
Deephub
更多文章请关注公众号:Deephub-IMBA
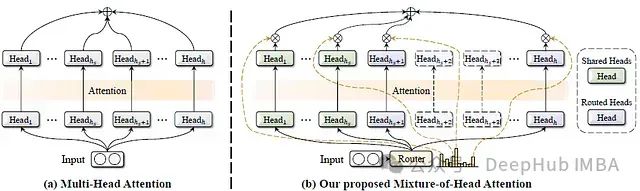
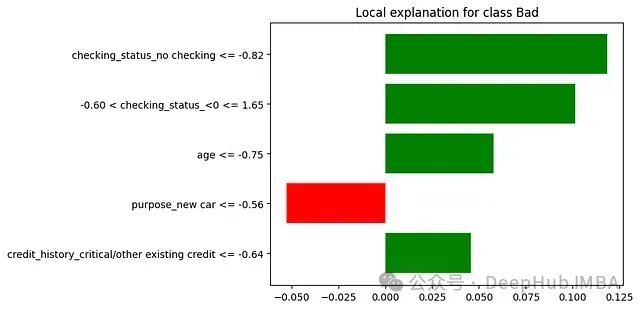
MoH:融合混合专家机制的高效多头注意力模型及其在视觉语言任务中的应用
这篇论文提出了一种名为混合头注意力(Mixture-of-Head attention, MoH)的新架构,旨在提高注意力机制的效率,同时保持或超越先前的准确性水平。
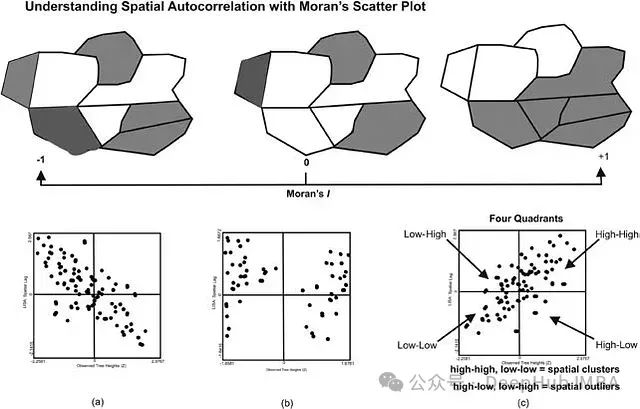
机器学习中空间和时间自相关的分析:从理论基础到实践应用
空间和时间自相关是数据分析中的两个基本概念,它们揭示了现象在空间和时间维度上的相互依赖关系。

特征工程在营销组合建模中的应用:基于因果推断的机器学习方法优化渠道效应估计
因果推断方法为特征工程提供了一个更深层次的框架,使我们能够区分真正的因果关系和简单的统计相关性。

lintsampler:高效从任意概率分布生成随机样本的新方法
``` lintsampler ``` 是一个纯Python实现的库,能够高效地从任意概率分布中生成随机样本。

基于OpenFOAM和Python的流场动态模态分解:从数据提取到POD-DMD分析
本文探讨了Python脚本与动态模态分解(DMD)的结合应用。我们将利用Python对从OpenFOAM模拟中提取的二维切片数据进行DMD计算。这种方法能够有效地提取隐藏的流动模式,深化对流体动力学现象的理解。
