
Deephub
更多文章请关注公众号:Deephub-IMBA
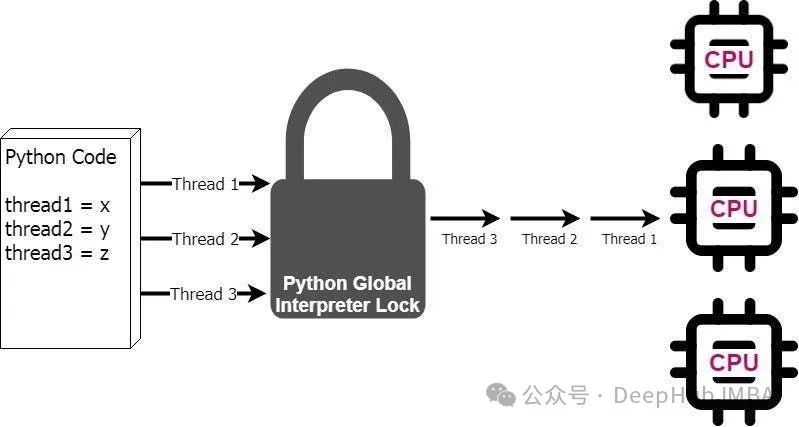
Python GIL(全局解释器锁)机制对多线程性能影响的深度分析
本文将主要基于CPython(用C语言实现的Python解释器,也是目前应用最广泛的Python解释器)展开讨论。
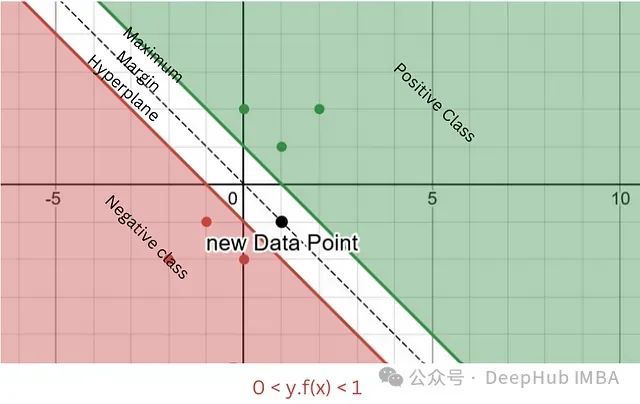
深入剖析SVM核心机制:铰链损失函数的原理与代码实现
铰链损失(Hinge Loss)是支持向量机(Support Vector Machine, SVM)中最为核心的损失函数之一。该损失函数不仅在SVM中发挥着关键作用,也被广泛应用于其他机器学习模型的训练过程中。
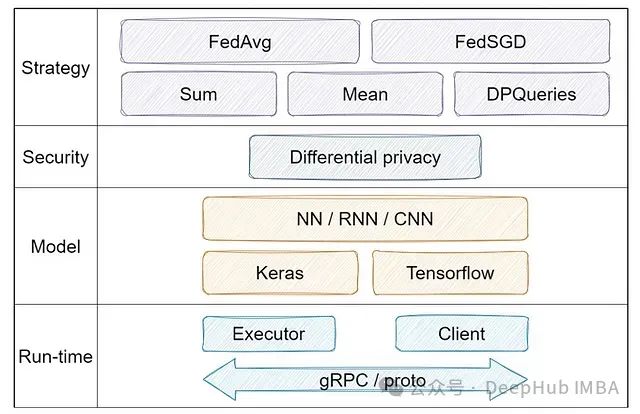
十大主流联邦学习框架:技术特性、架构分析与对比研究
联邦学习领域已发展出多个针对不同技术需求和应用场景的框架工具。这些工具在框架灵活性、使用便捷性和安全特性等方面各具特色。我们这里总结了10个联邦学习具有代表性框架
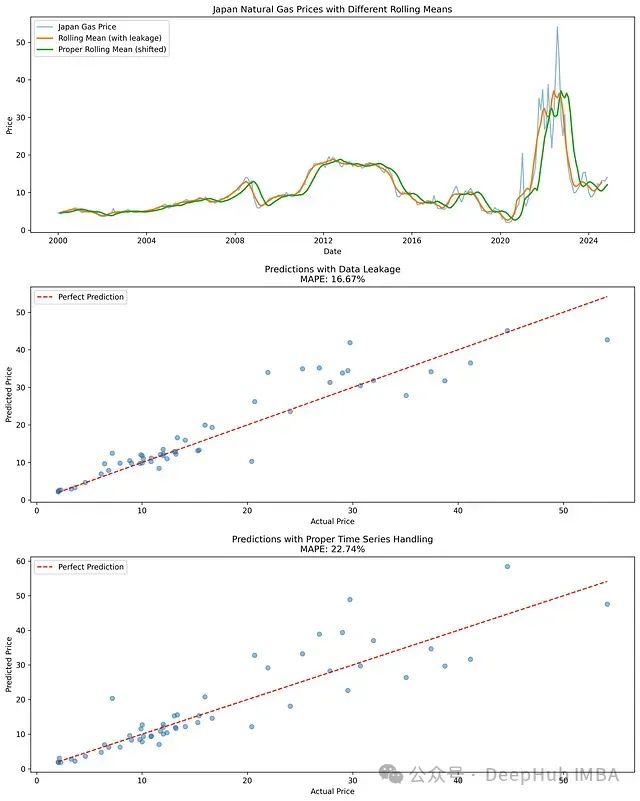
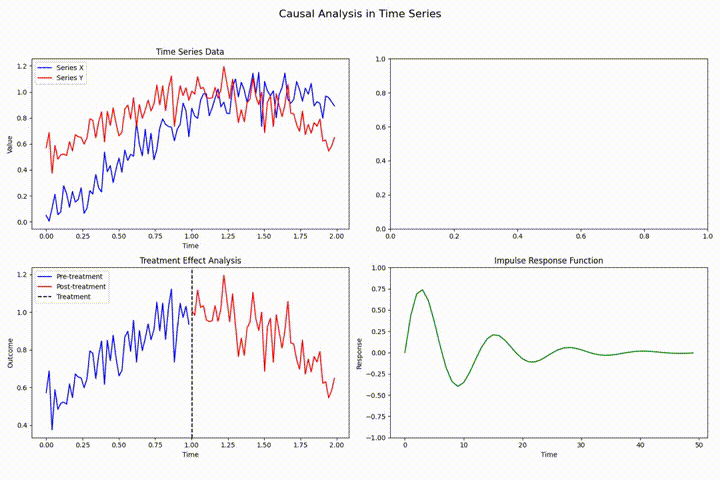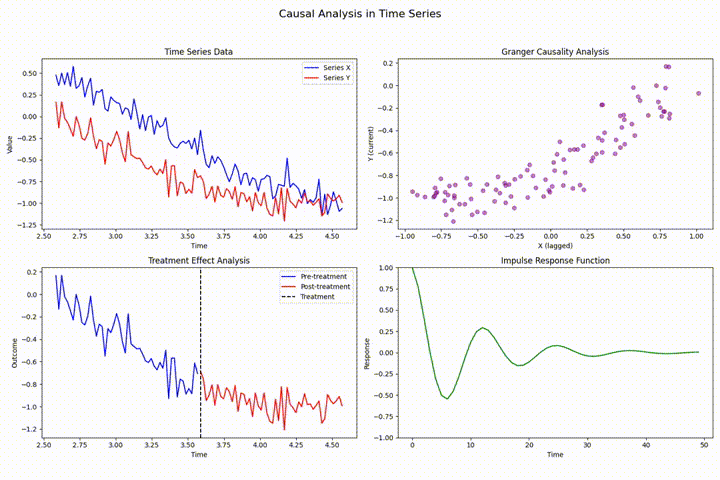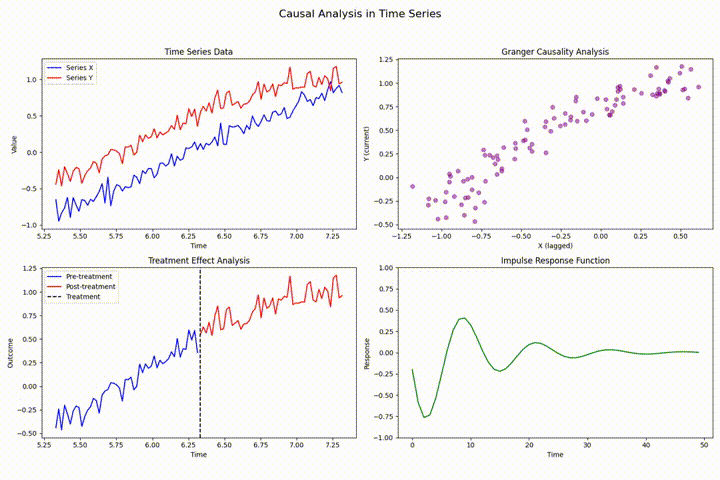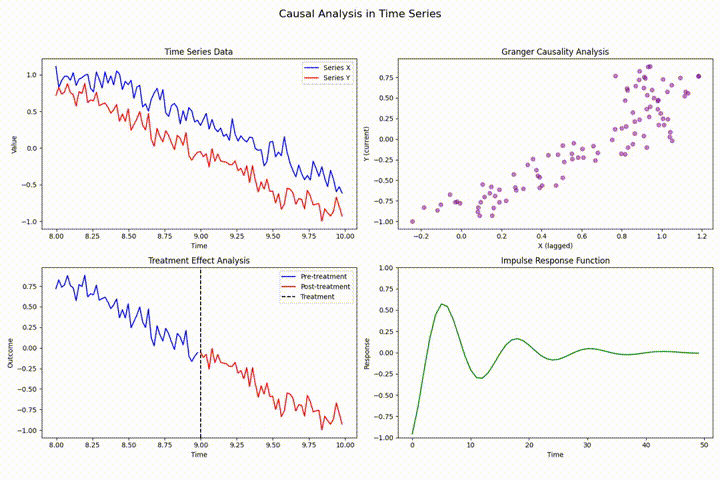
