
Deephub
更多文章请关注公众号:Deephub-IMBA
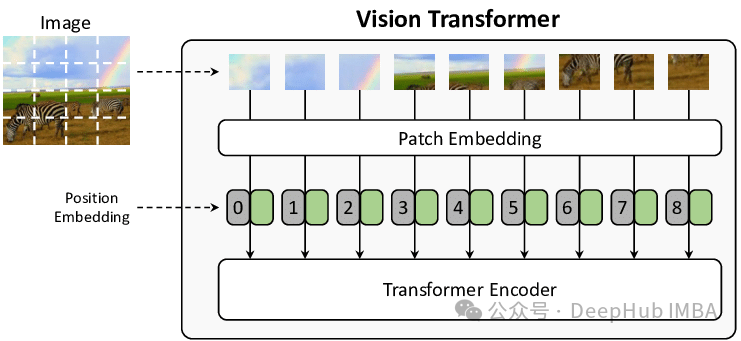
Vision Transformer中的图像块嵌入详解:线性投影和二维卷积的数学原理与代码实现
在 Vision Transformer 中,图像首先被分解为正方形图像块,然后将这些图像块展平为单个向量嵌入。这些嵌入可以被视为与文本嵌入(或任何其他嵌入)完全相同,甚至可以与其他数据类型进行连接。

STAR: 利用时空注意力机制和动态频率损失的视频超分辨率增强框架
STAR (Spatial-Temporal Augmentation with Text-to-Video Models) 提出了一种创新的视频超分辨率解决方案,针对现有模型中存在的过度平滑和时间一致性不足等问题进行了系统性改进。
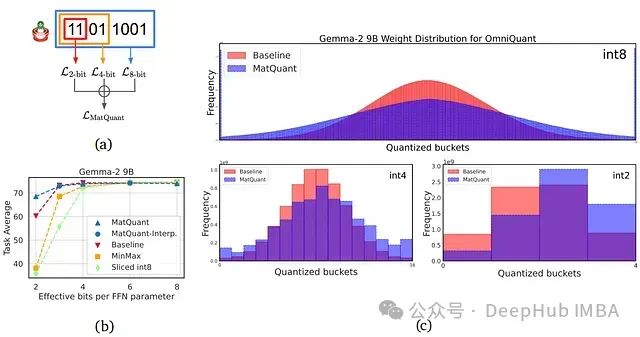
DeepMind发布Matryoshka(套娃)量化:利用嵌套表示实现多精度LLM的低比特深度学习
本文将介绍 Google DeepMind 提出的 Matryoshka 量化技术,该技术通过从单个大型语言模型 (LLM) 实现多精度模型部署,从而革新深度学习。我们将深入研究这项创新技术如何提高 LLM 的效率和准确性。
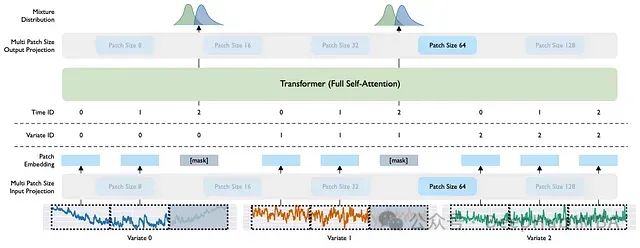
MOIRAI-MOE: 基于混合专家系统的大规模时间序列预测模型
MOIRAI-MOE 采用纯解码器架构,通过混合专家模型实现了频率无关的通用预测能力,同时显著降低了模型参数规模。
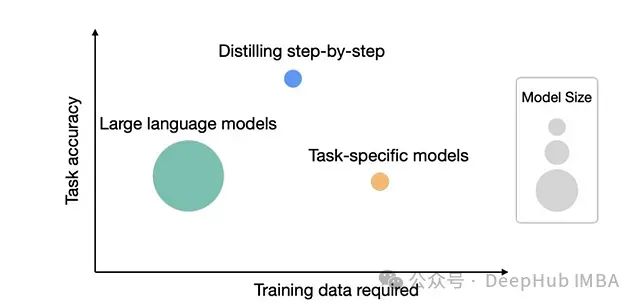
