/h'.format(data.specnames[i]), fontsize=8)
ax[i].tick_params(axis='both', which='major', labelsize=8)
ifi==1:
ax[i].legend(frameon=False, fontsize=8, loc='upper center')
plt.tight_layout()
save_figure(figure_savepath=FIG_SAVEPATH, save_figures_extension=FIG_SAVEEXT, figure_name='Derivative_comparison_FD', dpi=FIG_DPI)
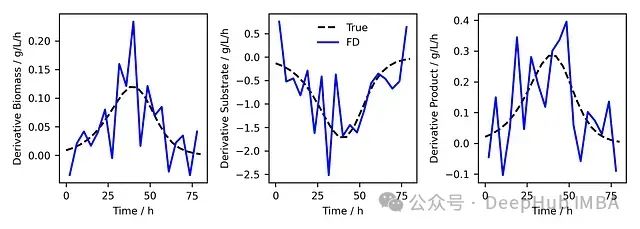
图2. 基准真实导数(虚线)与通过FD计算的导数(蓝色实线)对比。
图2展示了FD法的局限性。黑色虚线表示真实导数,蓝色实线表示FD法计算的导数。可以观察到,FD法对噪声极为敏感。这种敏感性导致了导数的显著波动,使得计算结果难以应用于后续分析或建模。
Savitzky-Golay滤波技术
为了减少噪声影响,一种常用方法是在计算导数之前先对数据进行滤波。Savitzky-Golay(SG)滤波器是一种广泛使用的数据平滑技术。SG滤波器通过在移动窗口内拟合多项式来平滑数据。可以使用
scipy
包中的SG滤波器实现:
fromscipy.signalimportsavgol_filter
# 定义SG滤波器参数
window_size=5
polynomial_order=2
# 对每个物种的噪声数据进行平滑
y_smooth=np.zeros((data.y_noisy.shape[0], data.y_noisy.shape[1]))
foriinrange(data.y_noisy.shape[1]):
y_smooth[:, i] =savgol_filter(data.y_noisy[:, i], window_size, polynomial_order)
# 绘制平滑数据与噪声数据的对比
fig, ax=plt.subplots(figsize=FIG_SIZE, ncols=3)
foriinrange(len(data.specnames)):
ax[i].plot(data.tspan, data.y[:, i], marker='', linestyle='--', color='black', label='True')
ax[i].plot(data.tspan, data.y_noisy[:, i], marker='o', markersize=4, linestyle='', color='black', label='Observed')
ax[i].plot(data.tspan, y_smooth[:, i], marker='', linestyle='-', color='red', label='Smoothed')
ax[i].set_xlabel('Time / h', fontsize=8)
ax[i].set_ylabel('{} / g/L'.format(data.specnames[i]), fontsize=8)
ax[i].tick_params(axis='both', which='major', labelsize=8)
ifi==1:
ax[i].legend(frameon=False, fontsize=8, loc='lower left')
plt.tight_layout()
save_figure(figure_savepath=FIG_SAVEPATH, save_figures_extension=FIG_SAVEEXT, figure_name='Smoothing_SG', dpi=FIG_DPI)
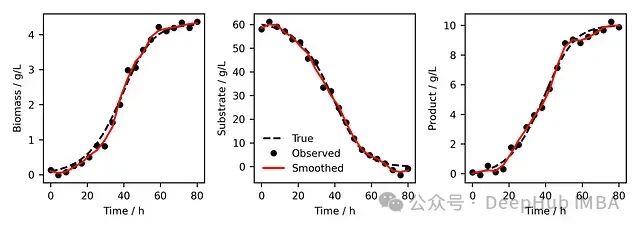
图3. 基准真实数据(黑色虚线)与观察到的噪声数据点(黑色圆圈)和SG平滑后的概况(红色实线)对比。
使用平滑后的数据点重新计算导数:
# 对Savitzky-Golay平滑后的数据使用FD法计算导数
data.x_diff_SGFD, data.y_diff_SGFD=finite_difference(data.tspan, y_smooth)
比较SG-FD方法与之前的结果:
# 可视化真实导数、FD和SGFD的结果
fig, ax=plt.subplots(figsize=FIG_SIZE, ncols=3)
foriinrange(len(data.specnames)):
ax[i].plot(data.tspan, data.y_true_diff[:, i], 'k--', label='True')
