
在机器学习领域,特征重要性分析是一种广泛应用的模型解释工具。但是特征重要性并不等同于特征质量。本文将探讨特征重要性与特征有效性之间的关系,并引入两个关键概念:预测贡献度和错误贡献度。
核心概念
- 预测贡献度:衡量特征在模型预测中的权重,反映模型在训练集上识别的模式。这与传统的特征重要性概念相似。
- 错误贡献度:衡量特征在模型在验证集上产生错误时的权重。这更能反映特征在新数据上的泛化能力。
本文将详细阐述这两个概念的计算方法,并通过实例展示基于错误贡献度的特征选择如何优于传统的基于预测贡献度的方法。
基础概念示例
考虑一个二元分类问题:预测个人年收入是否超过10万美元。假设我们已有模型预测结果:

预测贡献度和错误贡献度的计算主要基于两个要素:
- 模型对每个样本的预测误差
- 每个样本的SHAP(SHapley Additive exPlanations)值
接下来,我们将深入探讨这两个关键问题:
- 分类模型中应采用何种误差度量?
- 如何处理分类模型中的SHAP值?
分类模型中的错误度量选择
在分类模型中,选择合适的误差度量至关重要。我们需要一个能在样本级别计算并可在整个数据集上聚合的度量指标。
对数损失(又称交叉熵)是分类问题中常用的损失函数,其数学表达式如下:
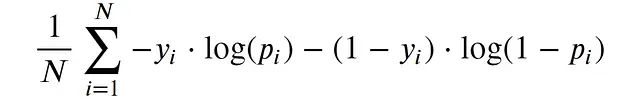
对数损失适合我们的需求,因为:
- 公式外部是简单的平均操作
- 作为损失函数,其值越低越好,符合误差的概念
为了更直观地理解对数损失,我们可以关注单个样本的贡献:
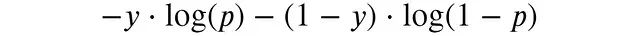
在二元分类问题中,y只能取0或1,因此可以简化为:
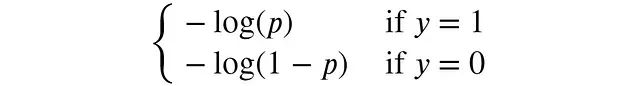
通过可视化可以更好地理解对数损失的特性:
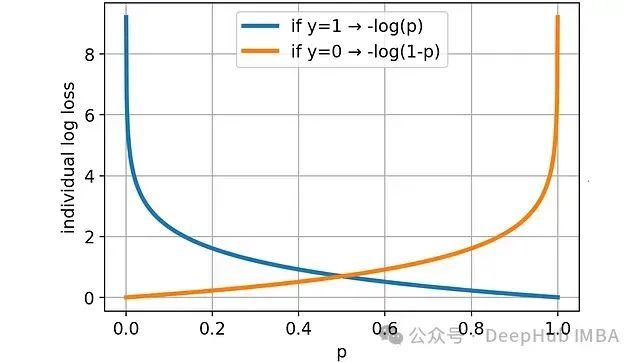
预测概率越偏离真实值(0或1),损失越大。且当预测严重偏离时(如预测0.2而实际为1,或预测0.8而实际为0),损失增长速度超过线性。
以下是计算单样本对数损失的Python实现:
defindividual_log_loss(y_true, y_pred, eps=1e-15):
"""计算单个样本的对数损失"""
y_pred=np.clip(y_pred, eps, 1-eps)
return-y_true*np.log(y_pred) - (1-y_true) *np.log(1-y_pred)
应用到我们的示例数据集:

可以观察到,样本1和2的对数损失较小,因为预测接近实际值;而样本0的对数损失较大。
分类模型中SHAP值的处理方法
在树模型(如XGBoost、LightGBM和CatBoost)中,计算SHAP值相对简单:
fromshapimportTreeExplainer
shap_explainer=TreeExplainer(model)
