
Deephub
更多文章请关注公众号:Deephub-IMBA
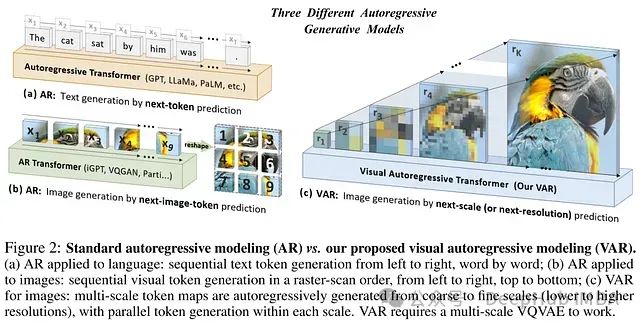
NeurIPS 2024最佳论文,扩散模型的创新替代:基于多尺度预测的视觉自回归架构
VAR通过精确捕捉图像结构特征,实现了高效率、高质量的图像生成。该方法对当前以扩散模型为主导的图像生成领域提出了新的技术方向,为自回归模型开辟了新的发展空间。
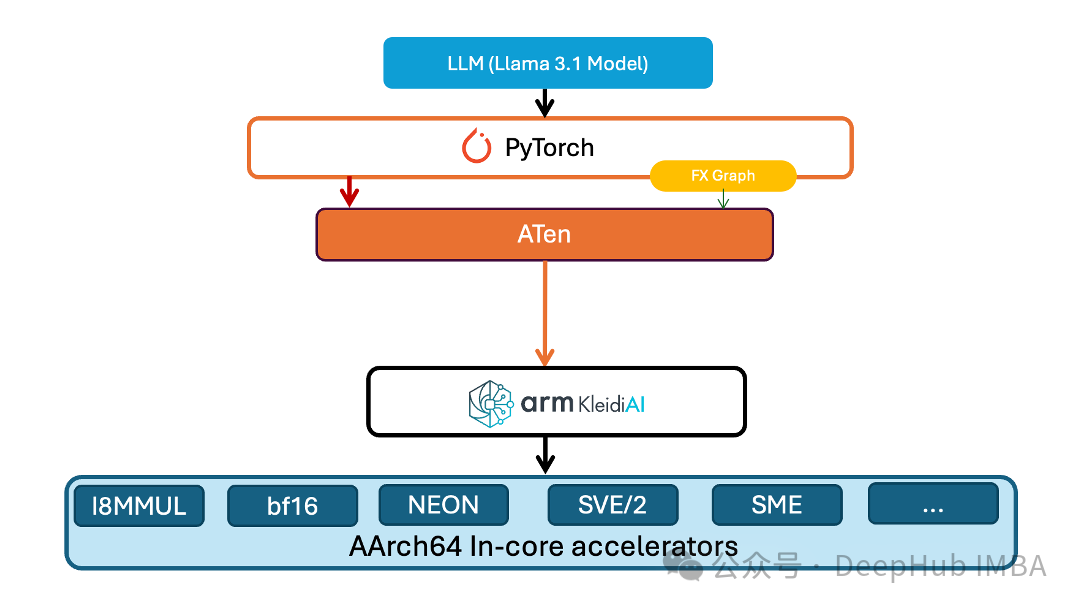
PyTorch团队为TorchAO引入1-8比特量化,提升ARM平台性能
PyTorch团队针对这一问题推出了创新性的技术方案——在其原生低精度计算库TorchAO中引入低位运算符支持。这一技术突破不仅实现了1至8位精度的嵌入层权重量化
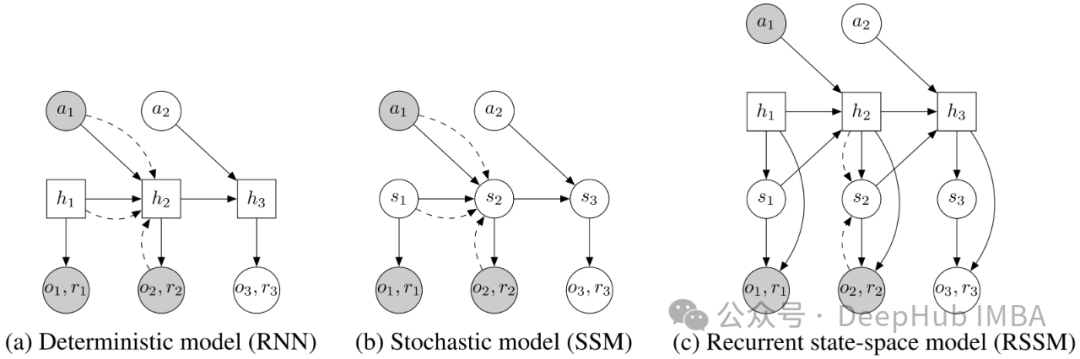
面向强化学习的状态空间建模:RSSM的介绍和PyTorch实现
