
Deephub
更多文章请关注公众号:Deephub-IMBA
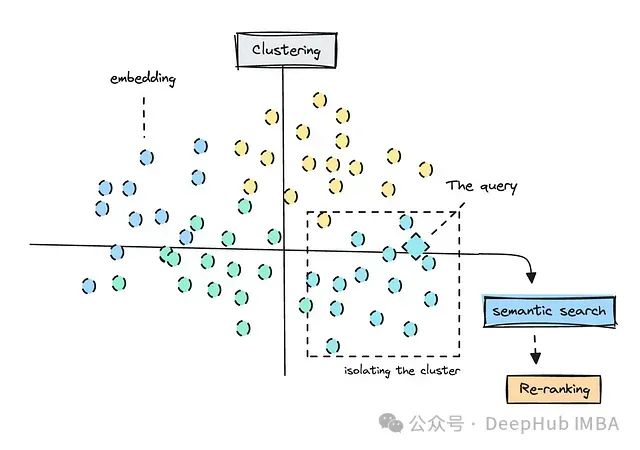
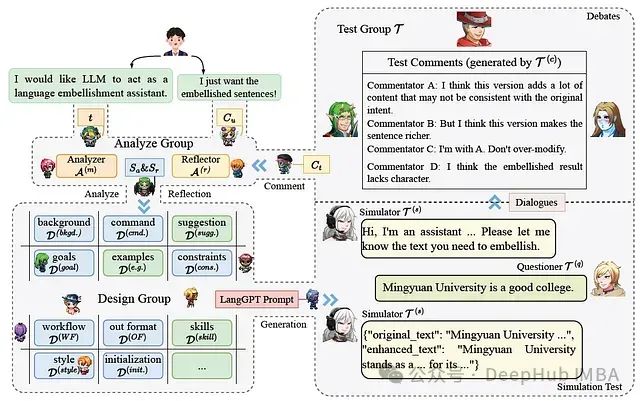
Minstrel自动生成结构化提示,让AI为AI写提示词的多代理提示生成框架
在人工智能快速发展的今天,如何有效利用大型语言模型(LLMs)成为了一个普遍关注的话题。这是9月份的一篇论文,提出了LangGPT结构化提示框架和Minstrel多代理提示生成系统,为非AI专家使用LLMs提供了强大支持。

在Pytorch中为不同层设置不同学习率来提升性能,优化深度学习模型
为网络的不同层设置不同的学习率可能会带来显著的性能提升。本文将详细探讨这一策略的实施方法及其在PyTorch框架中的具体应用
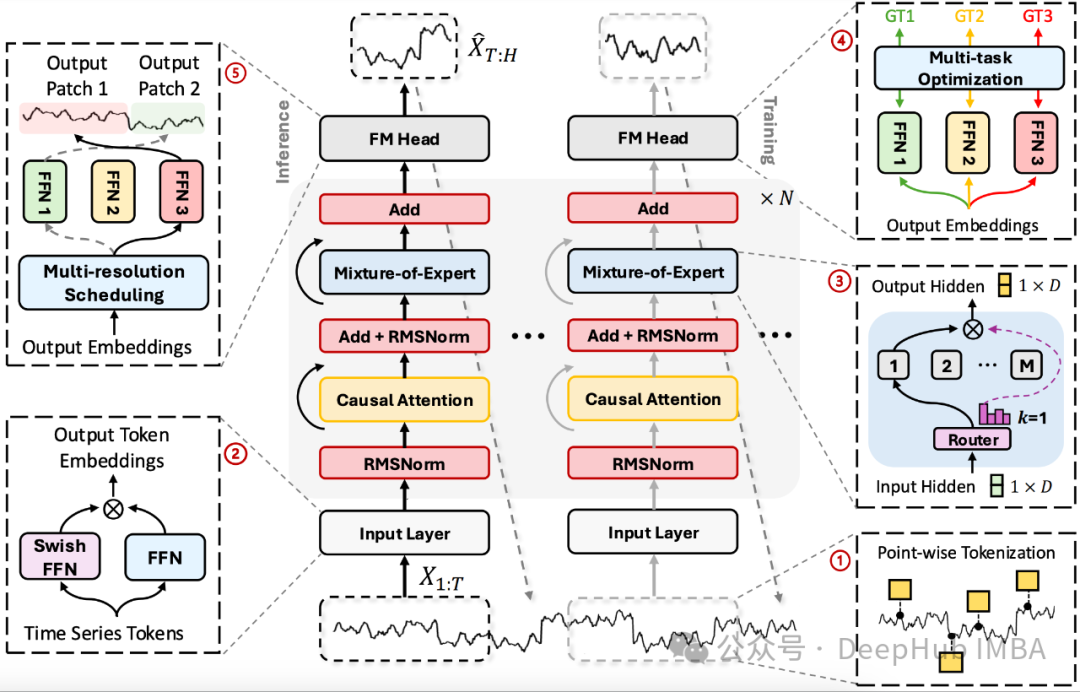
TimeMOE: 使用稀疏模型实现更大更好的时间序列预测
这是9月份刚刚发布的论文TimeMOE。它是一种新型的时间序列预测基础模型,"专家混合"(Mixture of Experts, MOE)在大语言模型中已经有了很大的发展,现在它已经来到了时间序列。

