
大语言模型(LLM)的推理能力可以通过测试时聚合策略来改进,即为每个问题生成多个样本并对它们进行聚合以找到更好的答案。这些方法往往会达到饱和点,超过这个点后额外的样本不会带来更多收益。精炼(refinement)提供了另一种选择,它使用模型生成的反馈不仅采样更多解决方案,还提高它们的质量。但是精炼引入了三个关键挑战:
(1)过度精炼:对所有实例进行统一精炼可能导致过度校正并降低整体性能。
(2)无法定位和解决错误:LLM自我纠正能力有限,难以以有针对性的方式识别和纠正自己的错误。
(3)精炼不足:确定需要多少轮精炼并非易事,过早停止可能会导致错误未得到解决。
为了解决这些问题,论文提出了MAGICORE,一个用于粗到细精炼的多代理迭代框架。MAGICORE旨在通过将问题分类为简单或困难,为简单问题使用粗粒度聚合,为困难问题使用细粒度和迭代多代理精炼,从而避免过度精炼。
主要贡献
- 提出了MAGICORE,一个多代理粗到细框架,自适应地使用有针对性的反馈,在所有样本预算下都优于Self-Refine等精炼方法,以及Best-of-k和Self-Consistency等聚合方法,跨五个数据集和两个LLM模型都取得了优异表现。
- 所提出的难度感知粗到细资源分配方法具有样本效率,即使使用8倍少的样本也优于k-way SC。
- 分析表明纳入奖励模型(RM)用于精炼是必要的,相比训练好的现成RM,LLM单独在确定何时需要精炼方面效果较差。
- 验证了虽然所使用的精炼基线在多次迭代中没有显示出改进,但MAGICORE随着额外迭代持续改进。
精炼面临的问题
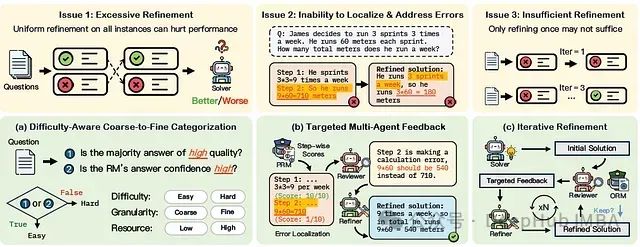
- 问题1:过度精炼- 精炼存在过度校正的风险,可能将正确的解决方案变成错误的。
- 问题2:无法定位和解决错误- LLM自我纠正能力有限,难以以有针对性的方式识别和纠正自己的错误。
- 问题3:精炼不足- 有效的精炼应该逐步改善输出,但过早停止可能会导致错误未得到纠正。
Magicore:自适应粗到细精炼框架
MAGICORE是一个自适应框架,旨在通过智能应用测试时聚合和精炼来改进LLM多步推理的性能和效率。
MAGICORE框架
MAGICORE框架包含三个模型:
- 具有三个角色的LLM:Solver(用于生成初始解决方案)、Reviewer(用于生成有针对性的反馈)和Refiner(用于精炼)。
- 结果奖励模型(ORM),用于生成全局、解决方案级别的正确性分数。
- 过程奖励模型(PRM),用于生成局部的逐步正确性分数。
框架概述
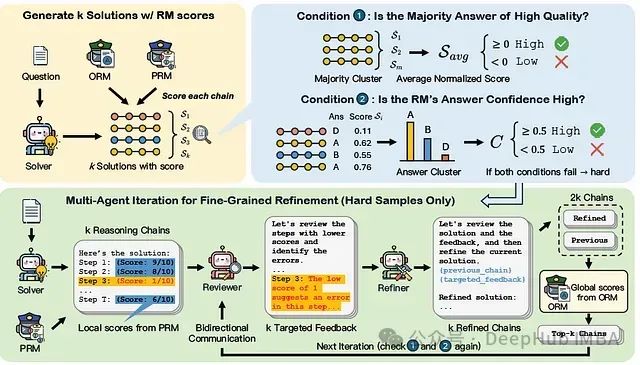
- 过程从Solver为每个问题生成k个推理链开始,然后ORM和PRM提供解决方案级别的分数。
- 接下来,根据两个标准对输入问题的难度进行分类:(1)多数答案的质量和(2)RM的答案置信度。
- 只有当问题被认为是困难的时候才启动精炼,这发生在多数答案获得低平均RM分数且答案分布平坦的情况下 - 表明没有单个答案明显优于其他答案(即低置信度)。
- 对于这些困难问题,论文采用具有三个代理的多代理设置:Solver、Reviewer和Refiner。
- Solver生成k个推理链,将它们传递给PRM进行逐步评分以确定错误。
- Reviewer将分数转化为有针对性的反馈,Refiner使用Reviewer的反馈改进先前生成的k个解决方案。
- 这个审查-精炼通信循环重复进行,直到满足两个条件之一,或达到最大迭代次数。
问题难度分类和粗细方法分配
条件1:多数答案质量是否高?