构建可靠的时间序列预测模型:数据泄露检测、前瞻性偏差消除与因果关系验证
在时间序列分析领域中,存在多种可能影响分析结果有效性的技术挑战。其中,数据泄露、前瞻性偏差和因果关系违反是最为常见且具有显著影响的问题。
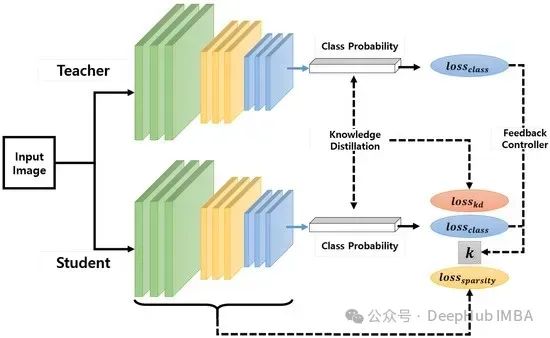
知识蒸馏技术原理详解:从软标签到模型压缩的实现机制
**知识蒸馏**是一种通过性能与模型规模的权衡来实现模型压缩的技术。其核心思想是将较大规模模型(称为教师模型)中的知识迁移到规模较小的模型(称为学生模型)中。本文将深入探讨知识迁移的具体实现机制。

Python高性能编程:五种核心优化技术的原理与Python代码
在性能要求较高的应用场景中,Python常因其执行速度不及C、C++或Rust等编译型语言而受到质疑。然而通过合理运用Python标准库提供的优化特性,我们可以显著提升Python代码的执行效率。
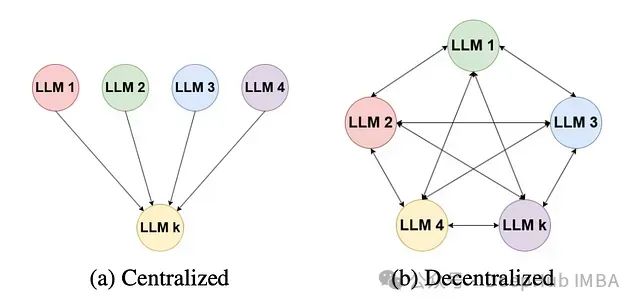
面向长文本的多模型协作摘要架构:多LLM文本摘要方法
论文提出的方法旨在处理长文本文档输入,这类文档可能包含数万字,通常超出大多数标准LLM的上下文窗口限制,论文建立了一个两阶段处理流程

Meta-CoT:通过元链式思考增强大型语言模型的推理能力