8种数值变量的特征工程技术:利用Sklearn、Numpy和Python将数值转化为预测模型的有效特征
特征工程通常涉及对现有数据应用转换,以生成或修改数据,这些转换后的数据在机器学习和数据科学的语境下用于训练模型,从而提高模型性能。
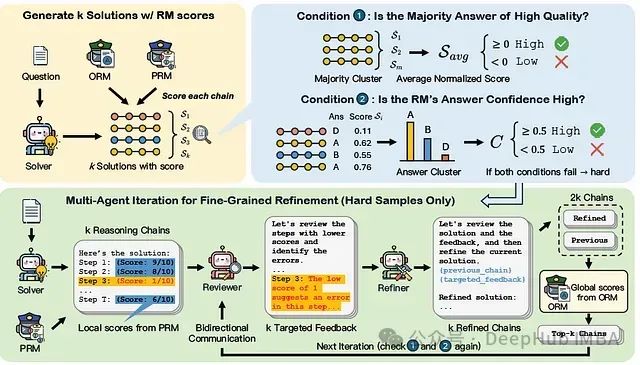
MAGICORE:基于多代理迭代的粗到细精炼框架,提升大语言模型推理质量
论文提出了MAGICORE,一个用于粗到细精炼的多代理迭代框架。MAGICORE旨在通过将问题分类为简单或困难,为简单问题使用粗粒度聚合,为困难问题使用细粒度和迭代多代理精炼,从而避免过度精炼。
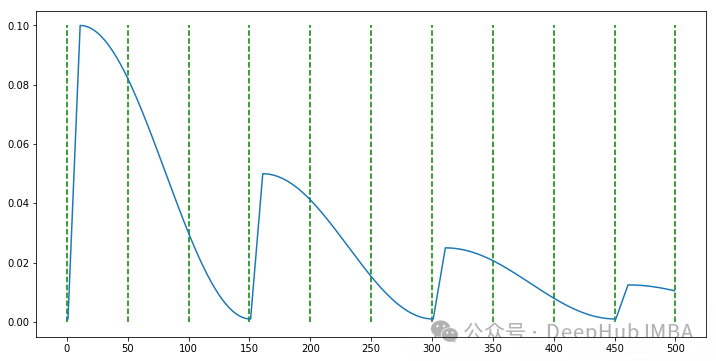
PyTorch自定义学习率调度器实现指南
本文将详细介绍如何通过扩展PyTorch的 ``` LRScheduler ``` 类来实现一个具有预热阶段的余弦衰减调度器。我们将分五个关键步骤来完成这个过程。

AdEMAMix: 一种创新的神经网络优化器
这种算法旨在解决当前广泛使用的Adam及其变体(如AdamW)在利用长期梯度信息方面的局限性。研究者们通过巧妙地结合两个不同衰减率的指数移动平均(EMA),设计出了这种新的优化器,以更有效地利用历史梯度信息。

