
Deephub
更多文章请关注公众号:Deephub-IMBA
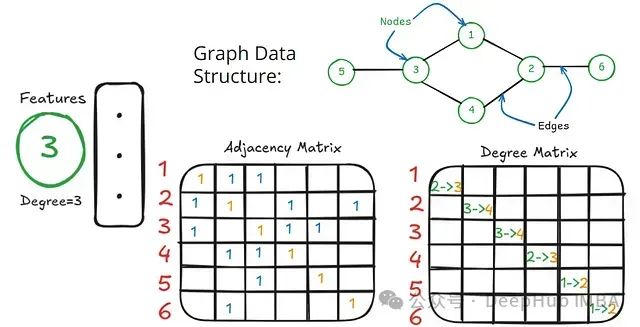
图卷积网络入门:数学基础与架构设计
本文系统地阐述了图卷积网络的架构原理。通过简化数学表述并聚焦于矩阵运算的核心概念,详细解析了GCN的工作机制。
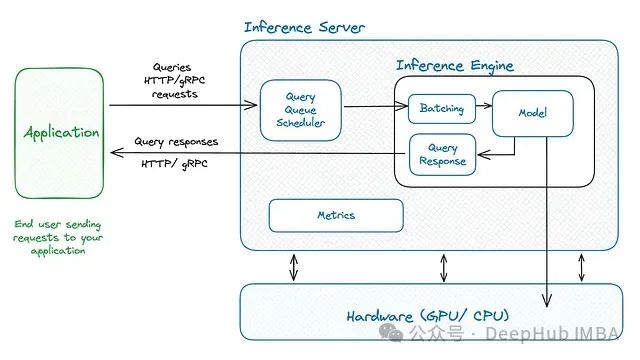
从本地部署到企业级服务:十种主流LLM推理框架的技术介绍与对比
本文将深入探讨十种主流LLM服务引擎和工具,系统分析它们在不同应用场景下的技术特点和优势。
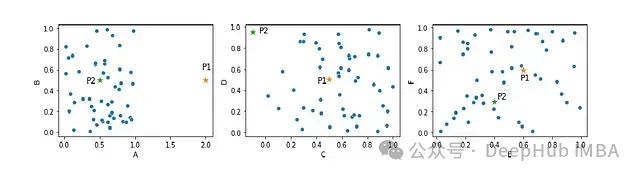
基于特征子空间的高维异常检测:一种高效且可解释的方法
本文将重点探讨一种替代传统单一检测器的方法:不是采用单一检测器分析数据集的所有特征,而是构建多个专注于特征子集(即*子空间*)的检测器系统。
置信区间与预测区间:数据科学中的不确定性量化技术深度解读
本文深入探讨了统计学中两个常见但容易混淆的不确定性量化工具:置信区间和预测区间。

一份写给数据工程师的 Polars 迁移指南:将 Pandas 速度提升 20 倍代码重构实践