shap_values=shap_explainer.shap_values(X)
假设我们得到以下SHAP值:
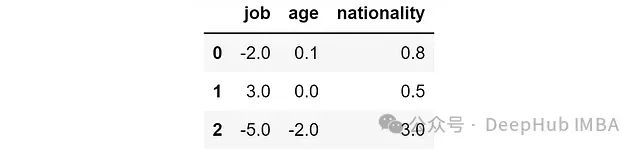
SHAP值的基本解释:
- 正值表示该特征增加了预测概率
- 负值表示该特征降低了预测概率
SHAP值之和与模型预测直接相关,但并不等于预测概率(介于0和1之间)。所以我们需要一个函数将SHAP值之和转换为概率,该函数应满足:
- 将任意实数映射到[0,1]区间
- 严格单调递增
Sigmoid函数满足这些要求。因此模型对特定样本的预测概率等于该样本SHAP值之和的Sigmoid函数值。
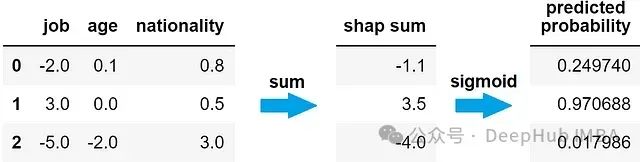
Sigmoid函数图像:
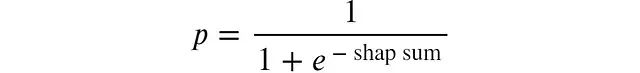
Python实现:
defshap_sum2proba(shap_sum):
"""将SHAP值之和转换为预测概率"""
return1/ (1+np.exp(-shap_sum))
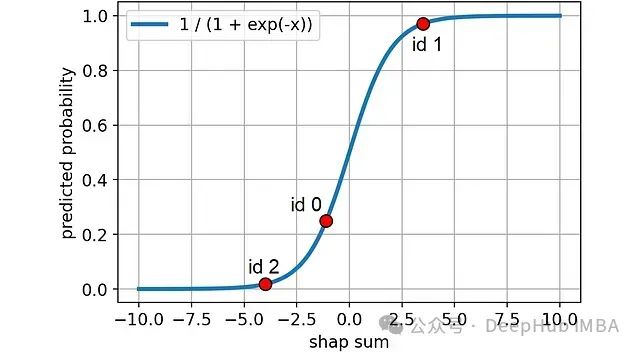
下图示例中的样本在Sigmoid曲线上的位置:
接下来,我们将详细讨论预测贡献度和错误贡献度的计算方法。
预测贡献度的计算
预测贡献度反映了特征对模型最终预测的影响程度。当一个特征的SHAP值绝对值较大时,表明该特征对预测结果有显著影响。因此可以通过计算特征SHAP值的绝对值平均来量化预测贡献度。
实现代码如下:
prediction_contribution=shap_values.abs().mean()
应用到我们的示例数据集,得到以下结果:

从结果可以看出,就特征重要性而言,job是最主要的特征,其次是nationality,然后是age。
错误贡献度的计算
错误贡献度旨在评估移除某个特征后模型错误的变化。利用SHAP值,我们可以模拟特征缺失的情况:从SHAP值总和中减去特定特征的SHAP值,然后应用Sigmoid函数,即可得到模型在缺少该特征时的预测概率。
实现代码如下:
y_pred_wo_feature=shap_values.apply(lambdafeature: shap_values.sum(axis=1) -feature).applymap(shap_sum2proba)
应用到示例数据集的结果:
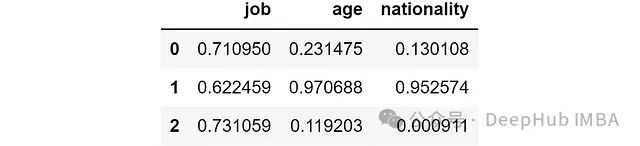
解读结果:
- 如果没有job特征,模型对三个样本的预测概率分别为71%、62%和73%。
- 如果没有nationality特征,预测概率分别为13%、95%和0%。
可以看出,预测结果对特征的依赖程度各不相同。接下来我们计算移除特征后的对数损失:
ind_log_loss_wo_feature=y_pred_wo_feature.apply(lambdafeature: individual_log_loss(y_true=y_true, y_pred=feature))