循环状态空间模型(Recurrent State Space Models, RSSM)最初由 Danijar Hafer 等人在论文《Learning Latent Dynamics for Planning from Pixels》中提出。
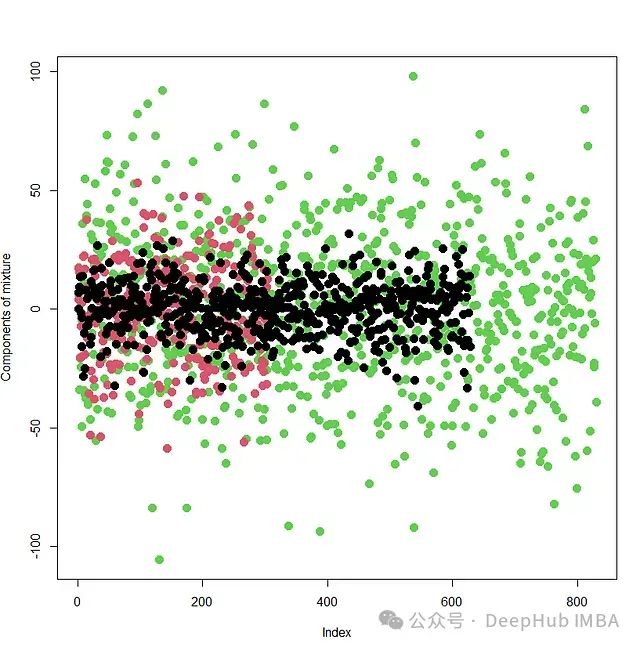
增强回归模型的可解释性:基于MCMC的混合建模与特征选择方法研究
本文将介绍一种通用性极强的正态回归混合模型的实现方法,该方法可适用于各类非正态和非线性数据集,并在参数估计的同时实现模型选择。
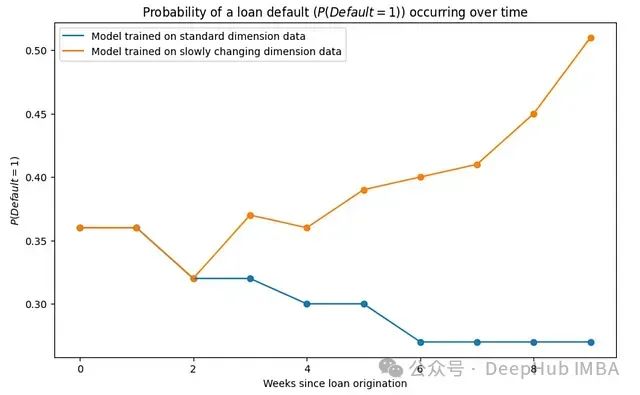
特征时序化建模:基于特征缓慢变化维度历史追踪的机器学习模型性能优化方法
本文将通过缓慢变化维度(Slowly Changing Dimensions)这一数据建模技术来解决上面的这个问题。通过本文的介绍,可以了解历史数据存储对模型性能的重要影响,以及如何在实际应用中实施这一技术方案。
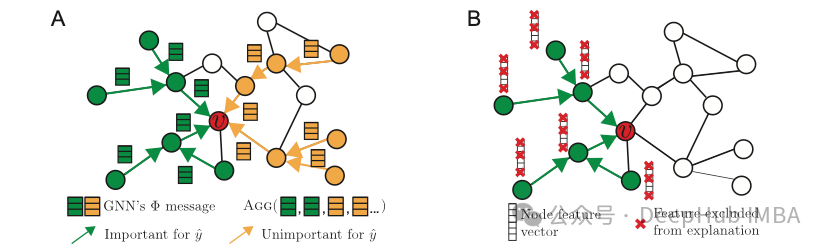
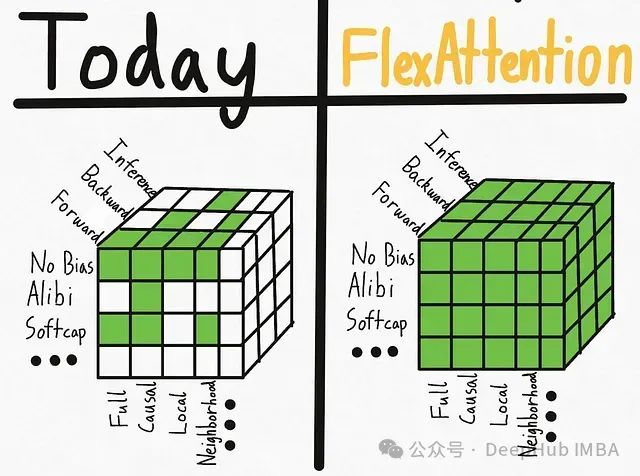
