
Deephub
更多文章请关注公众号:Deephub-IMBA
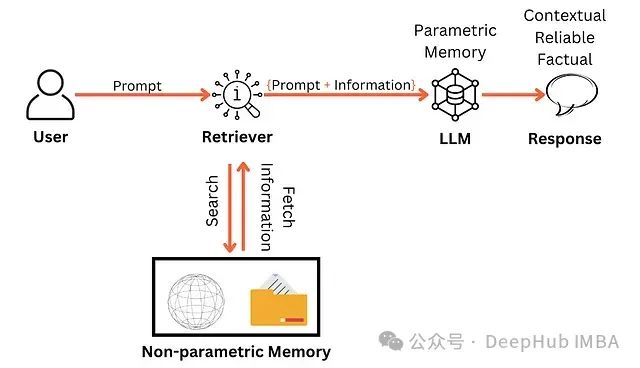
Monte Carlo方法解决强化学习问题
本文继续深入探讨蒙特卡罗 (MC)方法。这些方法的特点是能够仅从经验中学习,不需要任何环境模型,这与动态规划(DP)方法形成对比。
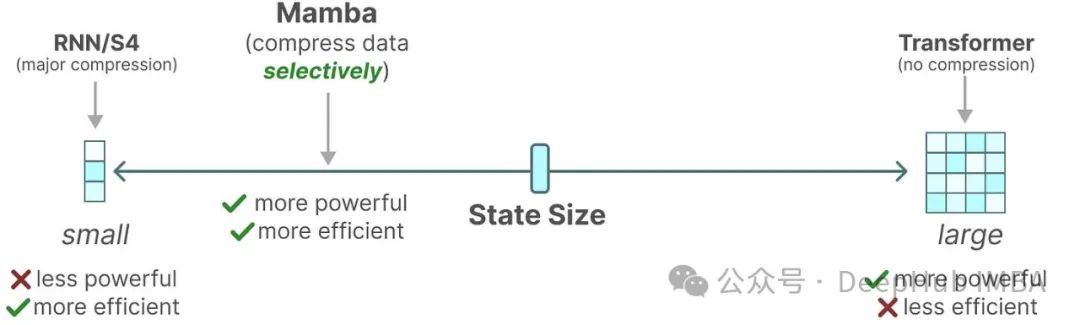
Transformer、RNN和SSM的相似性探究:揭示看似不相关的LLM架构之间的联系
通过探索看似不相关的大语言模型(LLM)架构之间的潜在联系,我们可能为促进不同模型间的思想交流和提高整体效率开辟新的途径。
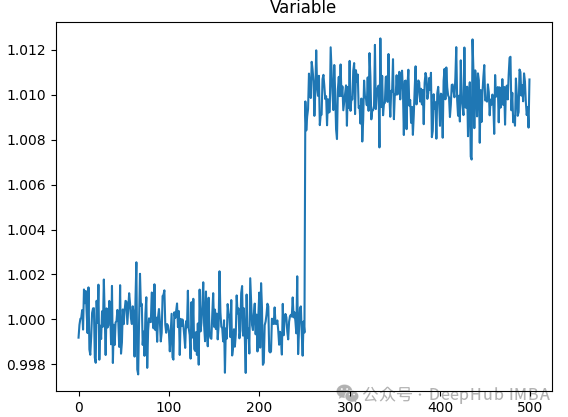
时间序列结构变化分析:Python实现时间序列变化点检测
在时间序列分析和预测中,准确检测结构变化至关重要。
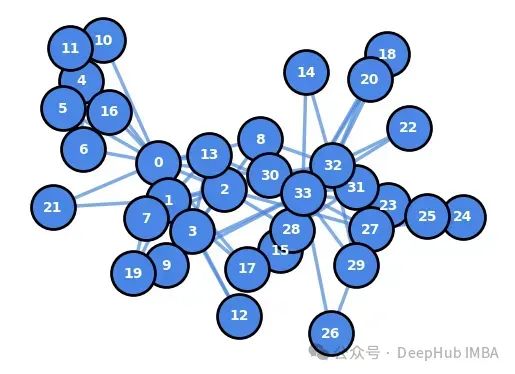