PyTorch 模型调试与故障排除指南
本文旨在为 PyTorch 开发者提供一个全面的调试指南,涵盖从基础概念到高级技术的广泛内容。

使用GPU 加速 Polars:高效解决大规模数据问题
本文将详细讨论 Polars 中DF的概念、GPU 加速如何与 Polars DF协同工作,以及使用新的 CUDA 驱动执行引擎可能带来的性能提升。
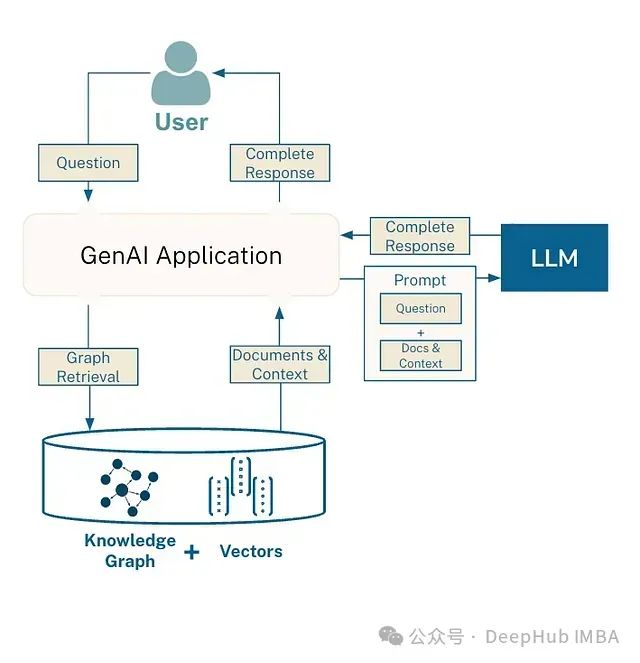
GraphRAG 与 RAG 的比较分析
Graph RAG 技术通过引入图结构化的知识表示和处理方法,显著增强了传统 RAG 系统的能力。它不仅提高了信息检索的准确性和完整性,还为复杂查询和多步推理提供了更强大的支持。

让模型评估模型:构建双代理RAG评估系统的步骤解析
我们将介绍一个基于双代理的RAG(检索增强生成)评估系统。该系统使用生成代理和反馈代理,基于预定义的测试集对输出进行评估。或者更简单的说,我们使用一个模型来评估另外一个模型的输出。
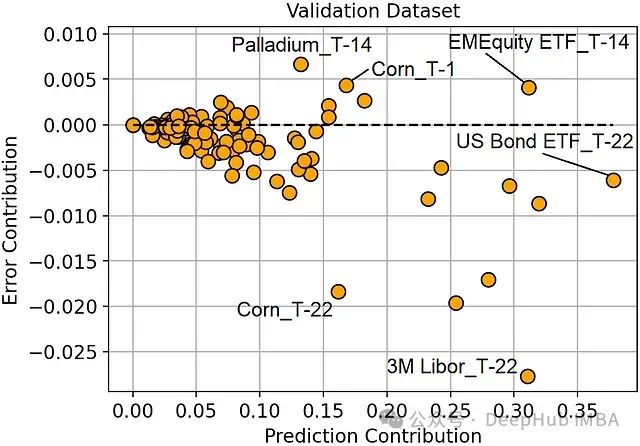
机器学习模型中特征贡献度分析:预测贡献与错误贡献