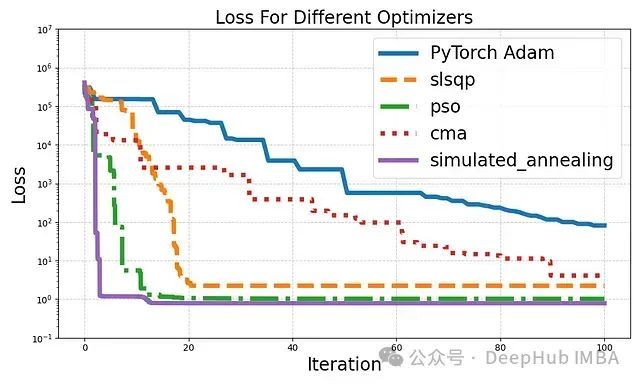
如果你的PyTorch优化器效果欠佳,试试这4种深度学习中的高级优化技术吧
在深度学习领域,优化器的选择对模型性能至关重要。

信息论、机器学习的核心概念:熵、KL散度、JS散度和Renyi散度的深度解析及应用
本文深入探讨了信息论、机器学习和统计学中的几个核心概念:熵、KL散度、Jensen-Shannon散度和Renyi散度。这些概念不仅是理论研究的基石,也是现代数据分析和机器学习应用的重要工具。

数据准备指南:10种基础特征工程方法的实战教程
特征工程是将原始数据转化为更具信息量的特征的过程。本文将详细介绍十种基础特征工程技术,包括其基本原理和实现示例。

三种Transformer模型中的注意力机制介绍及Pytorch实现:从自注意力到因果自注意力
本文深入探讨Transformer模型中三种关键的注意力机制:自注意力、交叉注意力和因果自注意力。我们不仅会讨论理论概念,还将使用Python和PyTorch从零开始实现这些注意力机制。
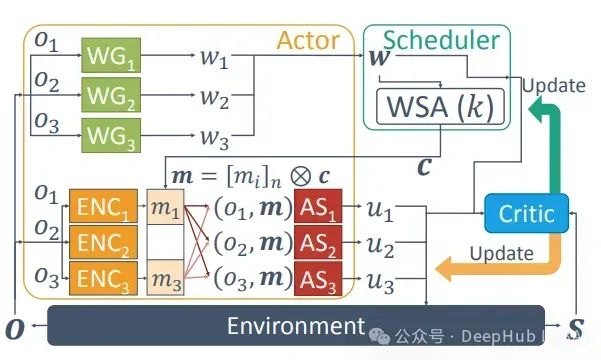
多代理强化学习综述:原理、算法与挑战
多代理强化学习是强化学习的一个子领域,专注于研究在共享环境中共存的多个学习代理的行为。每个代理都受其个体奖励驱动,采取行动以推进自身利益