图特征工程实践指南:从节点中心性到全局拓扑的多尺度特征提取
本文将介绍如何利用NetworkX在不同层面(节点、边和整体图)提取重要的图特征。
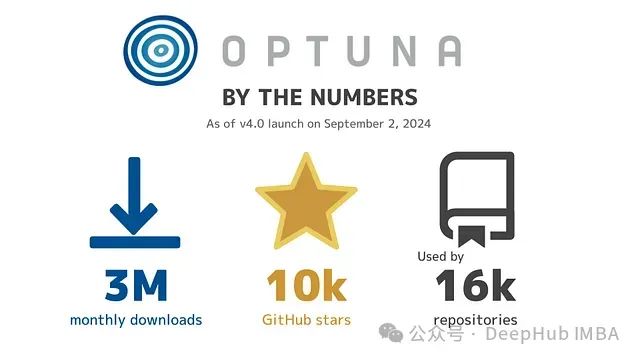
Optuna发布 4.0 重大更新:多目标TPESampler自动化超参数优化速度提升显著
Optuna这个备受欢迎的超参数优化框架在近期发布了其第四个主要版本。

优化采样参数提升大语言模型响应质量:深入分析温度、top_p、top_k和min_p的随机解码策略
本文将详细解析并可视化定义LLM输出行为的采样策略。通过深入理解这些参数的作用机制并根据具体应用场景进行调优,可以显著提升LLM生成输出的质量。
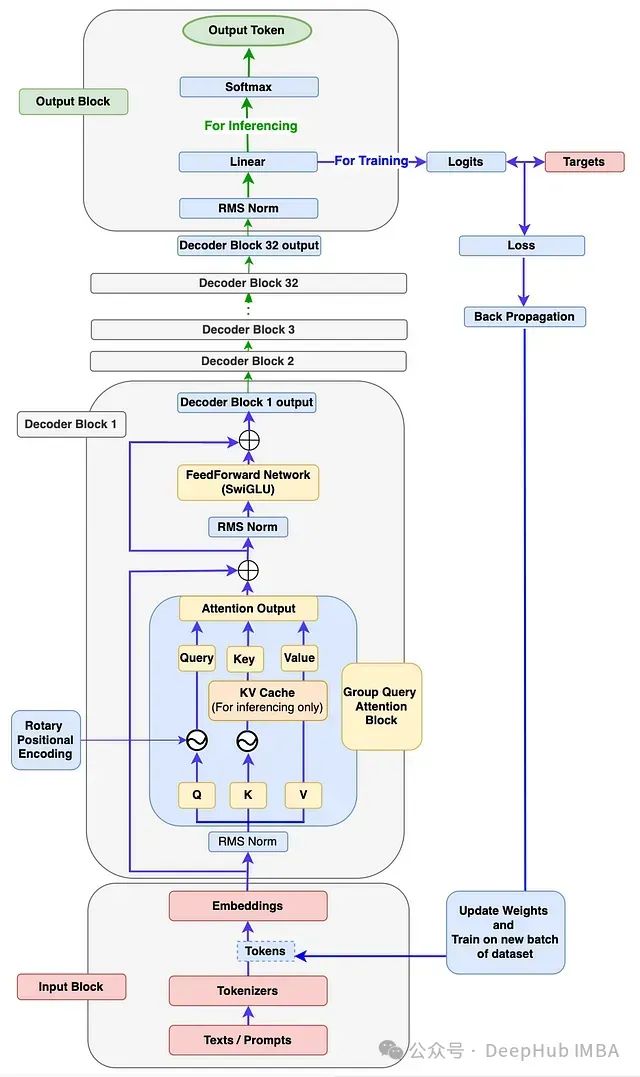
使用PyTorch从零构建Llama 3
本文将详细指导如何从零开始构建完整的Llama 3模型架构,并在自定义数据集上执行训练和推理。