本文将探讨特征重要性与特征有效性之间的关系,并引入两个关键概念:预测贡献度和错误贡献度。
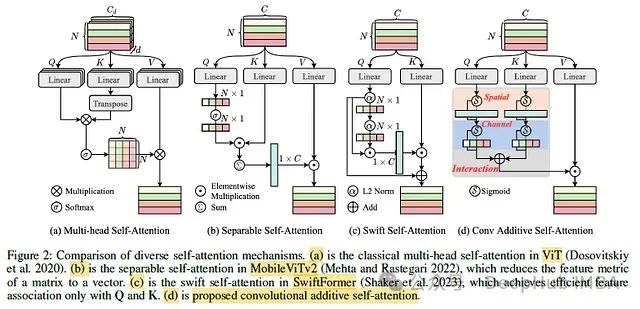
CAS-ViT:用于高效移动应用的卷积加法自注意力视觉Transformer
这是8月份再arxiv上发布的新论文,我们下面一起来介绍这篇论文的重要贡献
概率分布深度解析:PMF、PDF和CDF的技术指南
本文将深入探讨概率分布,详细阐述概率质量函数(PMF)、概率密度函数(PDF)和累积分布函数(CDF)这些核心概念,并通过实际示例进行说明。
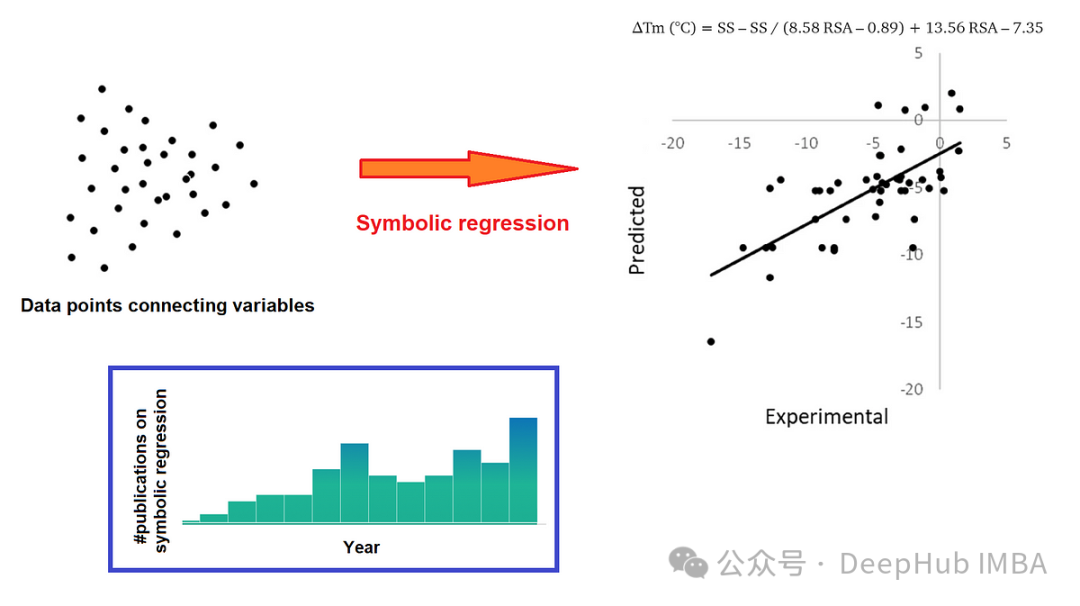
数据稀缺条件下的时间序列微分:符号回归(Symbolic Regression)方法介绍与Python示例
有多种方法可以处理时间序列数据中的噪声。本文将介绍一种在我们的研究项目中表现良好的方法,特别适用于时间序列概况中数据点较少的情况。
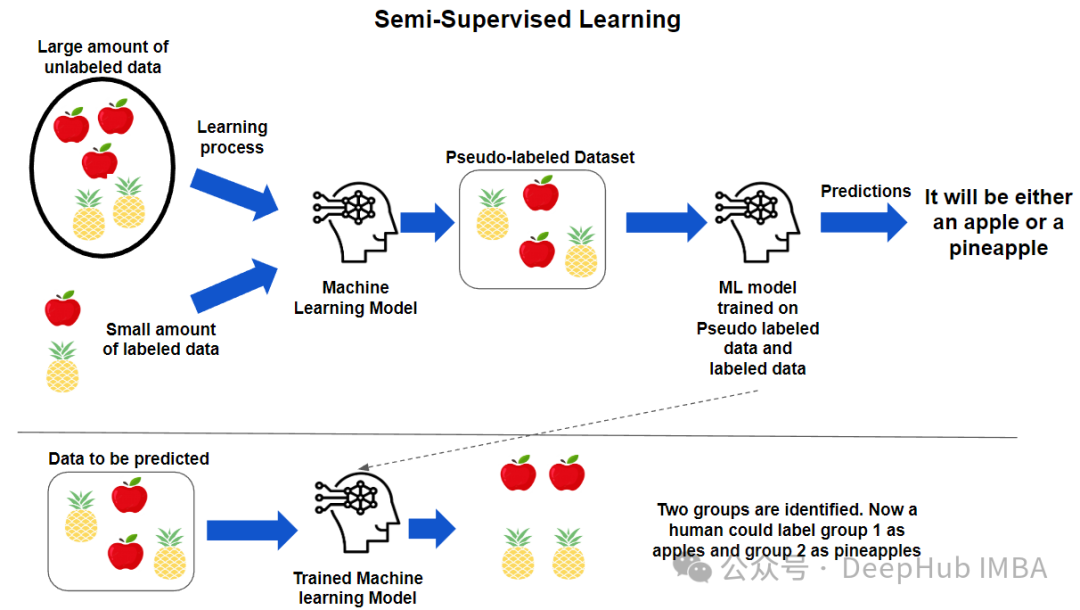
利用未标记数据的半监督学习在模型训练中的效果评估
本文将介绍三种适用于不同类型数据和任务的半监督学习方法。我们还将在一个实际数据集上评估这些方法的性能,并与仅使用标记数据的基准进行比较。