知识蒸馏方法探究:Google Distilling Step-by-Step 论文深度分析
Google Research 团队发表的论文《Distilling Step-by-Step!》提出了一种创新的知识蒸馏方法,不仅能有效减小模型规模,还能使学生模型在某些任务上超越其教师模型。
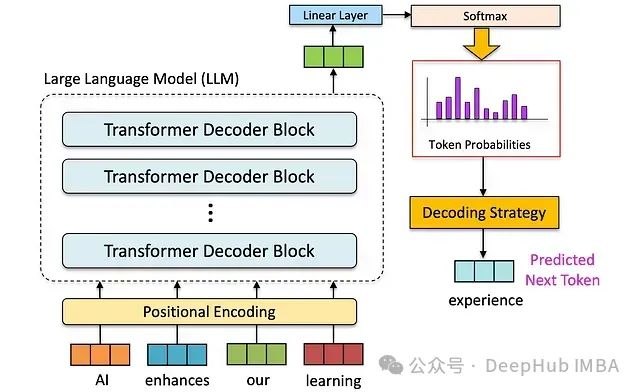
大语言模型的解码策略与关键优化总结
本文系统性地阐述了大型语言模型(Large Language Models, LLMs)中的解码策略技术原理及其实践应用。
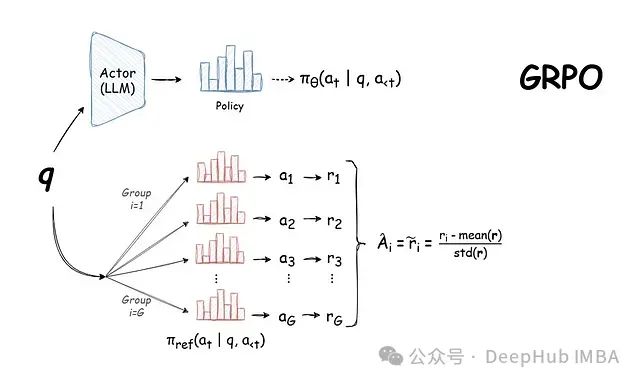
DeepSeek 背后的技术:GRPO,基于群组采样的高效大语言模型强化学习训练方法详解
本文将深入分析 GRPO 的工作机制及其在语言模型训练领域的重要技术突破,并探讨其在实际应用中的优势与局限性。

基于结构化状态空间对偶性的贝叶斯注意力机制设计与实现
本文介绍了一种贝叶斯风格的注意力机制,用于序列预测。我们将详细阐述如何使用马尔可夫链蒙特卡罗法(MCMC)训练该模型。
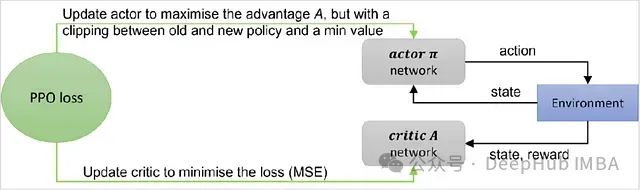
近端策略优化(PPO)算法的理论基础与PyTorch代码详解
近端策略优化(Proximal Policy Optimization, PPO)算法作为一种高效的策略优化方法,在深度强化学习领域获得了广泛应用。特别是在大语言模型(LLM)的人类反馈强化学习(RLHF)过程中,PPO扮演着核心角色。本文将深入探讨PPO的基本原理和实现细节。
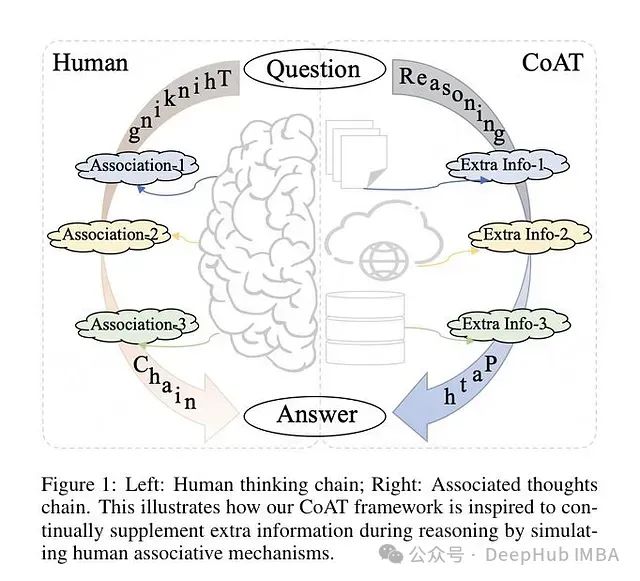
CoAT: 基于蒙特卡洛树搜索和关联记忆的大模型推理能力优化框架