一文读懂蒙特卡洛算法:从概率模拟到机器学习模型优化的全方位解析
蒙特卡洛方法已成为机器学习领域的关键工具,在强化学习、贝叶斯滤波和复杂模型优化等方面有广泛应用
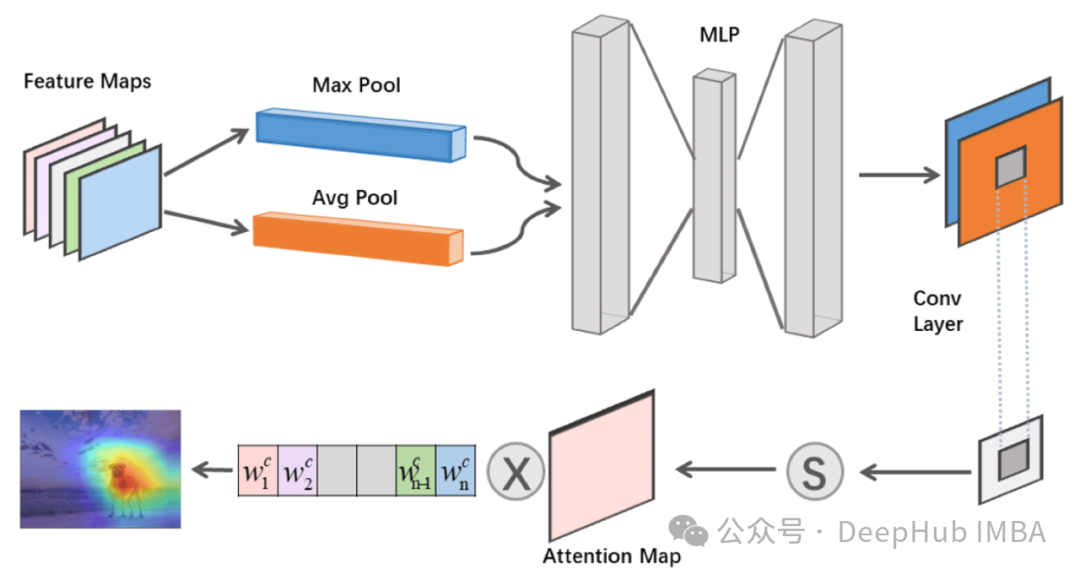
CNN中的注意力机制综合指南:从理论到Pytorch代码实现
本文将全面介绍CNN中的注意力机制,从基本概念到实际实现,为读者提供深入的理解和实践指导。

压缩大型语言模型(LLMs):缩小10倍、性能保持不变
尽管LLMs的巨大规模使其在广泛的应用场景中表现卓越,但这也为其在实际问题中的应用带来了挑战。本文将探讨如何通过压缩LLMs来应对这些挑战。我们将介绍关键概念,然后通过具体的Python代码实例进行演示。
6种有效的时间序列数据特征工程技术(使用Python)
在本文中,我们将探讨使用日期时间列提取有用信息的各种特征工程技术。
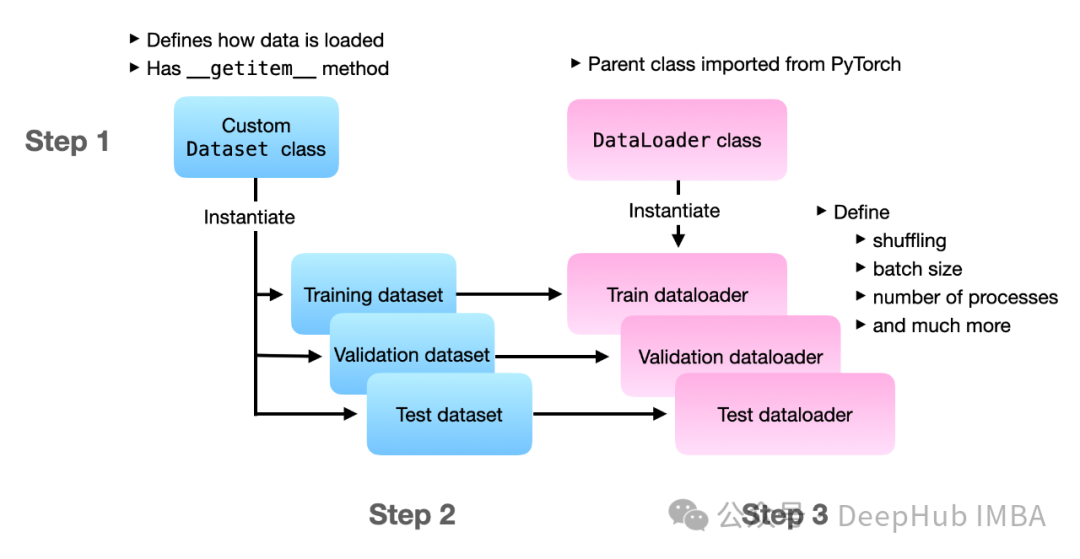
PyTorch数据处理:torch.utils.data模块的7个核心函数详解