Meta-CoT 基于链式思考(CoT)方法,使 LLMs 不仅能够建模推理步骤,还能够模拟“思考”过程。这种转变类似于人类在面对难题时的探索、评估和迭代方式。
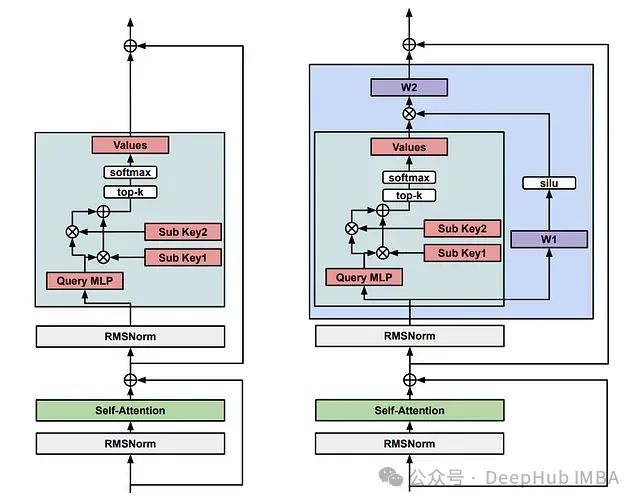
记忆层增强的 Transformer 架构:通过可训练键值存储提升 LLM 性能的创新方法
Meta 研究团队通过开发**记忆层**技术,成功实现了对现有大语言模型的性能提升。该技术通过替换一个或多个 Transformer 层中的前馈网络(FFN)来实现功能。
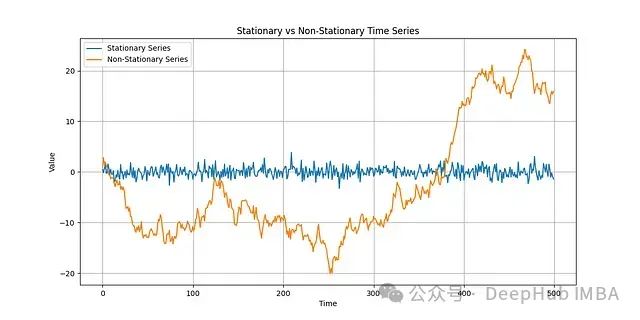
时间序列平稳性的双重假设检验:KPSS与ADF方法比较研究
本文将详细介绍如何运用 **KPSS 检验**和 **Dickey-Fuller 检验**来验证序列的平稳性。这两种检验方法基于不同的统计假设:KPSS 检验的原假设是数据非平稳,而 Dickey-Fuller 检验则假设数据平稳。
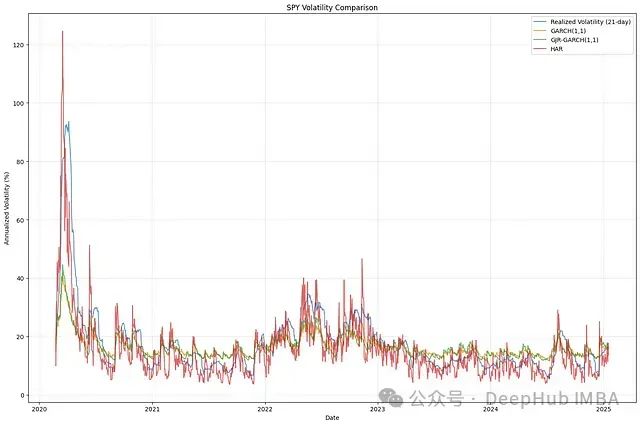
金融波动率的多模型建模研究:GARCH族与HAR模型的Python实现与对比分析
本文着重探讨三种主流波动率建模方法:广义自回归条件异方差模型(GARCH)、Glosten-Jagannathan-Runkle-GARCH模型(GJR-GARCH)以及异质自回归模型(HAR)