ax[i].plot(data.x_diff_FD, data.y_diff_FD[:, i], 'b-', label='FD')
ax[i].plot(data.x_diff_SGFD, data.y_diff_SGFD[:, i], 'r-', label='SGFD')
ax[i].set_xlabel('Time / h', fontsize=8)
ax[i].set_ylabel('Derivative {} / g/L/h'.format(data.specnames[i]), fontsize=8)
ax[i].tick_params(axis='both', which='major', labelsize=8)
ifi==1:
ax[i].legend(frameon=False, fontsize=8, loc='best')
plt.tight_layout()
save_figure(figure_savepath=FIG_SAVEPATH, save_figures_extension=FIG_SAVEEXT, figure_name='Derivative_comparison_FD_SGFD', dpi=FIG_DPI)
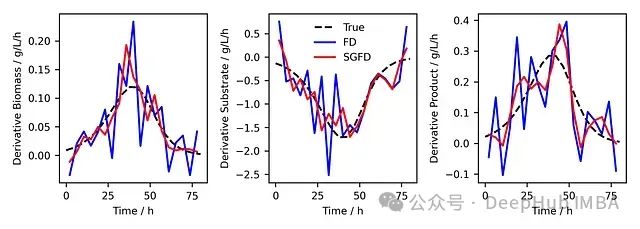
图4. 基准真实导数(黑色虚线)与通过FD计算的导数(蓝色实线)和SG平滑后用FD计算的数据(红色实线)对比。
图4显示,SG-FD方法(红线)相比直接FD方法(蓝线)有所改善。但是结果仍然存在明显的噪声影响,特别是在数据变化较快的区域。这表明在数据点较少的情况下,SG滤波器的效果可能不够理想。
符号回归方法
现在介绍一种不太常用但在某些情况下非常有效的方法:符号回归(SR)。SR方法的核心思想是找到一个能够很好拟合数据的函数表达式。一旦我们有了这个函数表达式,就可以对其进行解析微分,从而获得更平滑的导数估计。
SR方法的优势在于它可以自动发现数据中的潜在模式和关系,而不需要预先指定函数形式。这对于复杂的非线性系统特别有用。
我们将使用
udiff
包来实现SR方法。这个包基于Guimerà等人(2020)开发的BMS算法。以下是使用SR方法的代码:
from udiff.smooth import smooth_bms # 使用符号回归模型平滑数据
from udiff.differentiate import differentiator # 对获得的符号回归模型进行解析微分
# 创建空数组用于存储拟合概况
data.y_smooth_sr = np.zeros(data.y.shape)
data.y_diff_sr = np.zeros(data.y.shape)
# 对每个物种拟合概况并求导(这个过程可能需要一些时间)
for spec_id in range(data.y.shape[1]):
X = data.tspan
Y = data.y_noisy[:, spec_id]
obj = smooth_bms(x=X, y=Y, scaling=False)
obj.fit_bms(nsteps=1e4, maxtime=1800, minr2=0.999, show_update=True, update_every_n_seconds=200)
data.y_smooth_sr[:, spec_id] = obj.y_smooth
diffobj = differentiator(obj)
diffobj.differentiate()
data.y_diff_sr[:, spec_id] = diffobj.y_diff
这个过程可能需要一些时间,因为SR算法需要搜索和评估大量可能的函数表达式。完成后,我们可以比较SR方法与之前的方法:
# 可视化真实导数、FD、SGFD和SR的结果
fig, ax = plt.subplots(figsize=FIG_SIZE, ncols=3)
nm = data.specnames
for i in range(len(data.specnames)):
ax[i].plot(data.tspan, data.y_true_diff[:, i], 'k--', label='True')
ax[i].plot(data.x_diff_FD, data.y_diff_FD[:, i], 'b-', label='FD')
ax[i].plot(data.x_diff_SGFD, data.y_diff_SGFD[:, i], 'r-', label='SGFD')
ax[i].plot(data.tspan, data.y_diff_sr[:, i], 'g-', label='SR')
ax[i].set_xlabel('Time / h', fontsize=8)