- 为评估问题难度,Solver为输入问题生成k个解决方案并按最终答案进行分组。
- 从最大的解决方案簇中,论文计算平均RM分数并通过所有解决方案的平均分数进行归一化,表示为Savg。
- 归一化后,如果Savg大于0,条件1为真,意味着多数答案已经是高质量的,因此不需要精炼。如果更低,条件1为假,表明即使最频繁的答案也很差,因此生成的解决方案可能受益于精炼。
- 使用ORM和PRM分别进行相同的程序,如果任何一个RM给多数答案低分,条件1将为假。
条件2:奖励模型的答案置信度是否高?
- 检查RM是否对任何单个答案有信心。置信度由答案分布的集中程度决定(即,是否有一个簇突出)。
- 集中的分布表示高置信度,而分散的分布表示低置信度。答案分布由(1)每个唯一答案的频率和(2)每个答案簇的总RM分数形成。
- 每个答案簇按其聚合RM分数加权,类似于加权自一致性中使用的方法。
- 使用答案簇的熵计算置信度(表示为C)。如果C ≥ 0.5,条件2为真,意味着RM对一个答案有信心。如果C < 0.5,条件2为假,表示不确定性并需要进一步精炼。
粗到细决策
- 如果满足任一条件(答案质量高或RM对答案有信心),实例被委派给简单 - 或粗粒度 - 方法。
- 相反,如果两个条件都不满足,实例被委派给困难 - 或细粒度 - 方法。
细粒度多代理迭代精炼
- 通过将问题分类为简单或困难,并仅对困难问题解决方案应用精炼,论文缓解了过度精炼的问题,解决了"问题1"(过度精炼)。
- 论文通过采用具有三个代理的多代理设置来解决"问题2":(1)Solver,生成初始解决方案 (2)Reviewer,接受PRM分数和推理链作为输入,生成指出链中错误的有针对性反馈,以及(3)Refiner,接受Reviewer生成的反馈来精炼先前的链。
- 为了解决"问题3"(精炼不足),论文迭代精炼过程直到找到充分的解决方案,细粒度精炼过程的详细信息如下:
Solver生成k个解决方案
- MAGICORE从为给定问题生成k个解决方案开始,这在前一步中已完成。
- 对于被分类为困难的问题,可以直接重用Solver已经生成的k个推理链。
Reviewer生成有针对性的反馈
- 为了定位和解决错误,使用PRM评估每个生成的解决方案并分配局部逐步分数。
- 这些分数被附加到每个步骤的末尾,结果发送给Reviewer。
- Reviewer的目标是整合来自PRM的逐步正确性分数以生成可操作的反馈,因为它接受带有PRM分数的链作为输入,并被提示识别需要精炼的有问题步骤以及可能的修复方法。
Refiner基于有针对性的反馈改进解决方案
- Refiner然后使用Reviewer提供的有针对性反馈来增强Solver最初生成的推理链。
- 通过突出推理链中的特定错误,有针对性的反馈使Refiner能够更有效地解决错误,因为它清楚地识别出哪些步骤是不正确的;这可以帮助模型纠正错误。
迭代精炼过程以实现双向通信
- 对于一些困难实例,一轮精炼可能不够;因此跨多轮迭代精炼过程,在Reviewer和Refiner之间创建通信循环,Refiner的输出在下一轮返回给Reviewer。