研究者提出了一种新的关联思维链(Chain-of-Associated-Thoughts, CoAT)方法,该方法通过整合蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)和关联记忆机制来提升大语言模型(LLMs)的推理能力。
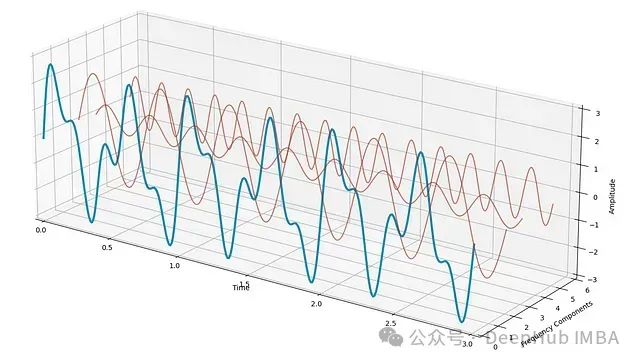
用傅里叶变换解码时间序列:从频域视角解析季节性模式
传统上,识别季节性模式往往依赖于数据的**可视化分析**。但是我们可以使用**傅里叶变换**以及**周期图**(Periodogram)这一强大工具,用一种更系统的方法来解决这个问题。

PyTorch Profiler 性能优化示例:定位 TorchMetrics 收集瓶颈,提高 GPU 利用率
本文是将聚焦于指标收集,演示指标收集的一种简单实现如何对运行时性能产生负面影响,并探讨用于分析和优化它的工具与技术。

DeepSeek × 时间序列 :DeepSeek-TS,基于状态空间增强MLA与GRPO的时序预测新框架
本文介绍 DeepSeek-TS,该框架受到 DeepSeek 中高效的多头潜在注意力(MLA)和群组相对策略优化(GRPO)技术的启发,并将其应用于多产品时间序列预测。
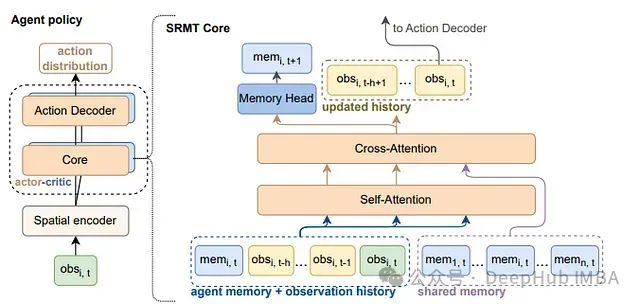
SRMT:一种融合共享记忆与稀疏注意力的多智能体强化学习框架
本研究将系统阐述**SRMT的技术架构、核心功能、应用场景及实验数据**,深入分析其在**多智能体强化学习(MARL)**领域的技术优势。
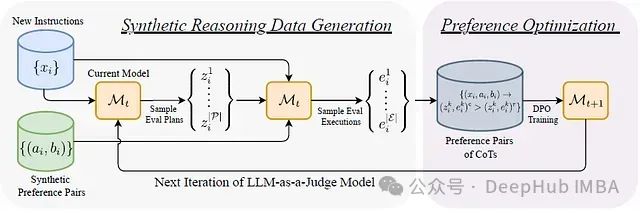
EvalPlanner:基于“计划-执行”双阶段的大语言模型评估框架