Polars作为现代化的数据处理框架,通过先进的工程实践和算法优化,为数据科学工作者提供了高效的数据处理工具。在从Pandas迁移时,理解这些核心概念和最佳实践将有助于充分发挥Polars的性能优势。
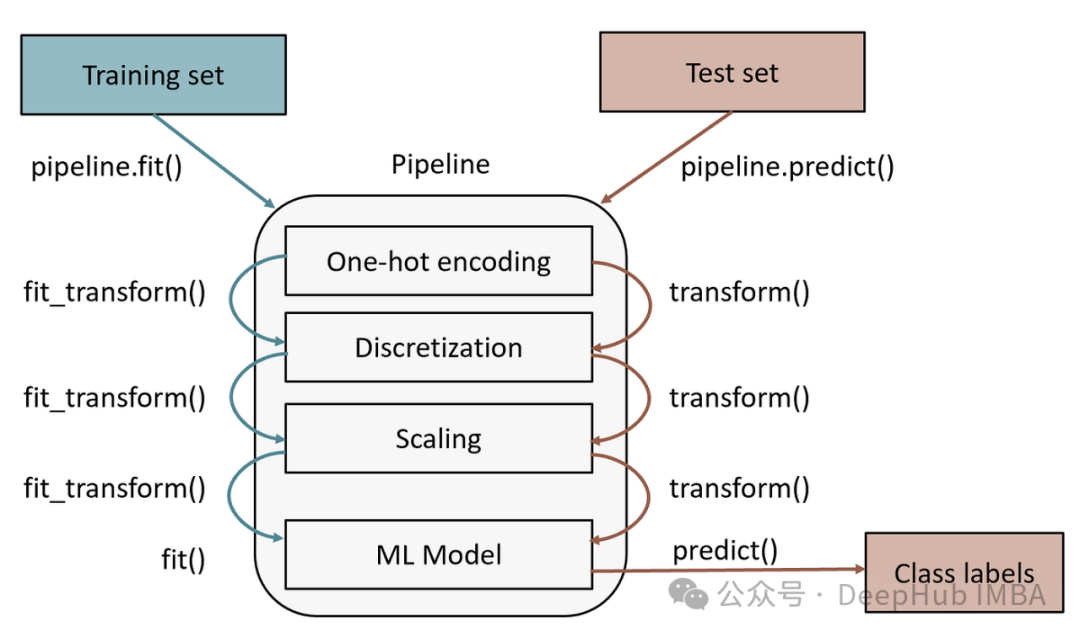
Scikit-learn Pipeline完全指南:高效构建机器学习工作流
在机器学习工作流程中,组合估计器通过将多个转换器(Transformer)和预测器(Predictor)整合到一个管道(Pipeline)中,可以有效简化整个过程。
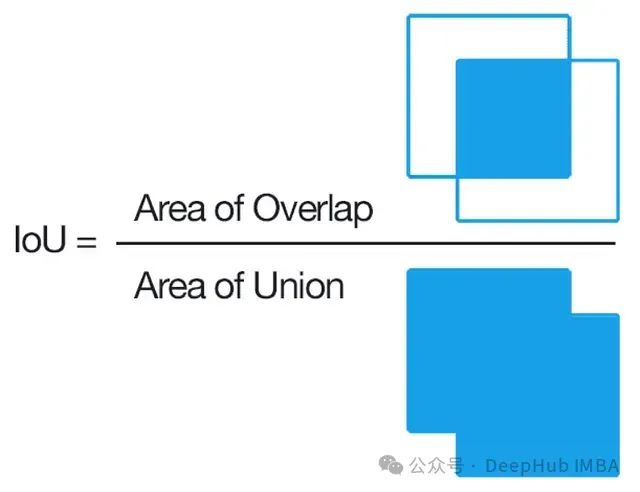
IoU已经out了,试试这几个变体:GIoU、DIoU和CIoU介绍与对比分析
GIoU、DIoU和CIoU这三个变体都有各自的独到之处,它们在一定程度上弥补了普通IoU在处理不重叠、距离较远或形状差异较大的边界框时的不足。
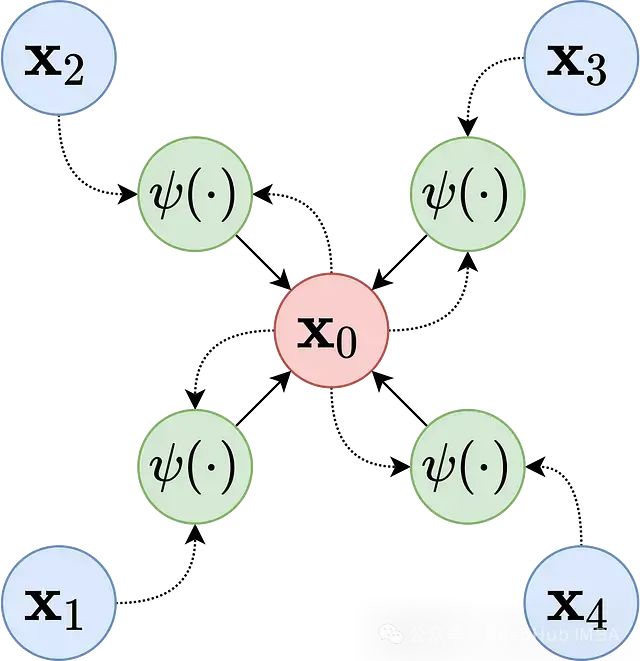
图神经网络在欺诈检测与蛋白质功能预测中的应用概述