PyTorch FlexAttention技术实践:基于BlockMask实现因果注意力与变长序列处理
本文介绍了如何利用torch 2.5及以上版本中新引入的FlexAttention和BlockMask功能来实现因果注意力机制与填充输入的处理。
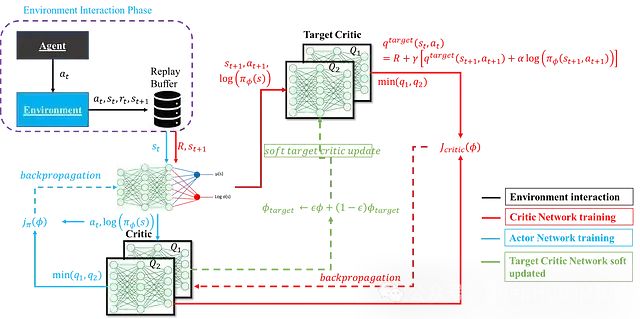
深度强化学习中SAC算法:数学原理、网络架构及其PyTorch实现
软演员-评论家算法(Soft Actor-Critic, SAC)因其在样本效率、探索效果和训练稳定性等方面的优异表现而备受关注。

分布匹配蒸馏:扩散模型的单步生成优化方法研究
分布匹配蒸馏(Distribution Matching Distillation,DMD)通过将多步扩散过程精简为单步生成器来解决这一问题。该方法结合分布匹配损失函数和对抗生成网络损失,实现从噪声图像到真实图像的高效映射,为快速图像生成应用提供了新的技术路径。
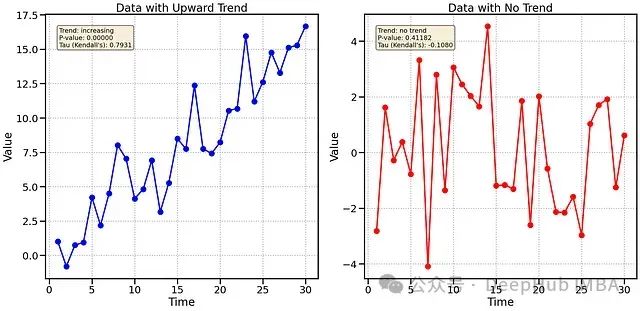