ax[i].set_ylabel('Derivative {} / g/L/h'.format(data.specnames[i]), fontsize=8)
ax[i].tick_params(axis='both', which='major', labelsize=8)
if i == 1:
ax[i].legend(frameon=False, fontsize=8, loc='best')
plt.tight_layout()
save_figure(figure_savepath = FIG_SAVEPATH, save_figures_extension = FIG_SAVEEXT, figure_name = 'Derivative_comparison_FD_SGFD_BMS', dpi = FIG_DPI)
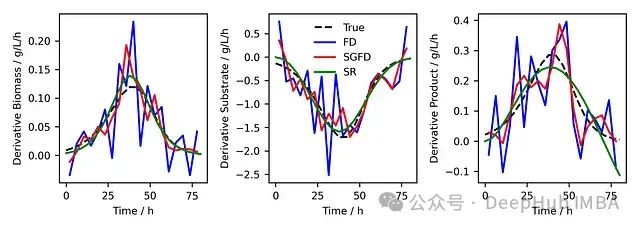
图5. 基准真实导数(黑色虚线)与通过FD计算的导数(蓝色实线)、SG平滑后用FD计算的数据(红色实线),以及符号回归平滑数据后进行解析微分(绿色实线)的对比。
图5清晰地展示了SR方法(绿线)的优越性。与FD和SG-FD方法相比,SR方法产生的导数估计更加平滑,更接近真实导数。这种改进尤其明显在数据变化较快的区域,这些区域通常是FD和SG-FD方法表现不佳的地方。
SR方法的成功在于它能够捕捉数据的整体趋势,而不是过度拟合局部噪声。通过找到一个能够很好描述整个数据集的函数表达式,SR方法能够在保持数据整体特征的同时,有效地过滤掉噪声的影响。
需要注意的是,SR方法也不是完美的。它的性能可能受到初始参数设置和计算时间的影响。此外,对于极其复杂或高度非线性的系统,SR方法可能难以找到准确的函数表达式。
总结
本文展示了在处理噪声时间序列数据时,获得可靠导数估计的几种方法。我们从最基本的有限差分法开始,然后探讨了Savitzky-Golay滤波与有限差分相结合的方法,最后介绍了符号回归这一较为先进的技术。
研究结果表明,在数据点较少且存在显著噪声的情况下,符号回归方法能够提供最可靠的导数估计。这种方法的优势在于它能够找到一个封闭形式的函数表达式来描述数据,从而允许进行解析微分。
值得注意的是,没有一种方法是万能的。选择合适的方法应该基于具体问题的特征,如数据的复杂性、噪声水平、可用的计算资源等。在实际应用中,可能需要结合多种方法并进行交叉验证,以确保结果的可靠性。
本研究的方法和发现可能对多个领域的研究者有所帮助,特别是在处理稀疏且噪声较大的时间序列数据时。例如,在生物过程工程、金融市场分析或环境监测等领域,这些技术可能会提供更准确的动态系统行为洞察。
对于那些希望深入了解符号回归在优化问题中应用的读者,我们建议参考相关的研究文献。特别地,Guimerà等人(2020)的工作为本文所用的BMS算法奠定了基础。此外,Forster等人(2024)和de Carvalho Servia(2024)的研究进一步展示了符号回归在复杂系统建模中的应用潜力。
最后,值得强调的是,本文介绍的方法并非旨在替代传统的数据分析技术,而是作为一种补充工具,特别是在处理具有挑战性的数据集时。研究者应该根据具体问题的需求和约束条件,选择最合适的方法或方法组合。
未来研究方向
基于本研究的结果,我们可以提出几个潜在的未来研究方向:
- 方法的鲁棒性分析: 对不同类型和程度的噪声,以及不同的采样频率进行系统的测试,以评估各种方法的鲁棒性。
- 自适应算法开发: 开发能够根据数据特征自动选择最佮算法或参数的智能系统。
- 计算效率优化: 特别是对于符号回归方法,研究如何提高其计算效率,使其能够处理更大规模的数据集。
- 与机器学习方法的结合: 探索将本文介绍的方法与深度学习等先进机器学习技术结合的可能性。
- 跨领域应用研究: 在更多不同的科学和工程领域测试这些方法,以验证其通用性和限制。
参考文献
- What is Machine Learning? A Primer for the Epidemiologist
- Stock Market Prediction via Deep Learning Techniques: A Survey
- Demand forecasting model for time-series pharmaceutical data using shallow and deep neural network model
- A Bayesian machine scientist to aid in the solution of challenging scientific problems
- Application of symbolic regression for constitutive modeling of plastic deformation