本文将深入探讨GNNs在欺诈检测和生物信息学领域的应用机制与技术原理。
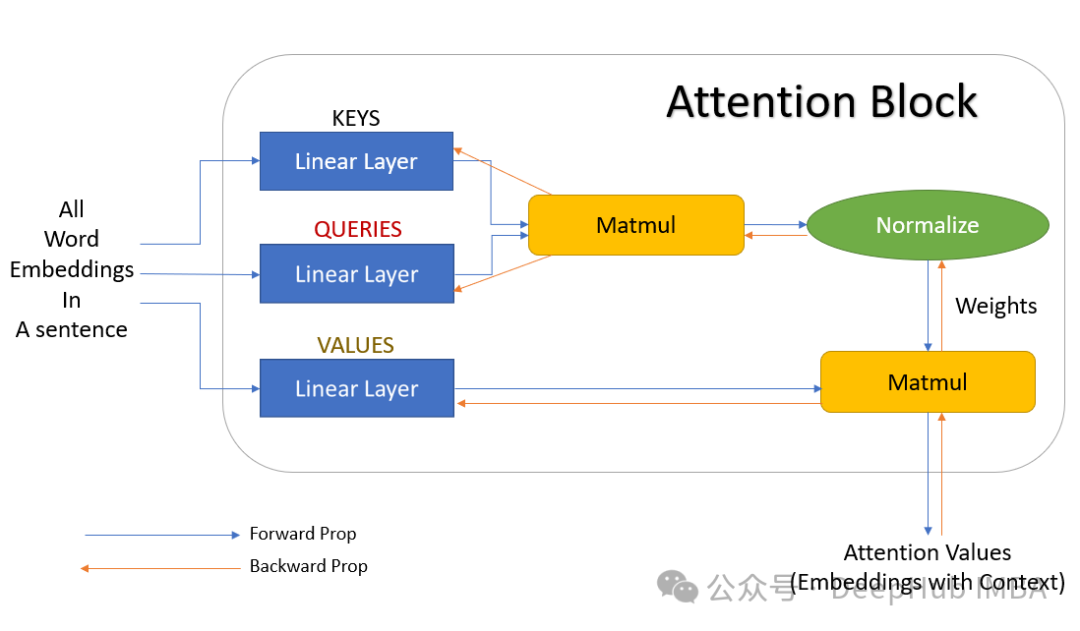
优化注意力层提升 Transformer 模型效率:通过改进注意力机制降低机器学习成本
本文将深入探讨在 PyTorch 生态系统中优化注意力层的多种技术路径,并将重点聚焦于那些在降低计算成本的同时能够保持注意力层精度的创新方法。
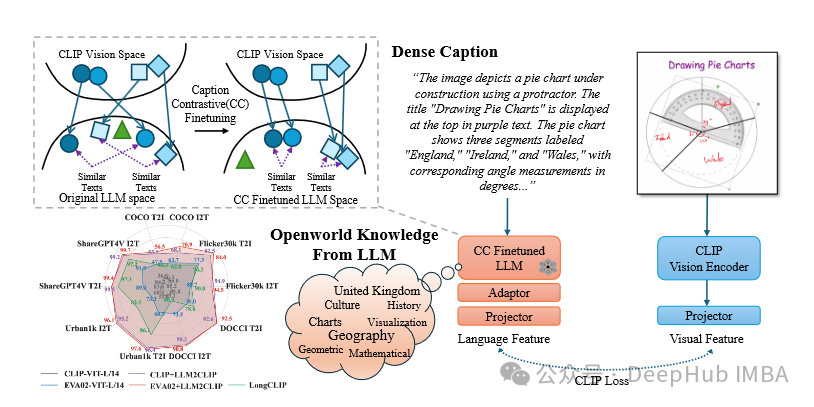
LLM2CLIP:使用大语言模型提升CLIP的文本处理,提高长文本理解和跨语言能力
LLM2CLIP 为多模态学习提供了一种新的范式,通过整合 LLM 的强大功能来增强 CLIP 模型。
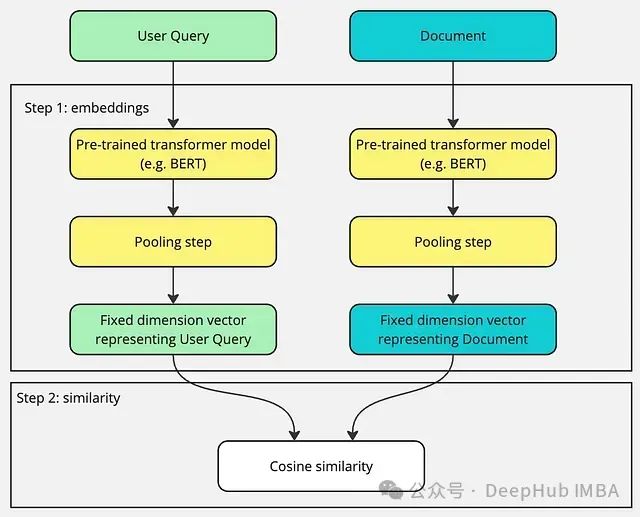
解读双编码器和交叉编码器:信息检索中的向量表示与语义匹配
在信息检索领域(即从海量数据中查找相关信息),双编码器和交叉编码器是两种至关重要的工具。它们各自拥有独特的工作机制、优势和局限性。本文将深入探讨这两种核心技术。
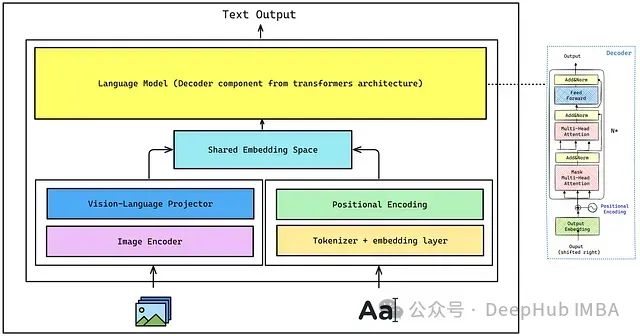