五种被低估的非常规统计检验方法:数学原理剖析与多领域应用价值研究
本文将详细介绍五种具有重要应用价值的统计检验方法,并探讨它们在免疫学(TCR/BCR库分析)、金融数据分析和运动科学等领域的具体应用。
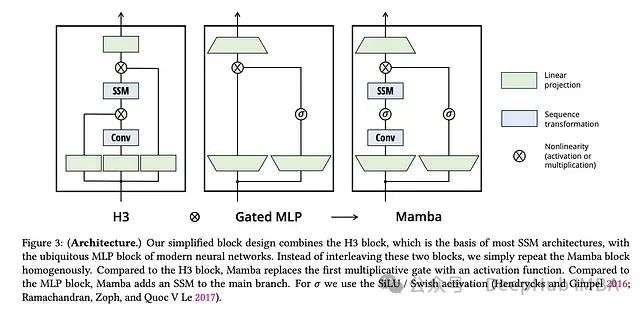
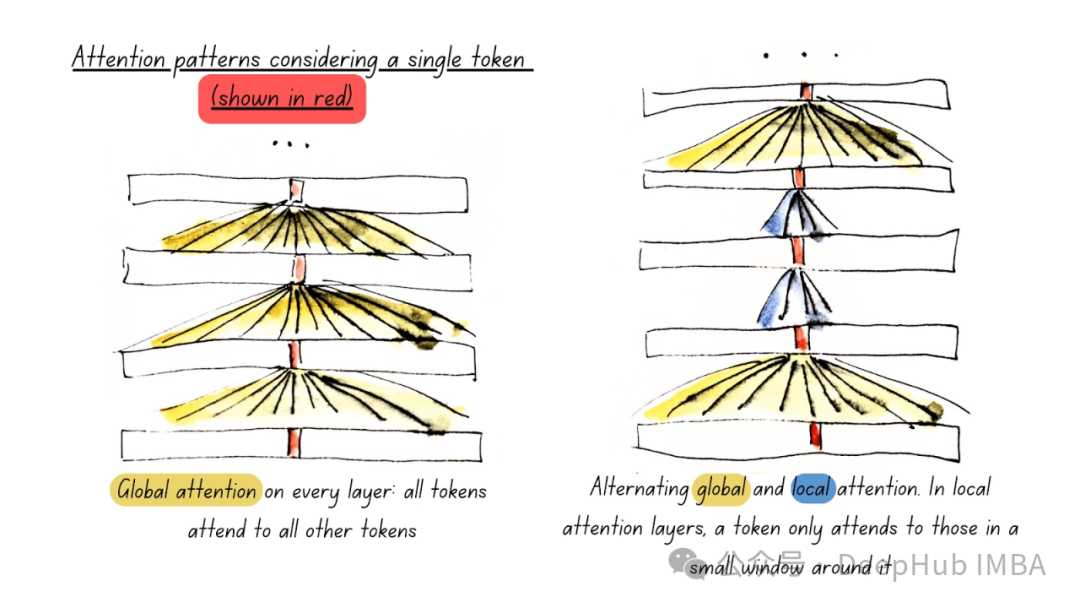
线性化注意力综述:突破Softmax二次复杂度瓶颈的高效计算方案
大型语言模型在各个领域都展现出了卓越的性能,但其核心组件之一——softmax注意力机制在计算资源消耗方面存在显著局限性。本文将深入探讨如何通过替代方案实现线性时间复杂度,从而突破这一计算瓶颈。
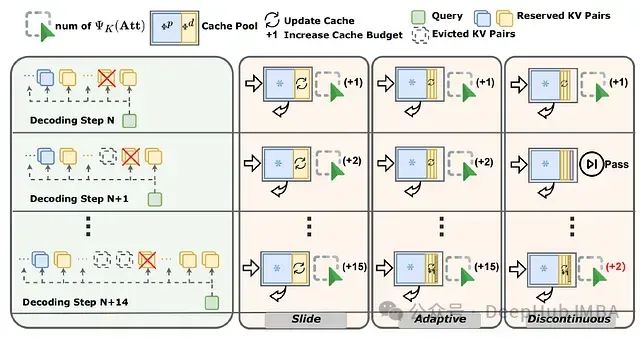
SCOPE:面向大语言模型长序列生成的双阶段KV缓存优化框架
SCOPE框架通过分离预填充与解码阶段的KV缓存优化策略,实现了高效的缓存管理。该框架保留预填充阶段的关键KV缓存信息,并通过滑动窗口、自适应调整和不连续更新等策略,优化解码阶段的重要特征选取,显著提升了长语言模型长序列生成的性能。