结果如下:
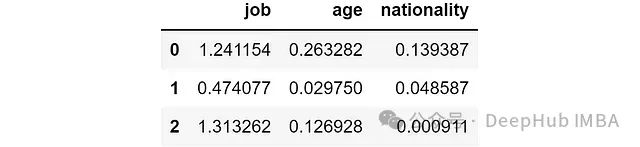
对第一个样本而言,移除job特征会导致对数损失增加到1.24,而移除nationality特征只会使对数损失增加到0.13。
为了评估特征的影响,我们可以计算完整模型的对数损失与移除特征后对数损失的差值:
ind_log_loss=individual_log_loss(y_true=y_true, y_pred=y_pred)
ind_log_loss_diff=ind_log_loss_wo_feature.apply(lambdafeature: ind_log_loss-feature)
结果如下:
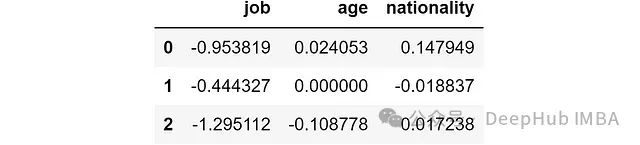
结果解读如下:
- 负值表示特征的存在减少了预测错误,对该样本有积极影响。
- 正值表示特征的存在增加了预测错误,对该样本有消极影响。
最后计算每个特征的错误贡献度,即这些差值的平均值:
error_contribution=ind_log_loss_diff.mean()
结果如下:
结果解读:
- 负值表示特征总体上有积极影响,减少了模型的平均错误。
- 正值表示特征总体上有消极影响,增加了模型的平均错误。
在这个例子中,job特征的存在平均减少了0.897的对数损失,而nationality特征的存在平均增加了0.049的对数损失。尽管nationality是第二重要的特征(根据预测贡献度),但它实际上略微降低了模型性能。
实际数据集应用案例
我们将使用一个名为"Gold"的金融时间序列数据集来演示这些概念的实际应用。该数据集来源于Pycaret库。
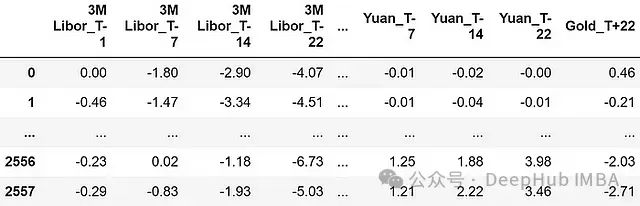
特征说明:
- 所有特征都表示为百分比回报率
- 特征包括金融资产在观察时刻前22、14、7和1天的回报率(分别标记为"T-22"、"T-14"、"T-7"、"T-1")
完整的预测特征列表如下:

总共有120个特征。
预测目标:预测22天后黄金回报率是否会超过5%。因此,这是一个二元分类问题:
- 0:22天后黄金回报率小于或等于5%
- 1:22天后黄金回报率大于5%
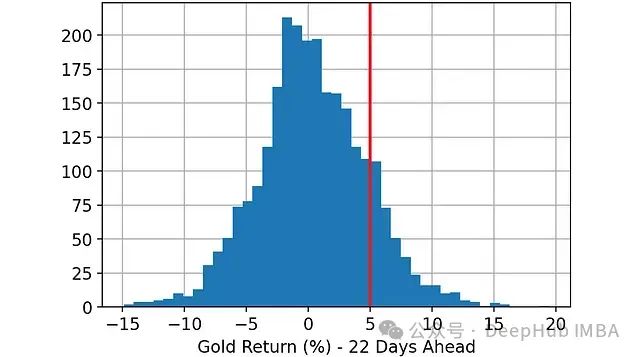
实验步骤:
- 随机划分数据集:33%用于训练,33%用于验证,34%用于测试。
- 使用训练集训练LightGBM分类器。
- 在训练、验证和测试集上进行预测。
- 使用SHAP库计算各数据集的SHAP值。
- 计算每个特征在各数据集上的预测贡献度和错误贡献度。
分析结果:
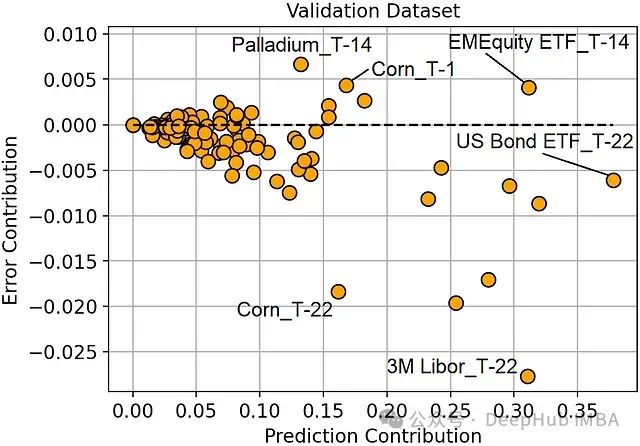
图:验证集上的预测贡献度vs错误贡献度
主要发现:
- 美国债券ETF在T-22时点是最重要的特征,但它并未带来显著的错误减少。