使用Pytorch构建视觉语言模型(VLM)
本文将介绍 VLM 的核心组件和实现细节,可以让你全面掌握这项前沿技术。我们的目标是理解并实现能够通过指令微调来执行有用任务的视觉语言模型。

使用 PyTorch-BigGraph 构建和部署大规模图嵌入的完整教程
本文深入探讨了使用 PyTorch-BigGraph (PBG) 构建和部署大规模图嵌入的完整流程,涵盖了从环境设置、数据准备、模型配置与训练,到高级优化技术、评估指标、部署策略以及实际案例研究等各个方面。
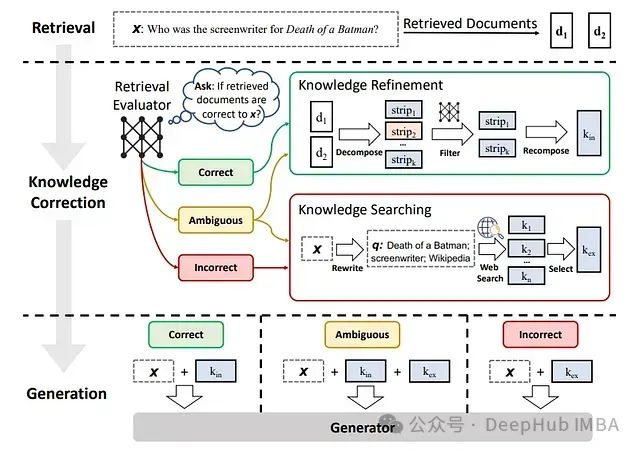
25 个值得关注的检索增强生成 (RAG) 模型和框架
本文深入探讨 25 种先进的 RAG 变体,每一种都旨在优化检索和生成过程的特定方面。从标准实现到专用框架,这些变体涵盖了成本限制、实时交互和多模态数据集成等问题,展示了 RAG 在提升 NLP 能力方面的多功能性和潜力。
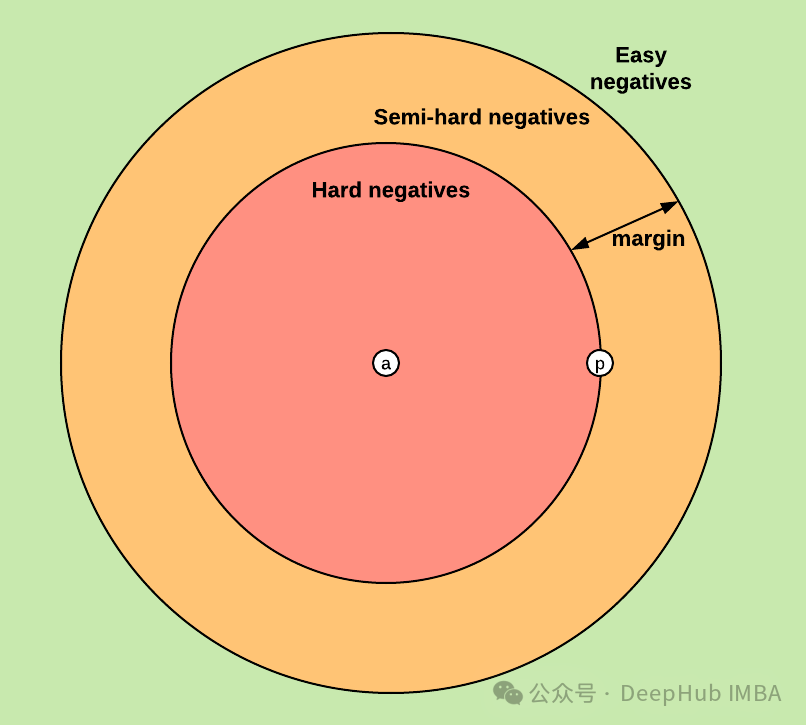
利用PyTorch的三元组损失Hard Triplet Loss进行嵌入模型微调
本文介绍如何使用 PyTorch 和三元组边缘损失 (Triplet Margin Loss) 微调嵌入模型,并重点阐述实现细节和代码示例

告别Print,使用IceCream进行高效的Python调试
本文将介绍**IceCream**库,这个专门用于调试的工具显著提升了调试效率,使整个过程更加系统化和规范化。
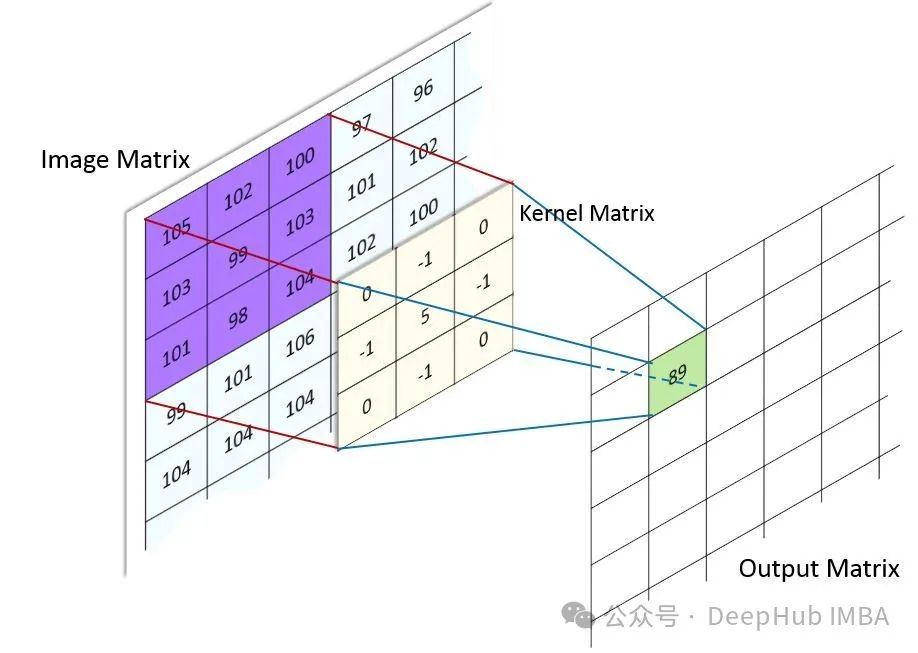
为什么卷积现在不火了:CNN研究热度降温的深层原因分析
纵观近年的顶会论文和研究热点,我们不得不承认一个现实:CNN相关的研究论文正在减少,曾经的"主角"似乎正逐渐淡出研究者的视野。
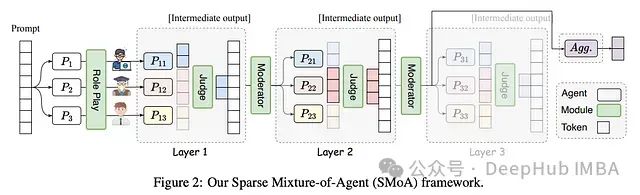
SMoA: 基于稀疏混合架构的大语言模型协同优化框架
通过引入稀疏化和角色多样性,SMoA为大语言模型多代理系统的发展开辟了新的方向。
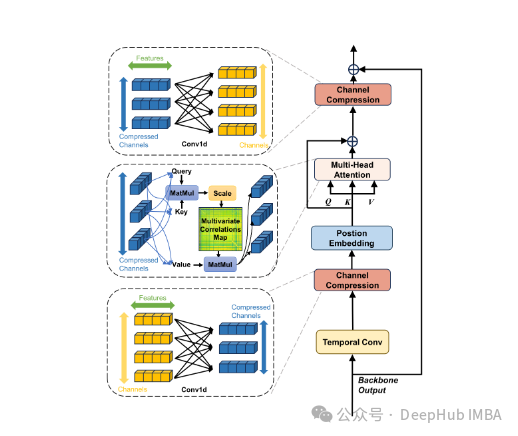
TSMamba:基于Mamba架构的高效时间序列预测基础模型
TSMamba通过其创新的架构设计和训练策略,成功解决了传统时间序列预测模型面临的多个关键问题。