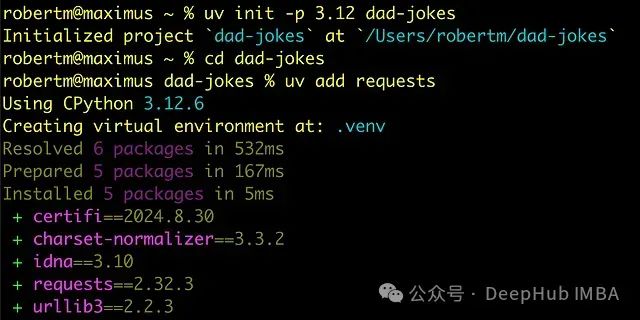
Python环境管理的新选择:UV和Pixi,高性能Python环境管理方案
UV和Pixi代表了Python环境管理工具的两种不同技术路线。UV专注于提供高性能的原生PyPI包管理解决方案,而Pixi则致力于桥接Conda生态系统和PyPI。
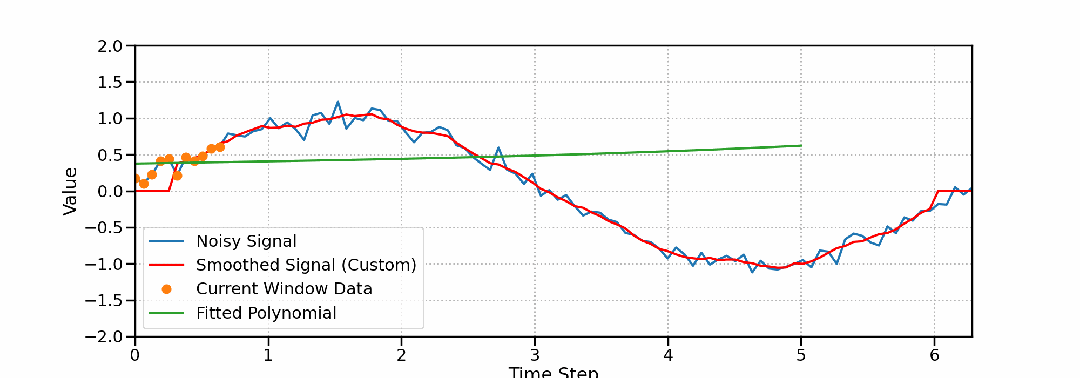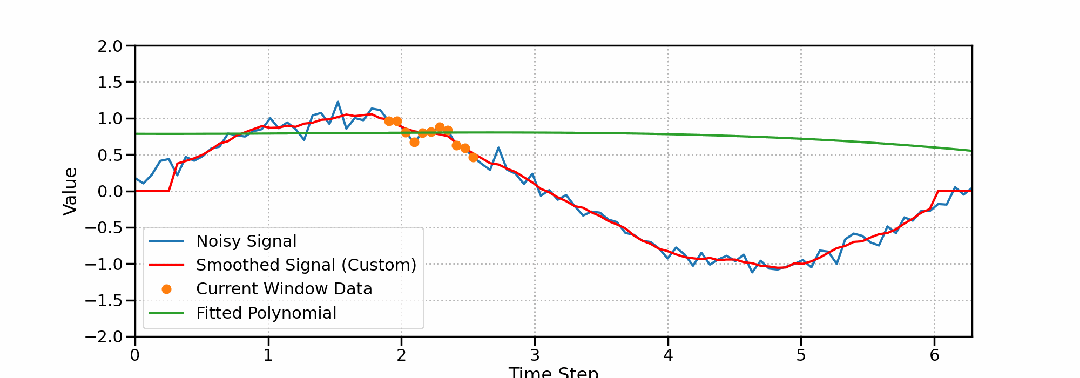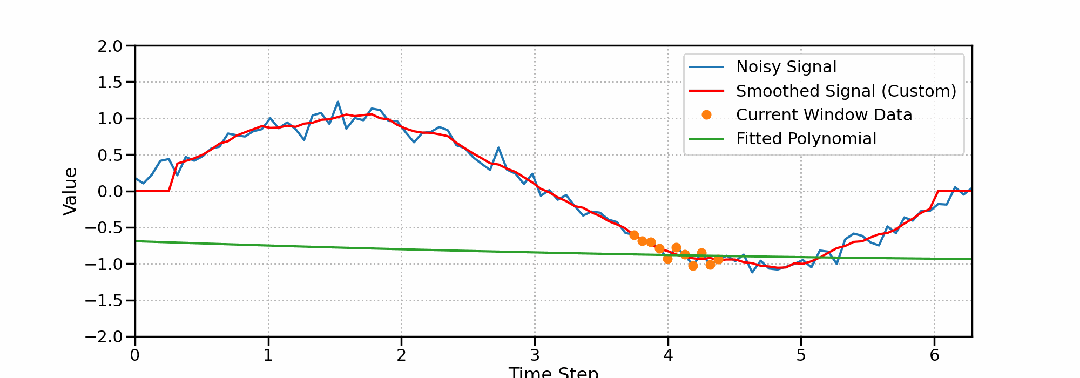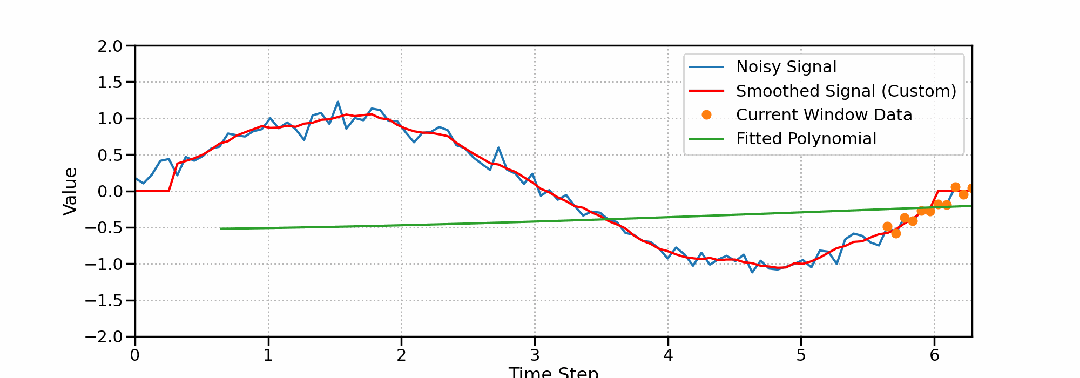
高精度保形滤波器Savitzky-Golay的数学原理、Python实现与工程应用
本文将系统地介绍Savitzky-Golay滤波器的原理、实现和应用。我们将从基本原理出发,通过数学推导和直观解释,深入理解该滤波器的工作机制。同时将结合Python实现,展示其在实际应用中的效果。