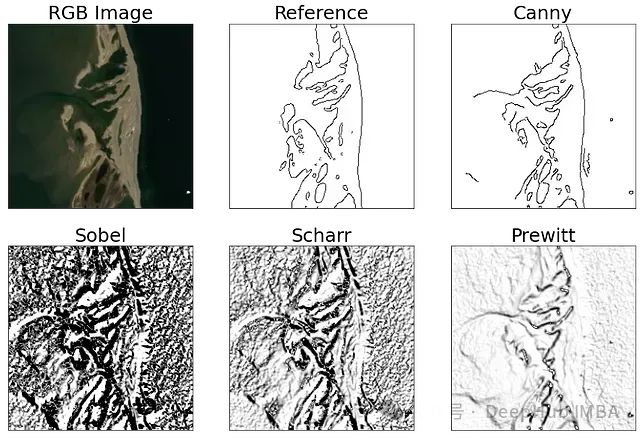
边缘检测评估方法:FOM、RMSE、PSNR和SSIM对比实验和理论研究
本文通过理论分析和实证实验,明确展示了FOM在边缘检测评估中的优越性。相比之下,RMSE、PSNR和SSIM在这一任务中表现出明显的局限性。
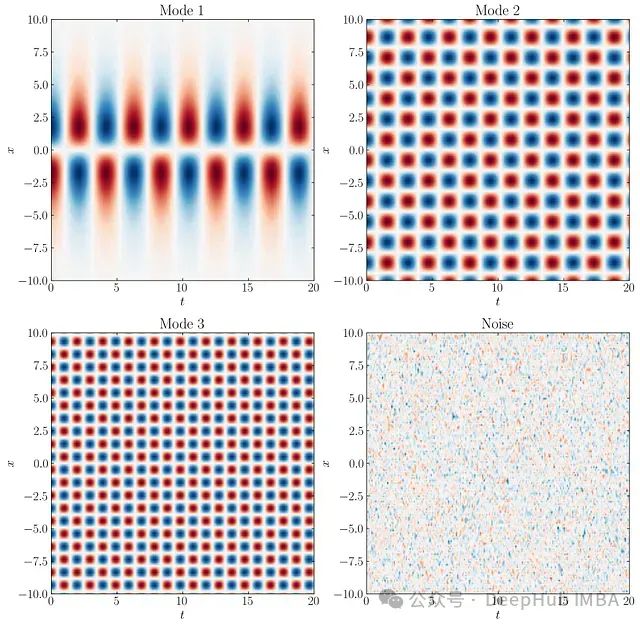
稀疏促进动态模态分解(SPDMD)详细介绍以及应用
在机器学习和人工智能领域,SPDMD的应用场景广泛。它可用于图像处理和计算机视觉中的特征提取和降维.在时间序列分析中,SPDMD可以识别复杂数据中的主要趋势和周期性模式
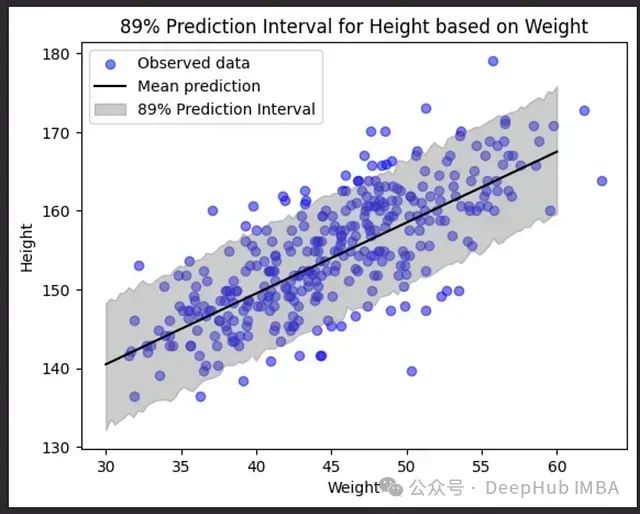
贝叶斯线性回归:概率与预测建模的融合
贝叶斯线性回归提供了一个强大的框架,用于理解和量化变量之间的关系。通过引入先验分布和考虑参数的不确定性,这种方法不仅能给出点估计,还能提供完整的后验分布,从而更全面地描述我们的知识状态。

图像数据增强库综述:10个强大图像增强工具对比与分析
本文旨在全面介绍当前广泛使用的图像数据增强库,分析其特点和适用场景,以辅助研究人员和开发者选择最适合其需求的工具。
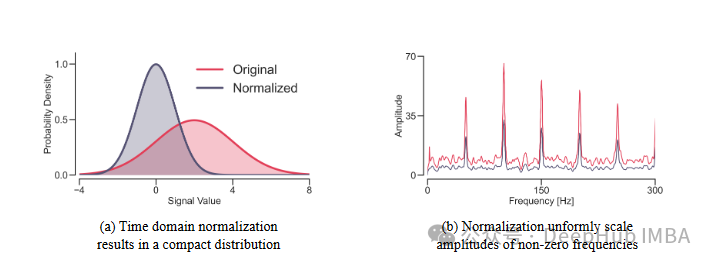
FredNormer: 非平稳时间序列预测的频域正则化方法