最终答案选择
- 上述精炼过程同时对所有k个链进行操作,在每次迭代中产生k个精炼链。
- 在每次迭代结束时,论文使用ORM根据其全局正确性分数评估精炼解决方案是否有所改进,这意味着到每次迭代结束时,论文有2k个推理链 - k个初始和k个精炼 - 但仅保留基于其全局ORM分数的前k个。
- 这里论文选择基于ORM分数做决定,因为有针对性的反馈是用PRM的逐步分数生成的,所以通过另一个评分模型选择解决方案可以避免过拟合。
- 最后,在每次迭代结束时,使用这些保留的前k个链上的加权自一致性选择答案。
评估结果
主要结果
下表展示了不同方法和模型的性能比较:
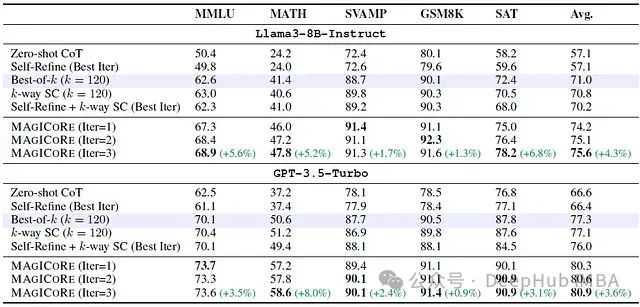
- MAGICORE在第一次迭代就优于所有基线。
- 与生成多个响应但不进行精炼的基于聚合的方法相比,论文观察到MAGICORE在第一次迭代后,在Llama-3-8B上平均跨五个数据集改进了3.2%(绝对值),尽管使用的样本减少了2倍。
- 与120路SC相比,论文的方法在Llama-3-8B上显示出更大的平均改进3.3%,在GPT-3.5上为3.2%。转向基于精炼的方法,论文与不进行聚合的Self-Refine进行比较,其中每次迭代在单个实例上操作。
- 平均而言,MAGICORE在Llama-3-8B和GPT-3.5上分别相对于SR显示出17.1%和13.5%的改进。
- 与SR + SC的最佳迭代相比,MAGICORE平均优于SR + SC 5.4%(Llama-3-8B)和4.9%(GPT-3.5)。
下图显示了MAGICORE、Best-of-k和Self-Refine + k-way SC (SR + SC)在迭代中的比较,平均跨五个数据集:
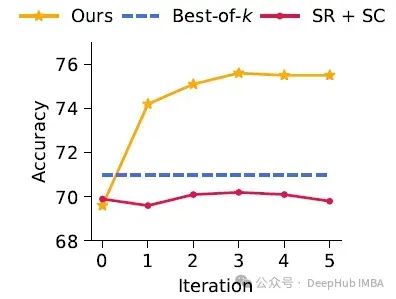
- 随着迭代次数的增加,论文观察到MAGICORE性能有明显的上升趋势。
下图显示了MAGICORE、k-way SC和Best-of-k在MATH上不同k的比较:
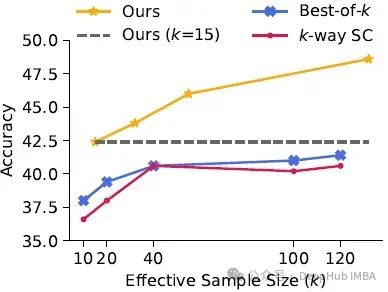
- 上图显示MAGICORE在任何给定k下始终优于k-way SC和Best-of-k。
分析
选择性精炼避免过度校正并改善整体性能
下表显示了在统一采用聚合(即加权SC)或对所有实例进行精炼时的比较:
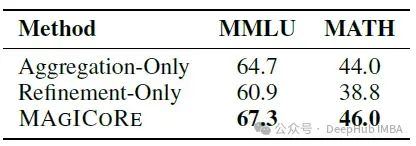
- 观察到统一应用精炼实际上降低了性能;将加权SC(第1行的"仅聚合")与仅精炼(第2行)进行比较,论文看到对所有样本进行精炼导致MMLU和MATH分别下降3.8%和5.2%,这指出了过度校正问题。
- 相反,论文的选择性精炼的一次迭代(第3行)只针对加权多数投票不太可能成功的具有挑战性的实例,与统一应用聚合(第1行)相比,结果提高了高达2.6%。
基于PRM的有针对性反馈能够更好地精炼
下表显示了MAGICORE中不同精炼变体的比较:

- 使用LLM的自我精炼(第1行)导致平均下降1.5%,表明使用LLM进行精炼不如使用PRM有效。
- 总的来说,MAGICORE使用来自PRM的逐步反馈的方法对精炼最有效。
MAGICORE的两个条件用于分类问题难度比提示LLM或任何单独条件更有效
下表显示了检测困难问题的不同方法的比较:
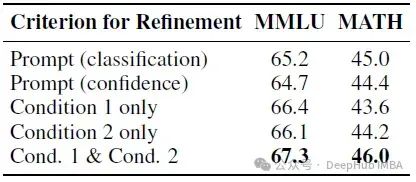
- 结果显示,与奖励模型相比,LLM在确定实例难度方面效果较差,表现为性能下降1.6%-2.6%。
分离Reviewer和Refiner角色比组合这些角色表现更好
下表检查了通过合并Reviewer和Refiner的提示来组合它们的角色的效果,指示模型同时生成反馈和精炼解决方案:
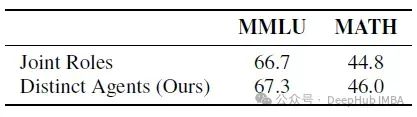
- 在MAGICORE中,Reviewer和Refiner具有不同的、明确定义的角色,论文将其称为"不同代理"方法。
- 研究结果表明,保持单独的角色(如论文的多代理设置中)会带来更好的性能,而"联合角色"配置在MMLU上导致0.6%的下降,在MATH上导致1.2%的下降。
性能提升评价指标
MAGICORE的性能提升主要通过以下指标进行评估:
- 与基线方法的准确率比较:- 在第一次迭代后,MAGICORE就优于所有基线方法。- 与Best-of-120相比,在Llama-3-8B上平均跨五个数据集改进了3.2%,尽管使用的样本减少了2倍。- 与120-way SC相比,在Llama-3-8B上平均改进3.3%,在GPT-3.5上改进3.2%。
- 与精炼方法的比较:- 与Self-Refine(SR)相比,MAGICORE在Llama-3-8B和GPT-3.5上分别平均改进17.1%和13.5%。- 与SR + SC的最佳迭代相比,MAGICORE平均优于5.4%(Llama-3-8B)和4.9%(GPT-3.5)。
- 迭代性能:- MAGICORE随着迭代次数的增加持续改进,而基线方法在多次迭代中没有显示出改进。
- 样本效率:- 即使使用8倍少的样本,MAGICORE也优于k-way SC。
- 难度分类准确性:- MAGICORE的问题难度分类方法比LLM直接分类更准确,导致更好的性能。
- 多代理设置的效果:- 保持Reviewer和Refiner的单独角色比组合这些角色带来更好的性能。
这些评价指标全面地展示了MAGICORE在各个方面的性能提升,包括准确率、样本效率、迭代改进能力,以及在不同类型问题上的表现。
总结
本文介绍了MAGICORE,这是一种自适应地为更具挑战性的问题分配更多计算资源,并在适当的地方(即困难问题上)有选择地应用精炼的方法。MAGICORE解决了精炼中的三个关键问题:简单示例上的过度精炼、LLM无法检测和纠正其推理中的错误,以及困难实例上的精炼不足。
在五个数学数据集和两个模型上的结果表明,论文的粗到细方法在任何给定预算下都始终优于单独的粗粒度聚合和细粒度精炼,甚至优于使用大量更多计算的基线。