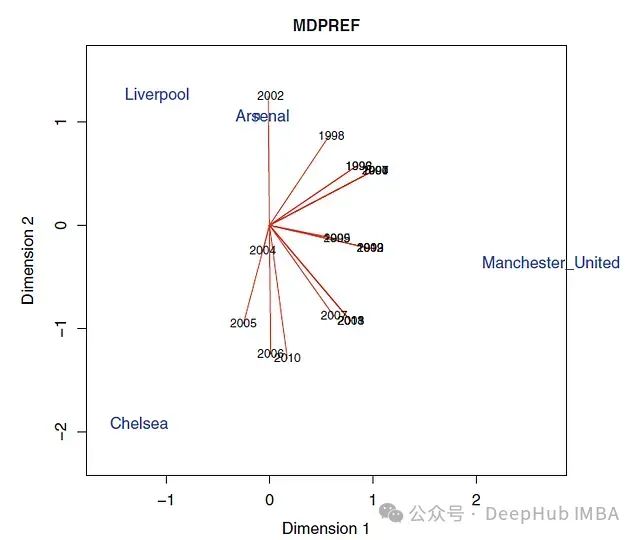
多维偏好分析及其在实际决策中的应用:基于PCA-KMeans的数据降维与模式识别方法
本文本将研究采用主成分分析(Principal Component Analysis, PCA)和K均值聚类算法对鸢尾花数据集进行降维分析和模式识别。
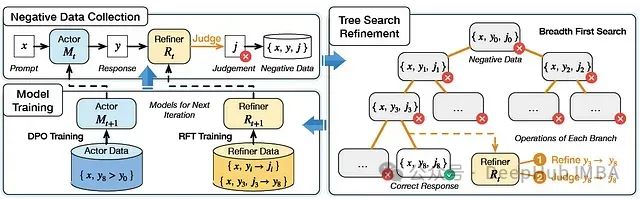
SPAR:融合自对弈与树搜索的高性能指令优化框架
SPAR框架通过自对弈和树搜索机制,生成高质量偏好对,显著提升了大语言模型的指令遵循能力。实验表明,SPAR在指令遵循基准测试中表现优异,尤其在模型规模扩展和判断能力方面展现出显著优势。
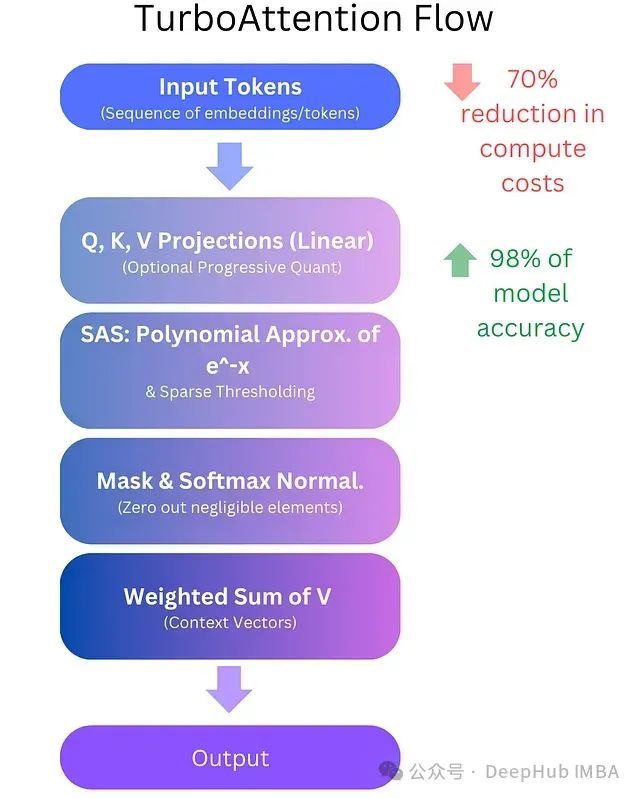
TurboAttention:基于多项式近似和渐进式量化的高效注意力机制优化方案,降低LLM计算成本70%
