
Deephub
更多文章请关注公众号:Deephub-IMBA
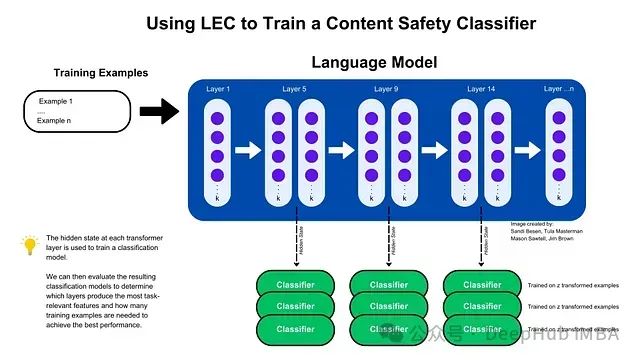
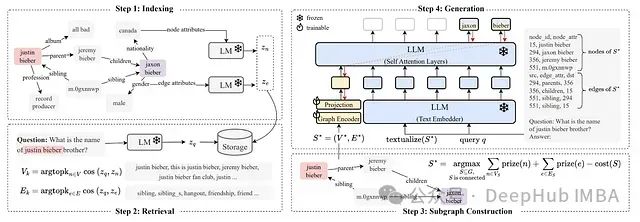
LEC: 基于Transformer中间层隐藏状态的高效特征提取与内容安全分类方法
通过利用Transformer中间层的隐藏状态,研究提出了层增强分类(LEC)技术,该技术能够以极少的训练样本和参数实现高效的内容安全和提示注入攻击分类,显著提升了模型的性能,并验证了其跨架构和领域的泛化能力。
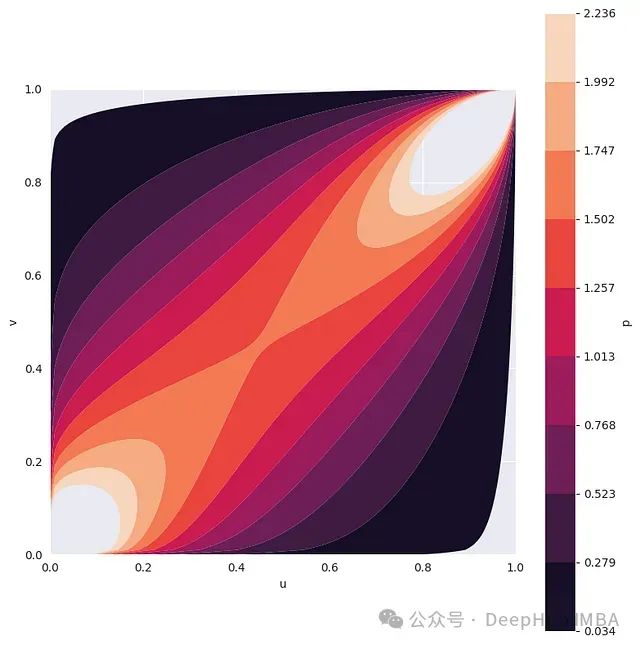
基于Copula分布的合成数据采样:保持多维数据依赖结构的高效建模方法
copula是一类能够将随机变量间的依赖关系与其边际分布分离的函数。这种分离特性使copula在多元分析中具有独特优势,特别是在处理非线性依赖关系或异质分布变量时。
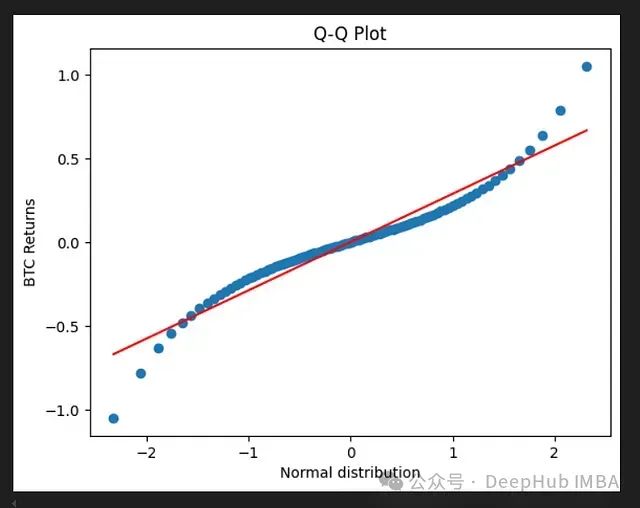
数据分布检验利器:通过Q-Q图进行可视化分布诊断、异常检测与预处理优化
Q-Q图在机器学习领域扮演着多重重要角色。作为一种统计可视化工具,它首先能帮助研究人员深入理解数据的分布特征,让我们直观地看到数据是否符合某种理论分布。
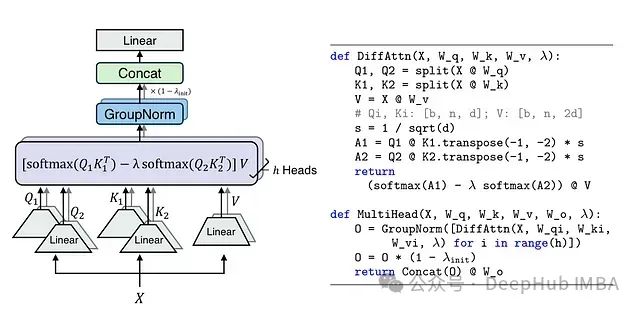
Differential Transformer: 通过差分注意力机制提升大语言模型性能
DIFF Transformer通过创新的差分注意力机制成功提升了模型性能,特别是在长文本理解、关键信息检索和模型鲁棒性等方面。
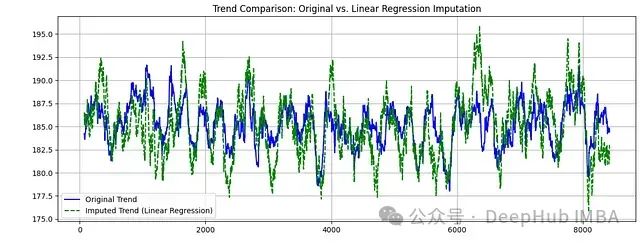
使用机器学习技术进行时间序列缺失数据填充:基础方法与入门案例
本文将通过实际案例,详细探讨如何运用机器学习技术来解决时间序列的缺失值问题。
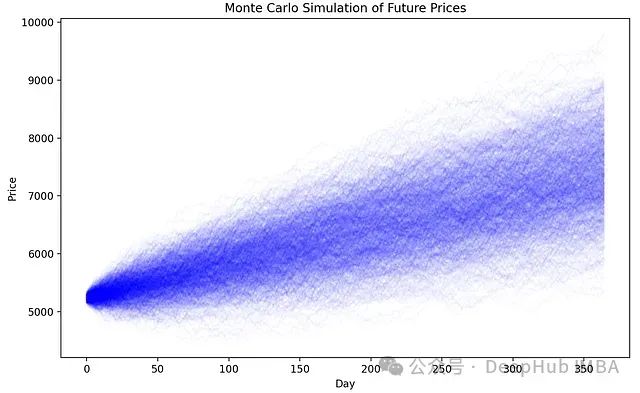
Python量化投资实践:基于蒙特卡洛模拟的投资组合风险建模与分析
蒙特卡洛模拟是一种基于重复随机抽样获取数值结果的计算算法。在金融应用领域,蒙特卡洛模拟主要用于股票和加密货币市场的分析。
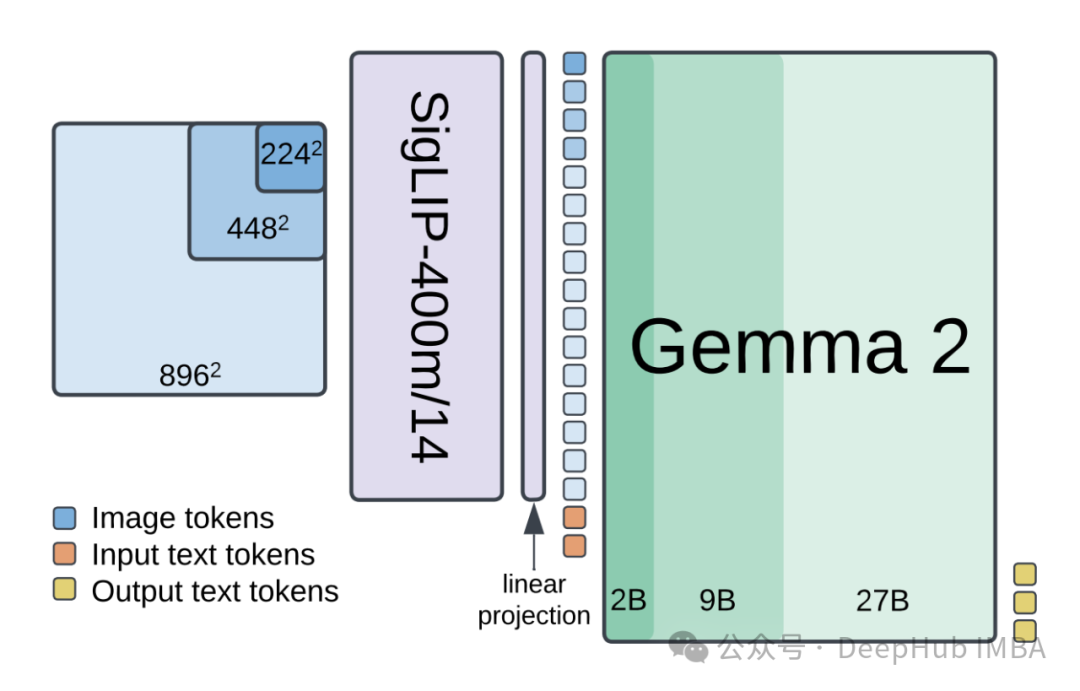
使用PaliGemma2构建多模态目标检测系统:从架构设计到性能优化的技术实践指南
本文详细阐述了如何利用PaliGemma2构建高性能的多模态目标检测系统。
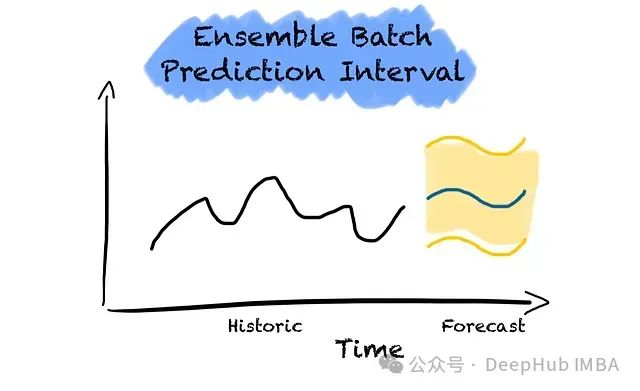
时间序列预测的不确定性区间估计:基于EnbPI的方法与应用研究
本文聚焦于时间序列预测中的不确定性量化问题,重点探讨基于一致性预测理论的集成批量预测区间(Ensemble Batch Prediction Interval, EnbPI)方法。
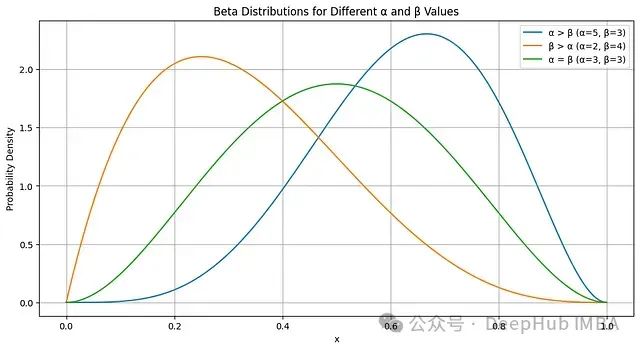
Beta分布与汤普森采样:智能决策系统概率采样的理论基础
Beta分布是二项分布和伯努利分布的共轭先验。当先验采用Beta分布,似然函数为二项分布或伯努利分布时,后验分布仍然是Beta分布。
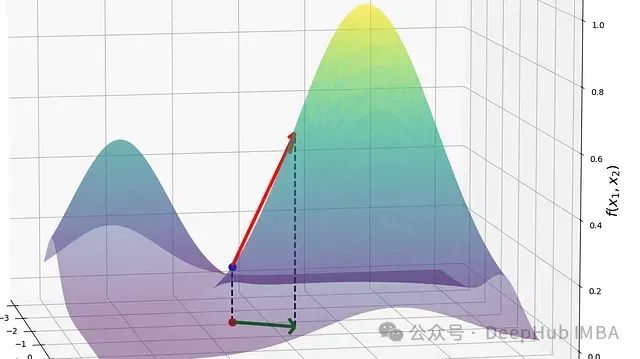
从方向导数到梯度:深度学习中的关键数学概念详解
本文将系统探讨方向导数与梯度的理论基础,并阐述二者的内在联系
ORCA:基于持续批处理的LLM推理性能优化技术详解
ORCA系统创新性地提出了持续批处理概念,通过引入迭代级调度和选择性批处理机制,有效解决了大语言模型批处理中的关键技术挑战。
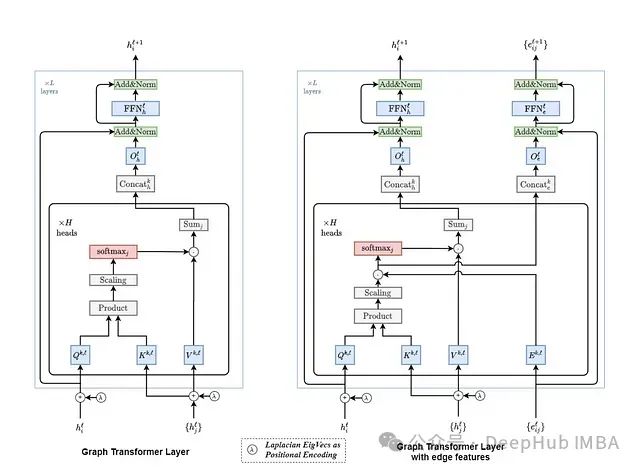
深入解析图神经网络:Graph Transformer的算法基础与工程实践
本文不仅是对Graph Transformer技术的深入解析,更是一份从理论到实践的完整技术指南,为那些希望在图神经网络领域深入发展的技术人员提供了宝贵的学习资源。
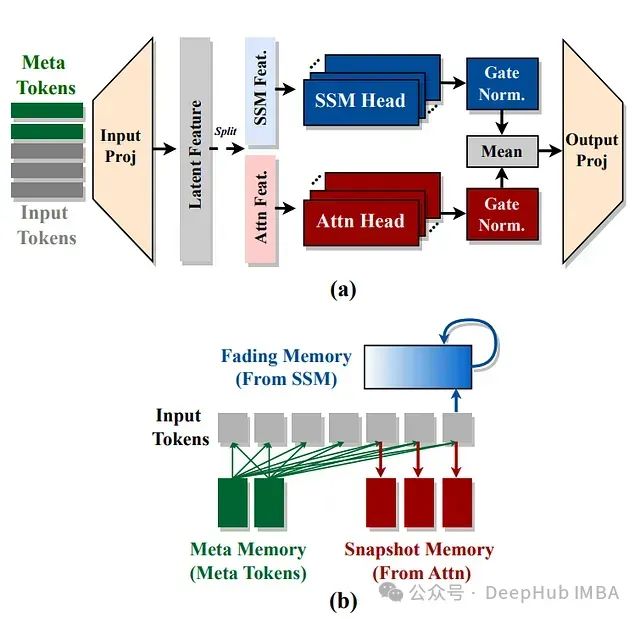
Hymba: 结合注意力头和SSM头的创新型语言模型方案
NVIDIA提出了Hymba架构,通过在同一层中结合注意力头和SSM头,以实现两种架构优势的互补。
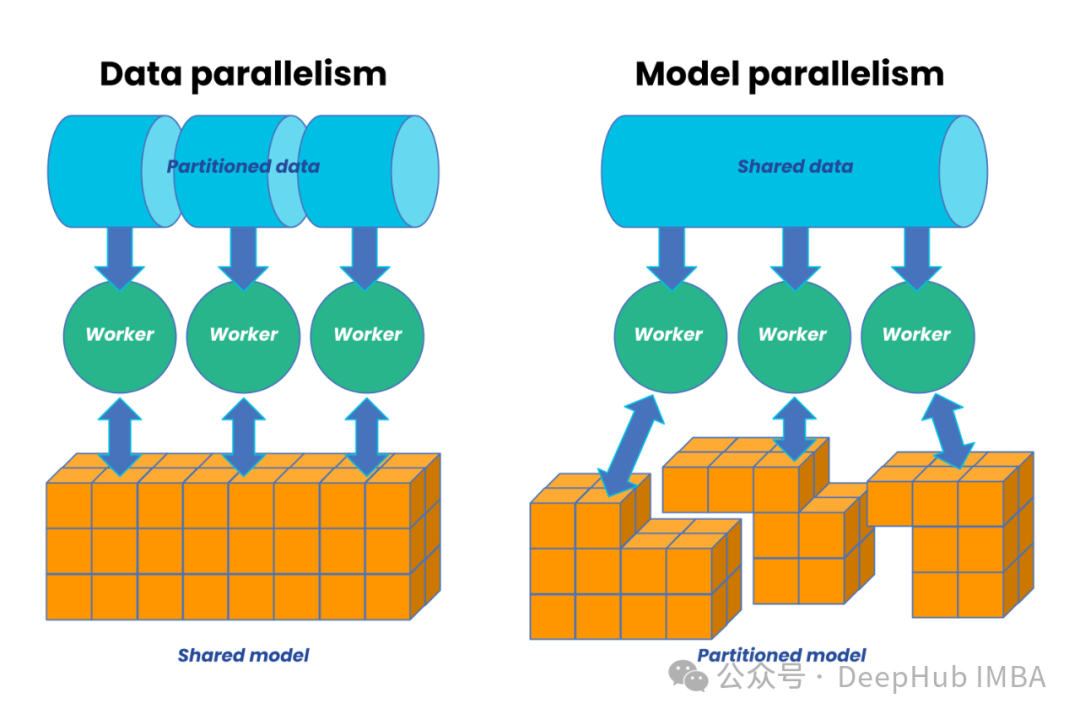
分布式机器学习系统:设计原理、优化策略与实践经验
分布式机器学习系统仍在快速发展。随着新型硬件的出现和算法的进步,我们预期会看到更多创新的优化技术。
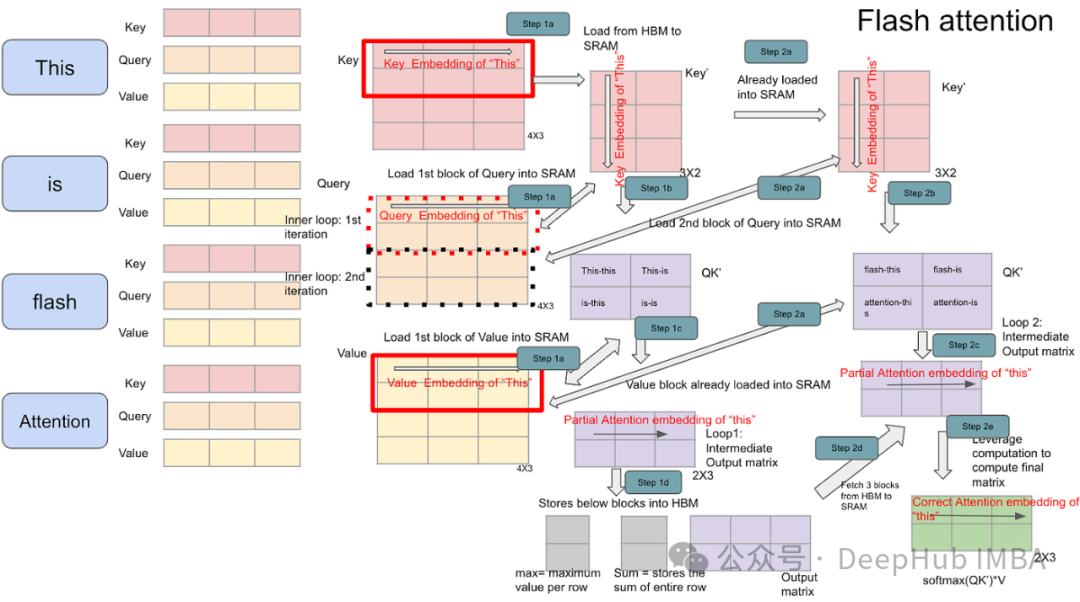
Transformer模型变长序列优化:解析PyTorch上的FlashAttention2与xFormers
本文将进一步探讨变长输入序列这一挑战——这是真实世界数据(如文档、代码、时间序列等)的固有特征。
图卷积网络入门:数学基础与架构设计
本文系统地阐述了图卷积网络的架构原理。通过简化数学表述并聚焦于矩阵运算的核心概念,详细解析了GCN的工作机制。