- 3个月Libor在T-22时点是最有效的特征,因为它最大程度地减少了错误。
- 玉米价格在T-1和T-22时点都是重要特征,但T-1时点的特征存在过拟合现象(增加了预测错误)。
- 总体而言,T-1或T-14时点的特征错误贡献度较高,而T-22时点的特征错误贡献度较低。这表明较近期的特征可能更容易导致过拟合,而较早期的特征可能具有更好的泛化能力。
这些发现为我们提供了宝贵的模型洞察,并为特征选择提供了新的思路。下一节我们将探讨如何利用错误贡献度进行特征选择。
验证:基于错误贡献度的递归特征消除
递归特征消除(Recursive Feature Elimination,RFE)是一种迭代式特征选择方法,通过逐步移除特征来优化模型性能。本节将比较基于预测贡献度和错误贡献度的RFE方法。
RFE算法概述:
- 初始化特征集
- 使用当前特征集训练模型
- 评估各特征的重要性或贡献度
- 移除"最差"特征
- 重复步骤2-4,直到达到预定的特征数量或性能标准
传统RFE vs. 基于错误贡献度的RFE:
- 传统RFE:移除预测贡献度最低的特征
- 基于错误贡献度的RFE:移除错误贡献度最高的特征
实验结果
验证集上的对数损失比较:
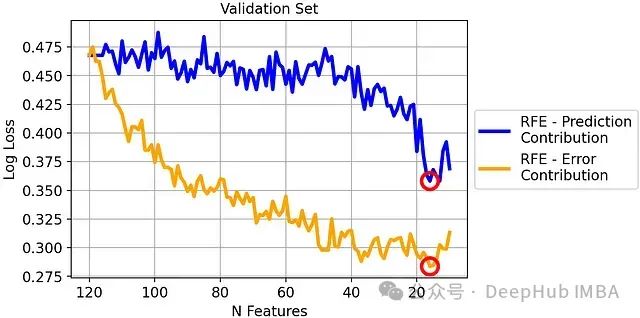
基于错误贡献度的RFE在验证集上显著优于传统RFE。
测试集上的对数损失比较:
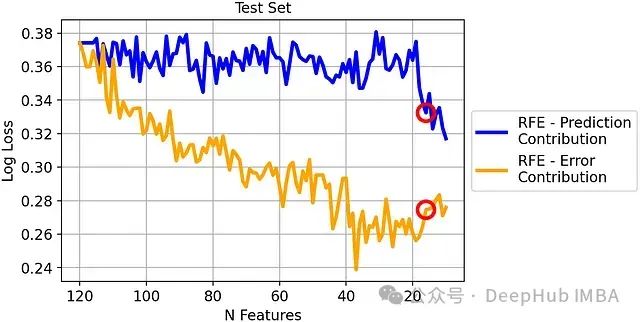
尽管差异相对减小,但基于错误贡献度的RFE在测试集上仍然优于传统RFE,证明了其更好的泛化能力。
验证集上的平均精度比较:
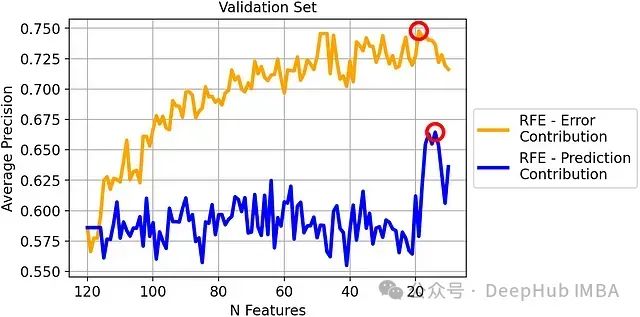
尽管错误贡献度是基于对数损失计算的,但在平均精度这一不同的评估指标上,基于错误贡献度的RFE仍然表现出色。
根据验证集性能,我们选择:
- 基于错误贡献度的RFE:19个特征的模型
- 基于预测贡献度的RFE:14个特征的模型
测试集上的平均精度比较:
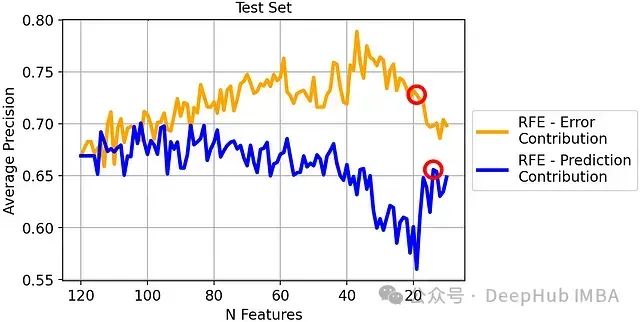
最终结果:
- 基于错误贡献度的RFE(19个特征):72.8%的平均精度
- 基于预测贡献度的RFE(14个特征):65.6%的平均精度
基于错误贡献度的RFE在测试集上获得了7.2个百分点的性能提升,这是一个显著的改进。
总结
本研究深入探讨了机器学习模型中特征重要性的概念,并提出了区分特征重要性和特征有效性的新方法。
- 引入了预测贡献度和错误贡献度两个概念,为特征评估提供了新的视角。
- 详细阐述了基于SHAP值计算这两种贡献度的方法,为实践应用提供了可操作的指导。
- 通过金融数据集的案例分析,展示了错误贡献度在特征选择中的实际应用价值。
- 证明了基于错误贡献度的递归特征消除方法可以显著提高模型性能,在测试集上实现了7.2%的平均精度提升。
通过深入理解特征的预测贡献和错误贡献,数据科学家可以构建更加稳健和高效的机器学习模型,为决策制定提供更可靠的支持。