EvalPlanner[1],这是一种创新的LLM评估算法。该算法采用计划-执行的双阶段范式,首先生成无约束的评估计划,随后执行该计划并做出最终判断。这种方法显著提升了评估过程的系统性和可靠性。
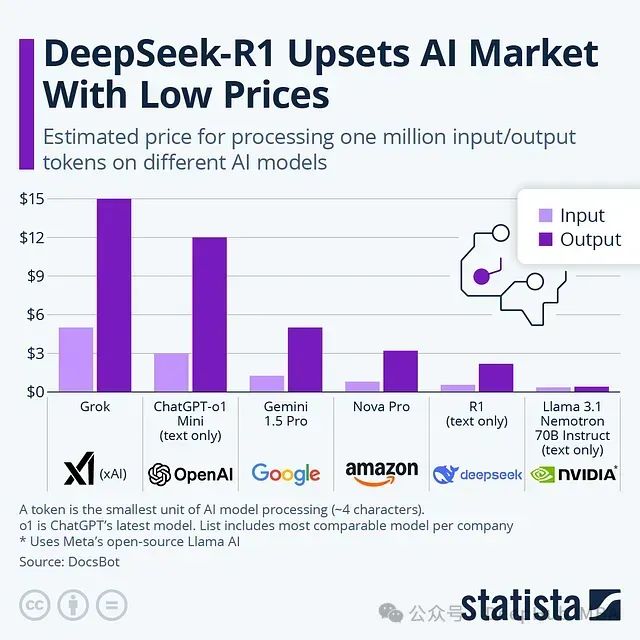
DeepSeek技术报告解析:为什么DeepSeek-R1 可以用低成本训练出高效的模型
DeepSeek-R1 通过创新的训练策略实现了显著的成本降低,同时保持了卓越的模型性能。本文将详细分析其核心训练方法。

数据降维技术研究:Karhunen-Loève展开与快速傅里叶变换的理论基础及应用
在现代科学计算和数据分析领域,数据降维与压缩技术对于处理高维数据具有重要意义。
PyTorch生态系统中的连续深度学习:使用Torchdyn实现连续时间神经网络
神经常微分方程(Neural ODEs)是深度学习领域的创新性模型架构,它将神经网络的离散变换扩展为连续时间动力系统
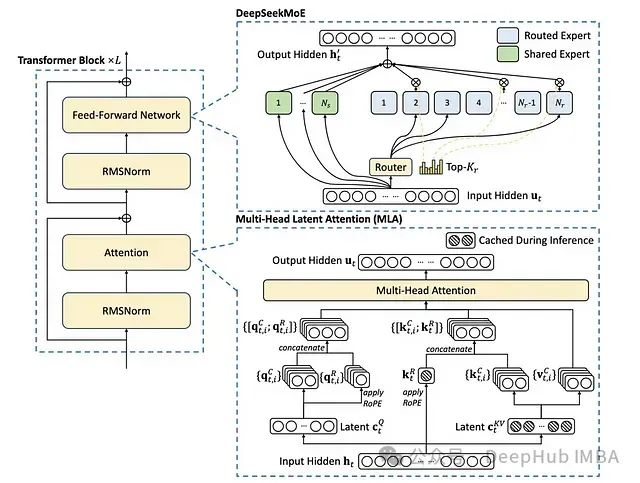
DeepSeek背后的技术基石:DeepSeekMoE基于专家混合系统的大规模语言模型架构
DeepSeekMoE是一种创新的大规模语言模型架构,通过整合专家混合系统(Mixture of Experts, MoE)、改进的注意力机制和优化的归一化策略,在模型效率与计算能力之间实现了新的平衡。
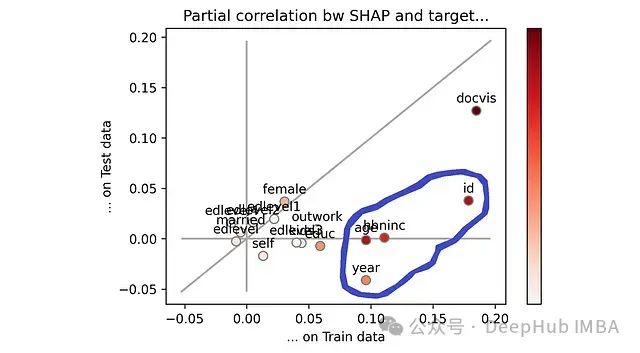
哪些特征导致过拟合?使用ParShap 方法精准定位导致模型泛化能力下降的关键特征
当模型在训练数据上表现良好,但在测试数据上表现不佳时,即出现“**过拟合**”。这意味着模型从训练数据中学习了过多的噪声模式,从而丧失了在新数据上的泛化能力。