时间序列分析中的状态估计:状态空间模型与卡尔曼滤波的隐状态估计
状态空间模型通过构建生成可观测数据的潜在未观测状态模型来进行时间序列分析。作为该方法论的核心,卡尔曼滤波为实时估计这些隐状态提供了一个理论完备的解决方案。本文深入探讨这些方法的理论基础和实践应用,阐述其在多领域的适用性。

提升数据科学工作流效率的10个Jupyter Notebook高级特性
本文将介绍一些高级功能,帮助您在数据科学项目中充分发挥Jupyter Notebooks的潜力。
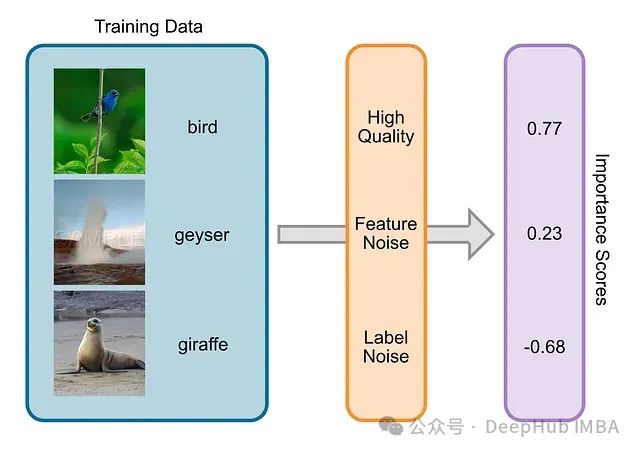
LossVal:一种集成于损失函数的高效数据价值评估方法
*LossVal*提出了一种创新方法,通过将数据价值评估过程直接集成到神经网络的损失函数中,实现了高效的数据价值评估。
Python时间序列分析:使用TSFresh进行自动化特征提取
**TSFresh(基于可扩展假设检验的时间序列特征提取)**是一个专门用于时间序列数据特征自动提取的框架。该框架提取的特征可直接应用于分类、回归和异常检测等机器学习任务。

Coconut:基于连续潜在空间推理,提升大语言模型推理能力的新方法
Coconut的核心机制是在"语言模式"和"潜在模式"之间进行动态切换。语言模式下,模型采用标准语言模型的自回归方式生成token序列。
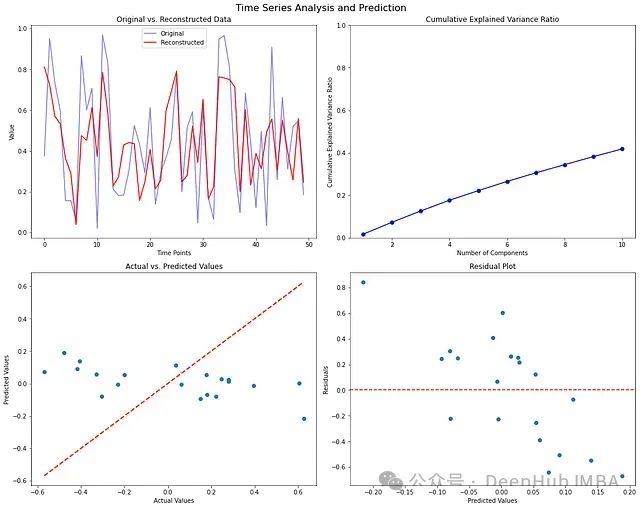