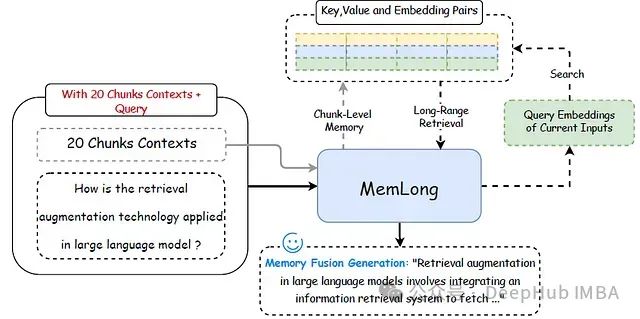
MemLong: 基于记忆增强检索的长文本LLM生成方法
本文将介绍MemLong,这是一种创新的长文本语言模型生成方法。MemLong通过整合外部检索器来增强模型处理长上下文的能力,从而显著提升了大型语言模型(LLM)在长文本处理任务中的表现。
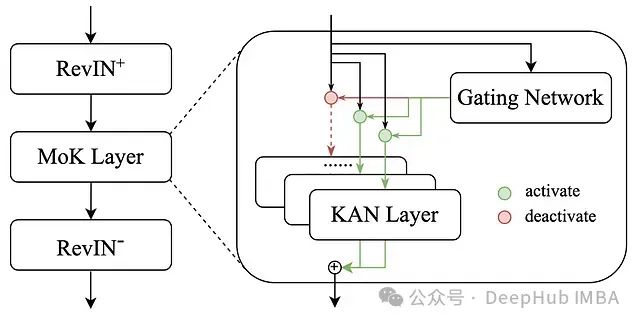
KAN专家混合模型在高性能时间序列预测中的应用:RMoK模型架构探析与Python代码实验
本文将深入探讨RMoK模型的架构和内部机制,并通过Python实现一个小型实验来验证其性能。
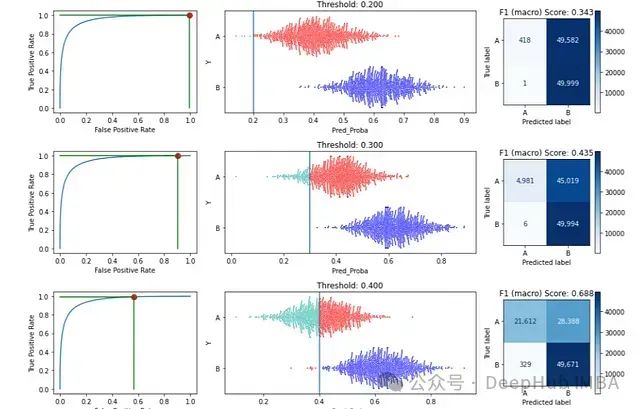
使用ClassificationThresholdTuner进行二元和多类分类问题阈值调整,提高模型性能增强结果可解释性
本文将深入探讨阈值调整的具体机制 — 特别是在多类分类问题中,这个过程可能会比较复杂。我们还将介绍一个名为 ClassificationThresholdTuner 的开源工具,这是笔者开发的一个自动化阈值调整和解释的工具。