
这是9月发布的一篇论文,Pagliardini等人在其论文中提出了一种新的优化算法——AdEMAMix。这种算法旨在解决当前广泛使用的Adam及其变体(如AdamW)在利用长期梯度信息方面的局限性。研究者们通过巧妙地结合两个不同衰减率的指数移动平均(EMA),设计出了这种新的优化器,以更有效地利用历史梯度信息。
研究动机
作者们指出,传统的动量优化器通常使用单一EMA来累积过去的梯度,这种方法面临一个两难困境:
- 较小的衰减率(β)会导致优化器对近期梯度给予较高权重,但快速遗忘旧梯度。
- 较大的衰减率可以保留更多旧梯度信息,但会减慢对近期梯度的响应。
研究者们发现,即使在数万步训练之后,梯度信息仍然可能保持有用。这一发现促使他们设计了AdEMAMix,以同时利用近期和远期的梯度信息。
AdEMAMix算法
核心思想
AdEMAMix的核心在于使用两个EMA项:
- 快速EMA(低β值): m₁ = β₁m₁ + (1-β₁)g
- 慢速EMA(高β值): m₂ = β₃m₂ + (1-β₃)g
其中g为当前梯度,β₁和β₃分别为快速和慢速EMA的衰减率。
参数更新规则
作者们给出了AdEMAMix的参数更新规则:
θ = θ - η((m̂₁ + αm₂) / (√v̂ + ε) + λθ)
其中θ为模型参数,η为学习率,α为权衡两个EMA项的系数,v̂为Adam中的二阶矩估计,λ为权重衰减系数。
![]
稳定性改进
为了提高训练稳定性,研究者们引入了α和β₃的调度器。这些调度器在训练初期逐渐增加α和β₃的值,避免了由于过大的动量值导致的早期训练不稳定。
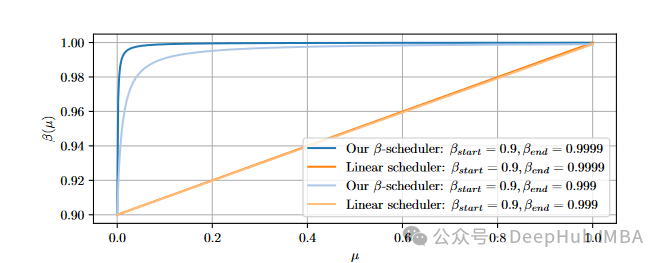
AdEMAMix的β₃调度器。与线性调度相比,该调度器在β值较小时增长较快,在β值较大时增长较慢,更好地适应了不同β值对优化过程的影响。
实验设置
研究者们在两个主要任务上评估了AdEMAMix的性能:
语言建模任务
- 模型:Transformer架构,参数规模从110M到1.3B
- 数据集:RedPajama v2
- 评估指标:验证集perplexity、训练速度、模型遗忘程度
视觉任务
- 模型:Vision Transformer (ViT),24M和86M参数
- 数据集:ImageNet-1k和ImageNet-21k
- 评估指标:测试集损失、Top-1准确率
主要实验结果
语言建模性能
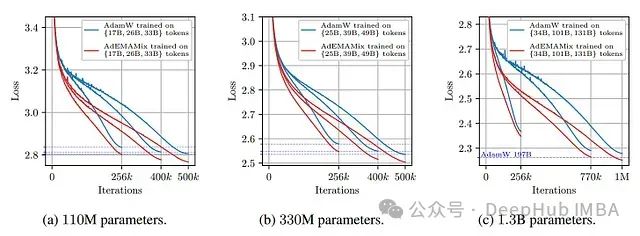
1.3B参数语言模型在不同训练token数下的性能比较。图中显示AdEMAMix仅使用101B tokens就达到了AdamW使用197B tokens的性能,节省了近50%的训练数据。
研究结果表明,AdEMAMix在各种模型规模下均显著优于AdamW:
- 对于110M参数模型,AdEMAMix训练256k步的性能相当于AdamW训练500k步。
- 对于1.3B参数模型,AdEMAMix使用770k步(约101B tokens)即可达到AdamW使用1.5M步(约197B tokens)的性能。
这些结果充分说明了AdEMAMix在优化效率上的显著优势。
模型遗忘分析
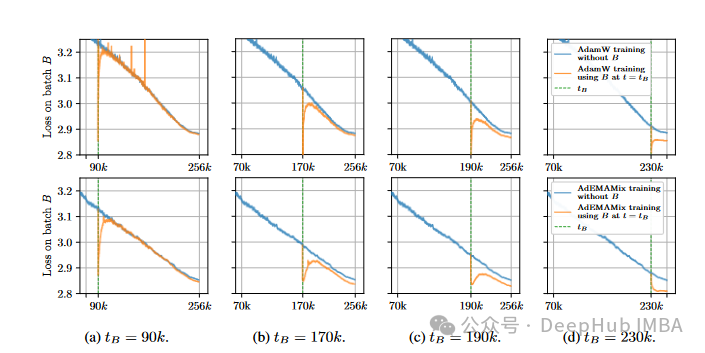
AdEMAMix和AdamW在训练过程中对特定batch的遗忘程度比较。AdEMAMix表现出更慢的遗忘速度,有助于提高学习稳定性。
作者们通过跟踪某个batch在训练过程中的loss变化来衡量遗忘程度。结果表明:
- AdEMAMix模型遗忘训练数据的速度更慢。
- 使用AdEMAMix时,早期训练的batch对最终模型的影响更大。
研究者们认为,这一特性有助于提高学习的稳定性和泛化能力。
视觉任务性能
在视觉任务中,AdEMAMix同样表现出色:
- 在ImageNet-21k上,AdEMAMix consistently优于AdamW,尤其是在数据量较大时。
- 在ImageNet-1k上,当模型容量与数据量比例适中时,AdEMAMix仍能获得性能提升。
这些结果表明,AdEMAMix的优势不仅限于语言建模任务,在计算机视觉领域同样适用。

计算开销
尽管AdEMAMix引入了额外的计算步骤,但研究者们发现其带来的计算开销可以忽略不计:
- 训练时间仅比AdamW略长(不足2%增加)
- 在分布式训练环境中,预期额外开销会进一步减少
考虑到AdEMAMix可以显著减少达到同等性能所需的训练步数,作者们认为这微小的额外开销是完全可以接受的。
结论与未来展望
Pagliardini等人通过AdEMAMix成功地在多个任务上展现出显著优于AdamW的性能。这种新的优化器不仅加快了模型收敛速度,还提高了学习稳定性,为大规模神经网络的高效训练提供了新的方法。
研究结果表明,梯度信息可以在数万步训练中保持有效,这一发现为进一步探索非EMA类型的梯度累积方法开辟了新方向。作者们建议未来的研究可能会探索:
- 在更多任务和模型架构上验证AdEMAMix的有效性
- 研究AdEMAMix对模型泛化能力的影响
- 探索将AdEMAMix与其他优化技术(如学习率调度、梯度裁剪等)结合的方法
总的来说,AdEMAMix为深度学习优化领域带来了新的思路,有望在未来的研究和应用中发挥重要作用。研究者们期待看到这种新优化器在更广泛的场景中的应用和进一步的改进。
论文地址:
https://arxiv.org/abs/2409.03137
源代码: