
数据科学家在实践中经常面临的一个关键挑战是缺乏足够的标记数据来训练可靠且准确的模型。标记数据对于监督学习任务(如分类或回归)至关重要。但是在许多领域,获取标记数据往往成本高昂、耗时或不切实际。相比之下,未标记数据通常较易获取,但无法直接用于模型训练。
如何利用未标记数据来改进监督学习模型?这正是半监督学习的应用场景。半监督学习是机器学习的一个分支,它结合标记和未标记数据来训练模型,旨在获得比仅使用标记数据更优的性能。半监督学习的基本原理是,未标记数据可以提供关于数据底层结构、分布和多样性的有用信息,从而帮助模型更好地泛化到新的和未见过的样本。
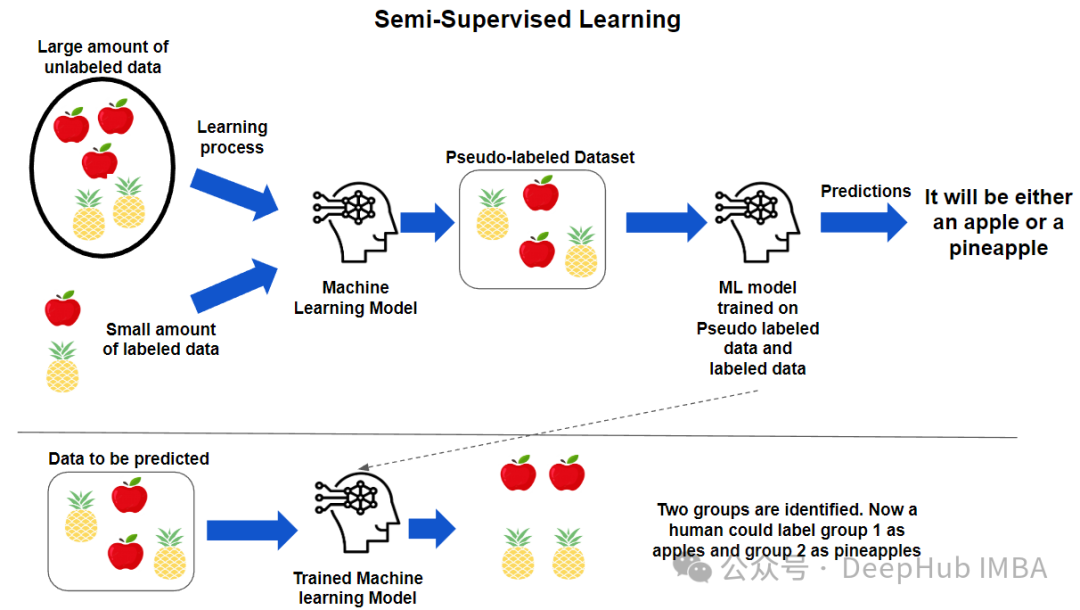
本文将介绍三种适用于不同类型数据和任务的半监督学习方法。我们还将在一个实际数据集上评估这些方法的性能,并与仅使用标记数据的基准进行比较。
半监督学习概述
半监督学习是一种利用标记和未标记数据来训练模型的机器学习方法。标记数据是指具有已知输出或目标变量的样本,例如分类任务中的类别标签或回归任务中的数值。未标记数据则是没有已知输出或目标变量的样本。半监督学习的优势在于它可以利用现实问题中通常大量存在的未标记数据,同时也充分利用通常较少且获取成本较高的标记数据。
利用未标记数据训练监督学习模型的核心思想是通过监督或无监督学习方法为这些数据生成标签。尽管这些生成的标签可能不如实际标签准确,但大量这样的数据仍可以显著提高监督学习方法的性能,相比于仅在有限的标记数据上训练模型。
scikit-learn库提供了三种半监督学习方法:
- 自训练(Self-training):首先在标记数据上训练分类器,用于预测未标记数据的标签。在后续迭代中,另一个分类器在标记数据和高置信度的未标记数据预测结果上进行训练。此过程重复进行,直到没有新的高置信度标签被预测或达到最大迭代次数。
- 标签传播(Label Propagation):构建一个图结构,其中节点表示数据点,边表示它们之间的相似性。标签通过图结构迭代传播,使算法能够基于未标记数据点与标记数据的连接关系为其分配标签。
- 标签扩散(Label Spreading):采用与标签传播类似的概念。不同之处在于标签扩散使用软分配策略,即标签根据数据点之间的相似性进行迭代更新。此方法还可能"覆盖"标记数据集中的原始标签。
为评估这些方法,本文使用了糖尿病预测数据集,其中包含患者的各种特征数据,如年龄和BMI,以及表示患者是否患有糖尿病的标签。该数据集共包含100,000条记录,我们将其随机划分为80,000条训练数据、10,000条验证数据和10,000条测试数据。为分析学习方法对标记数据数量的敏感性,还将训练数据进一步划分为标记集和未标记集,其中标记数据的数量作为一个可变参数。
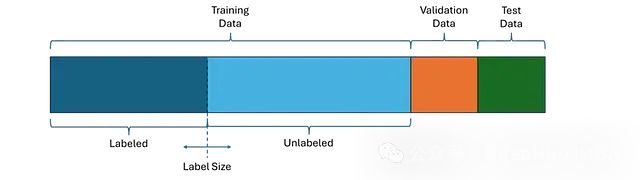
数据集划分示意图
我们使用验证数据集来评估不同的参数设置,并使用测试数据集来评估参数调优后各方法的最终性能。选择XGBoost作为预测模型,并使用F1分数作为性能评估指标。
基准模型
为了比较自学习算法与不使用未标记数据的情况,我们首先建立一个基准模型。在不同大小的标记数据集上训练XGBoost模型,并在验证数据集上计算F1分数:
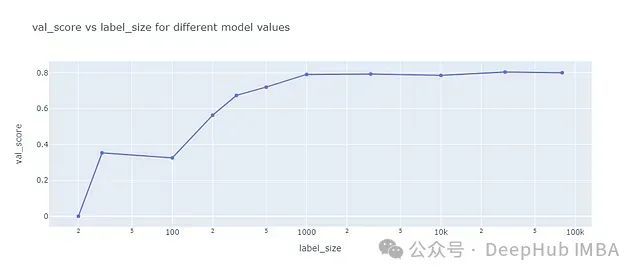
基准模型F1分数
结果显示,当训练样本少于100个时,F1分数相对较低。随着样本量增加到1,000,F1分数稳步提升至约79%。继续增加样本量后,F1分数的提升幅度变得微小。
自学习方法
自学习(Self-training)是一种迭代过程,用于为未标记数据生成标签,并在后续迭代中将这些生成的标签用于模型训练。选择预测结果作为下一次迭代的标记数据主要有两种策略:
- 阈值法(默认):选择所有置信度高于预设阈值的预测结果。
- K最佳法:选择置信度最高的K个预测结果。
我们评估了以下三种配置:
- ST默认:使用默认参数的自学习
- ST阈值调优:基于验证数据集调整阈值的自学习
- ST KB调优:基于验证数据集调整K值的自学习
这些模型的性能在测试数据集上进行了评估,结果如下图所示:
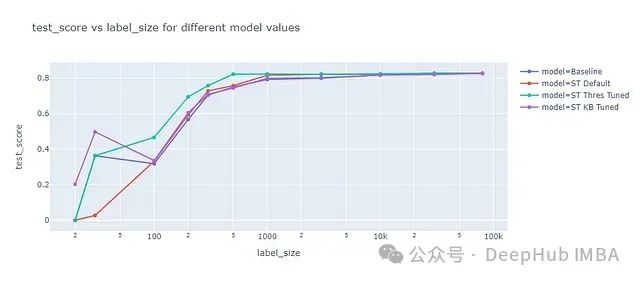
自学习方法性能比较
分析结果显示:
- 对于小样本量(<100),默认参数配置(红线)的表现不如基准模型(蓝线)。
- 在较大样本量下,自学习方法略优于基准模型。
- 阈值调优(绿线)带来了显著的性能提升。例如,在标记数据量为200时,基准模型的F1分数为57%,而使用调优阈值的自学习算法达到了70%。
- K最佳法调优(紫线)的性能与基准模型相近,仅在标记数据量为30时出现例外。
标签传播方法
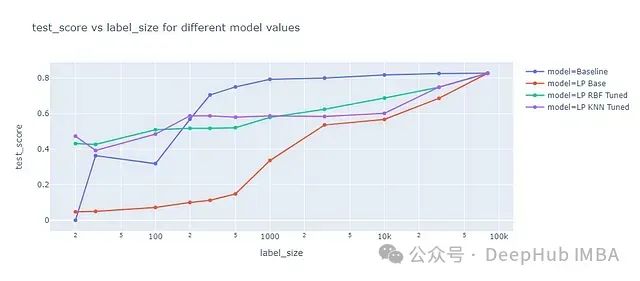
标签传播算法内置了两种核函数:RBF(径向基函数)和KNN(K近邻)。RBF核使用密集矩阵生成完全连接的图,这对大型数据集而言计算成本高且内存密集。考虑到内存限制,所以我们对RBF核的训练规模上限设为3,000个样本。KNN核利用更节省内存的稀疏矩阵表示,使我们能够在全部训练数据(最多80,000个样本)上进行拟合。下图比较了这两种核函数方法的性能:
标签传播方法性能比较
图中展示了不同标签传播配置在测试数据集上的F1分数,作为标记数据量的函数。主要观察结果如下:
- 蓝线代表基准模型,与自学习实验中的基准相同。
- 红线表示使用默认参数的标签传播,其性能在所有标记数据量下均明显低于基准模型。
- 绿线代表使用RBF核和经过调优的gamma参数的标签传播。Gamma参数定义了单个训练样本的影响范围。调优后的RBF核在小样本量(<=100)时优于基准模型,但在较大样本量时表现较差。
- 紫线代表使用KNN核和经过调优的K参数的标签传播,K确定了要使用的最近邻数量。KNN核的整体表现与RBF核相似。
标签扩散方法
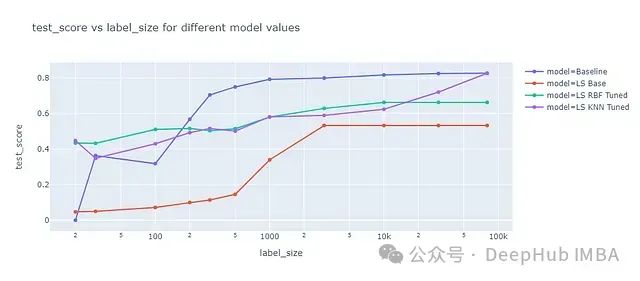
标签扩散是一种与标签传播相似的方法,但引入了一个额外的参数alpha,用于控制实例采纳邻居信息的程度。Alpha取值范围为0到1,其中0表示实例完全保持其原始标签,1表示完全采纳邻居的标签。我们对标签扩散的RBF和KNN核方法都进行了参数调优。标签扩散的性能结果如下图所示:
标签扩散方法性能比较
分析结果显示:
- 标签扩散的整体性能趋势与标签传播非常相似,但存在一个显著的例外。
- 标签扩散的RBF核方法在所有标记数据量下的测试分数均低于基准模型,而不仅仅是在小样本量情况下。
- 这一现象表明,对于本数据集,邻居标签的"覆写"效果可能产生了负面影响。这可能是由于数据集中异常值或噪声标签较少导致的。
- 相比之下,KNN核方法似乎不受alpha参数的显著影响。这暗示alpha参数主要与RBF核方法相关。
综合比较
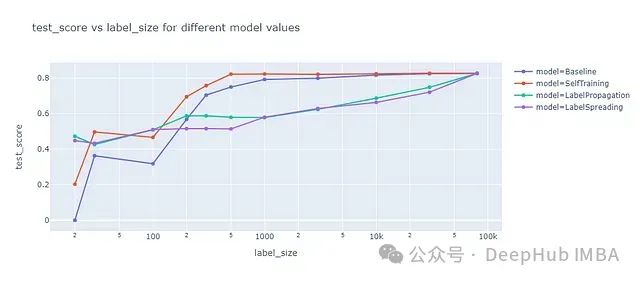
为了全面评估各种半监督学习方法的性能,我们将所有使用最优参数配置的方法进行了对比。下图展示了这一综合比较的结果:
各方法最优性能比较
图中展示了不同半监督学习方法在测试数据集上的F1分数,作为标记数据量的函数。主要观察结果如下:
- 自训练方法(Self-training)在大多数情况下表现优于基准模型。这表明该方法能够有效利用未标记数据来提升模型性能。
- 标签传播(Label Propagation)和标签扩散(Label Spreading)方法仅在标记数据量较小时优于基准模型。随着标记数据量的增加,这两种方法的性能相对下降。
- 在标记数据量较大时,基准模型的性能接近或超过了半监督学习方法。这说明当有足够的标记数据时,传统的监督学习方法可能已经足够有效。
研究结论
基于本研究的实验结果得出以下主要结论:
- 方法有效性因数据集而异:半监督学习方法的性能可能会因不同的数据集、分类器算法和评估指标而显著变化。因此不应将本研究的发现直接推广到其他应用场景,而应在具体应用中进行适当的测试和验证。
- 参数调优的重要性:参数调优对于显著提高半监督学习方法的性能至关重要。例如,经过优化的自训练方法在各种标记数据量下均优于基准模型,F1分数最高提升可达13个百分点。
- 方法选择的权衡:标签传播和标签扩散方法仅在非常小的样本量时表现出性能优势。使用这些方法时需要格外谨慎,以避免在某些情况下获得比不使用半监督学习更差的结果。
- 自训练方法的稳健性:在文中自训练方法展现出了较好的稳健性和性能提升,特别是在中等规模的标记数据集上。
- 计算资源考虑:RBF核方法在大规模数据集上可能面临计算资源限制,而KNN核方法在这方面表现更为灵活。
实际应用建议
我们为实际应用中的半监督学习提出以下建议:
- 方法选择:在标记数据有限的情况下,优先考虑使用自训练方法。对于极小规模的标记数据集,可以尝试标签传播或标签扩散方法。
- 参数调优:无论选择哪种半监督学习方法,都应进行充分的参数调优。这可能会显著提高模型性能。
- 性能评估:始终将半监督学习方法与仅使用标记数据的基准模型进行比较,以确保所选方法确实带来了性能提升。
- 数据质量:关注未标记数据的质量和相关性。高质量的未标记数据更可能对模型性能产生积极影响。
- 计算资源平衡:在选择核方法时,要考虑可用的计算资源。对于大规模数据集,KNN核可能是更实用的选择。
未来研究方向
为进一步推进半监督学习在实际应用中的有效性,建议以下几个潜在的研究方向:
- 探索更多类型的数据集和应用场景,以评估半监督学习方法的泛化能力。
- 研究如何自动选择最适合特定数据集和任务的半监督学习方法。
- 开发更高效的参数调优策略,以减少计算开销。
- 调查半监督学习方法在处理不平衡数据集和多类分类问题时的效果。
- 结合其他机器学习技术(如迁移学习或主动学习)与半监督学习,探索可能的协同效应。
如果你想手动研究和测试,本文代码在这里:
https://github.com/ReinhardSellmair/ssl
作者:Reinhard Sellmair