**TurboAttention**提出了一种全新的LLM信息处理方法。该方法通过一系列优化手段替代了传统的二次复杂度注意力机制,包括稀疏多项式软最大值近似和高效量化技术。
BERT的继任者ModernBERT:融合长序列处理、代码理解与高效计算的新一代双向编码器
。ModernBERT 是一个全新的模型系列,在**速度**和**准确性**两个维度上全面超越了 BERT 及其后继模型。

10个必备Python调试技巧:从pdb到单元测试的开发效率提升指南
本文将介绍10个实用的调试方法,帮助开发者更有效地定位和解决问题。
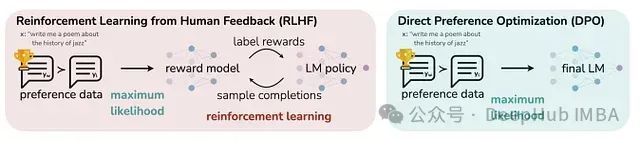
使用PyTorch实现GPT-2直接偏好优化训练:DPO方法改进及其与监督微调的效果对比
本文将探讨RLHF技术,特别聚焦于直接偏好优化(Direct Preference Optimization, DPO)方法,并详细阐述了一项实验研究:通过DPO对GPT-2 124M模型进行调优,同时与传统监督微调(Supervised Fine-tuning, SFT)方法进行对比分析。