本文将深入介绍PyTorch中 torch.utils.data 模块的7个核心函数,这些工具可以帮助你更好地管理和操作数据。
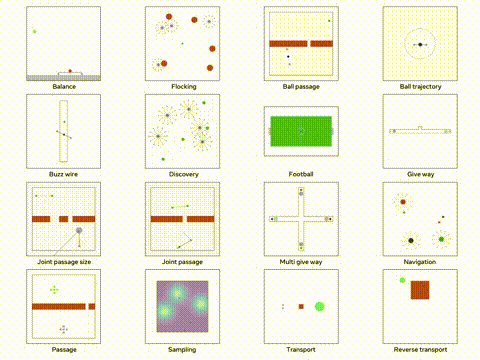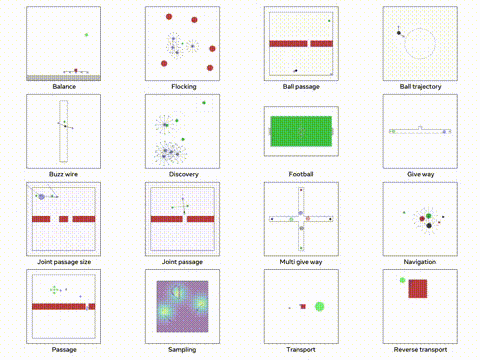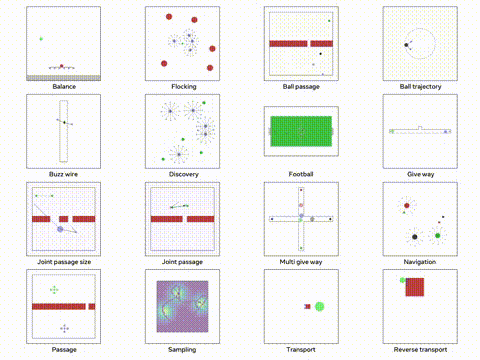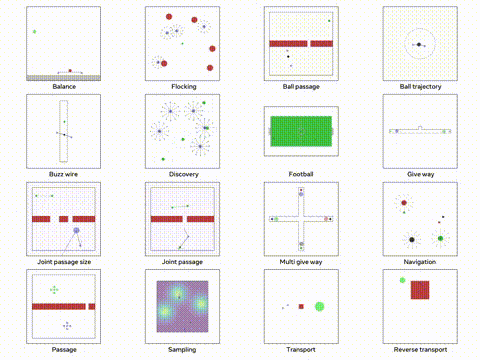
使用 Python TorchRL 进行多代理强化学习
本文将深入探讨如何使用 TorchRL 解决 MARL 问题,重点关注多代理环境中的近端策略优化(PPO)。
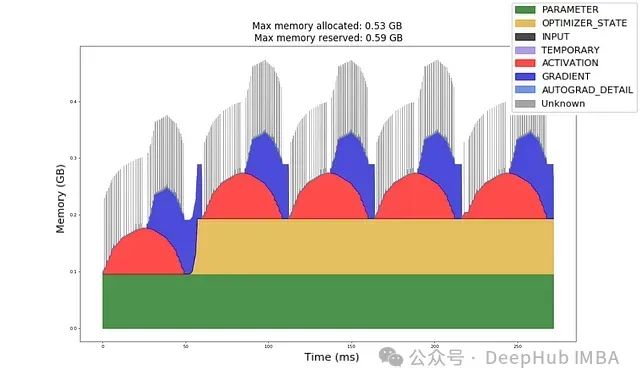
深入理解GPU内存分配:机器学习工程师的实用指南与实验
给定一个模型架构、数据类型、输入形状和优化器,你能否计算出前向传播和反向传播所需的GPU内存量?