FredNormer的核心思想是从频率角度观察数据集,并自适应地增加关键频率分量的权重。
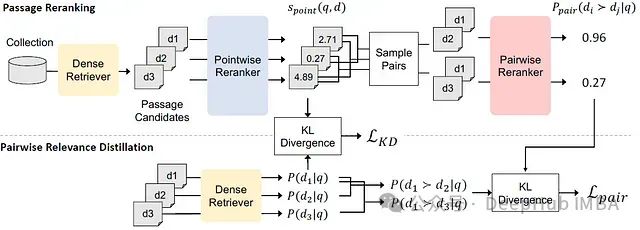
PAIRDISTILL: 用于密集检索的成对相关性蒸馏方法
成对相关性蒸馏(Pairwise Relevance Distillation, PAIRDISTILL)。
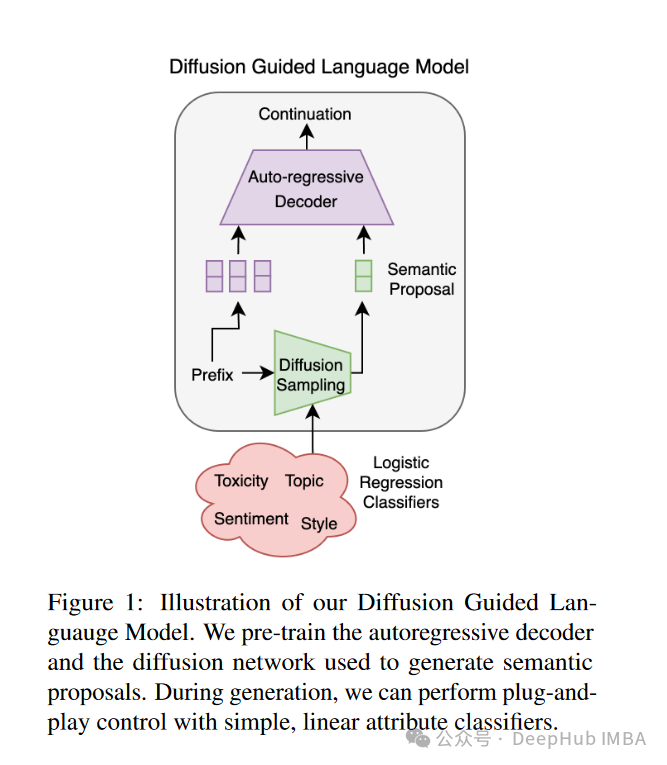
扩散引导语言建模(DGLM):一种可控且高效的AI对齐方法
扩散引导语言建模(Diffusion Guided Language Modeling, DGLM)。DGLM旨在结合自回归生成的流畅性和连续扩散的灵活性,为可控文本生成提供一种更有效的方法。
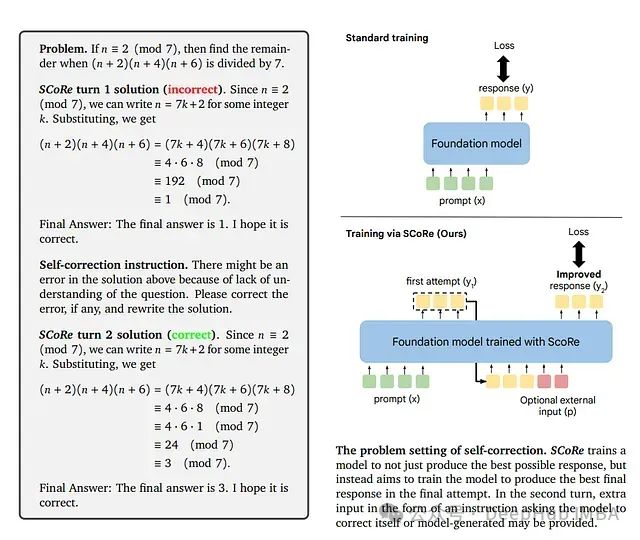
SCoRe: 通过强化学习教导大语言模型进行自我纠错
这是谷歌9月发布在arxiv上的论文,研究者们提出了一种新方法**自我纠错强化学习(SCoRe)**,旨在使大语言模型能够在没有任何外部反馈或评判的情况下"即时"纠正自己的错误。

VisionTS:基于时间序列的图形构建高性能时间序列预测模型,利用图像信息进行时间序列预测
本文将讨论以下几个方面: - 图像如何在内部编码序列信息? - 利用预训练计算机视觉模型进行时间序列分析的概念 - ***VisionTS***:一种适用于时间序列数据的预训练Vision Transformer模型。