使用Python实现基于矩阵分解的长期事件(MFLEs)时间序列分析
基于矩阵分解的长期事件(Matrix Factorization for Long-term Events, MFLEs)分析技术应运而生。这种方法结合了矩阵分解的降维能力和时间序列分析的特性,为处理大规模时间序列数据提供了一个有效的解决方案。
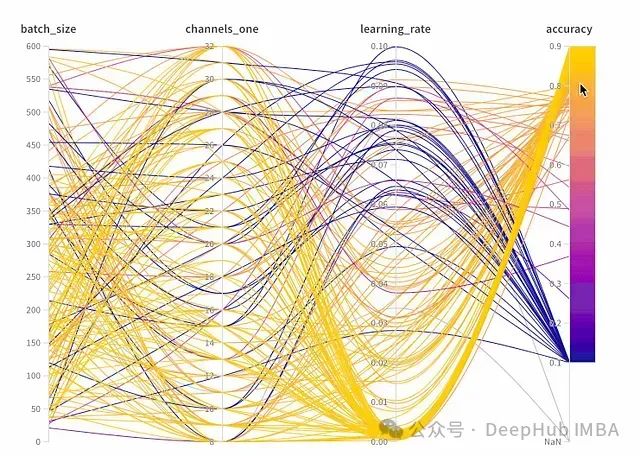
TorchOptimizer:基于贝叶斯优化的PyTorch Lightning超参数调优框架
TorchOptimizer是一个集成了PyTorch Lightning框架和scikit-optimize贝叶斯优化功能的Python库。该框架通过高斯过程对目标函数进行建模,实现了高效的超参数搜索空间探索,并利用并行计算加速优化过程。
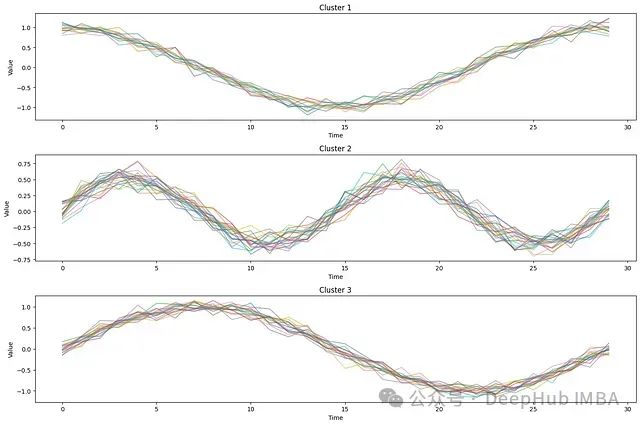
Python时间序列分析工具Aeon使用指南
**Aeon** 是一个专注于时间序列处理的开源Python库,其设计理念遵循scikit-learn的API风格,为数据科学家和研究人员提供了一套完整的时间序列分析工具。该项目保持活跃开发,截至2024年仍持续更新。
深度强化学习实战:训练DQN模型玩超级马里奥兄弟
本文将探讨深度学习在游戏领域的一个具体应用:构建一个能够自主学习并完成**超级马里奥兄弟**的游戏的智能系统。