时间序列特征提取:从理论到Python代码实践
**时间序列**是一种特殊的存在。这意味着你对表格数据或图像进行的许多转换/操作/处理技术对于时间序列来说可能根本不起作用。
高效的时间序列可视化:减少认知负荷获得更清晰的洞察
在本文中,我们将探讨使真实世界的**疫苗接种数据**来可视化单个时间序列和多个时间序列。

XGBoost中正则化的9个超参数
正则化是一种强大的技术,通过防止过拟合来提高模型性能。本文将探索各种XGBoost中的正则化方法及其优势。
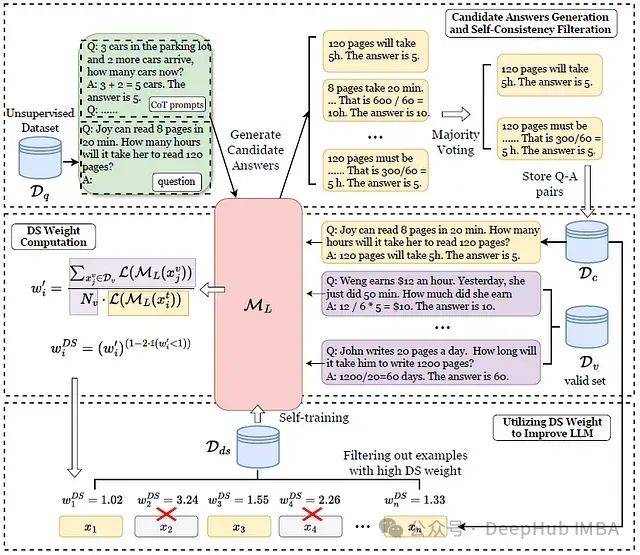
基于重要性加权的LLM自我改进:考虑分布偏移的新框架
在这篇论文中,证明过滤掉正确但具有高分布偏移程度(DSE)的样本也可以有利于自我改进的结果。
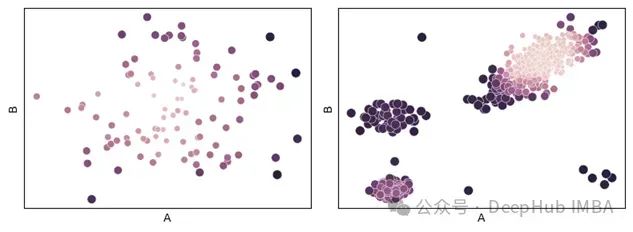
基于距离度量学习的异常检测:一种通过相关距离度量的异常检测方法
但在本文中,将一种非常通用且可能未被充分使用的方法,用于计算表格数据中两条记录之间的差异,这对异常检测非常有用,称为*距离度量学习* - 以及一种专门应用于异常检测的方法。