Pytorch中torch.sort()和torch.argsort()函数解析
torch.sort(),如下图所示:输入input,在dim维进行排序,默认是dim=-1对最后一维进行排序,descending表示是否按降序排,默认为False,输出排序后的值以及对应值在原输入imput中的下标3.1 dim = -1 表示对每行中的元素进行升序排序,descending=F
SE注意力机制
卷积神经网络(CNN)的核心构建块是卷积算子,它使网络能够通过融合每个层的局部感受野内的空间和通道信息来构建信息特征。大量的先前研究已经调查了这种关系的空间成分,试图通过增强整个特征层次的空间编码质量来增强CNN的代表能力。在这项工作中,我们转而关注信道关系,并提出了一种新的架构单元,我们称之为“挤
深度学习之wandb的基本使用
在深度学习训练网络的过程中,由于网络训练过程时间长,不可能一直关注训练中的每一轮结果,因此我们需要将训练过程中的结果可视化,留作后续的查看,从而确定训练过程是否出错。因此,我们需要使用到可视化工具,常用的几种可视化工具有:`wandb`(在线可视化)、`tensorboard`、这里主要介绍`wan
全网最全极限学习机(ELM)及其变种的开源代码分享
愿之称为全网最全的开源极限学习机(ELM)及其变种的开源代码分享~
DBNet实战:详解DBNet训练与测试(pytorch)
论文连接:https://arxiv.org/pdf/1911.08947.pdfgithub链接:github.com网络结构首先,图像输入特征提取主干,提取特征;其次,特征金字塔上采样到相同的尺寸,并进行特征级联得到特征F;然后,特征F用于预测概率图(probability map P)和阈值图
【已解决】安装cv2时Building wheel for opencv-python终端卡死
本文探究安装cv2时Building wheel for opencv-python终端卡死的原因并予以解决
yolov5修改骨干网络-使用自己搭建的网络-以efficientnetv2为例
efficientnet则是通过NAS搜索,同时增加width、depth以及resolution,使网络结构达到最优。下表为EfficientNet-B0的网络框架(B1-B7就是在B0的基础上修改Resolution,Channels以及Layers),可以看出网络总共分成了9个Stage。第一

stable diffusion 2.0本地部署和微调
今天我们来围绕着AUTOMATIC1111的stable-diffusion-webui介绍如何将stable diffusion 2.0 部署到本地,还有在哪里下载基本模型和微调。
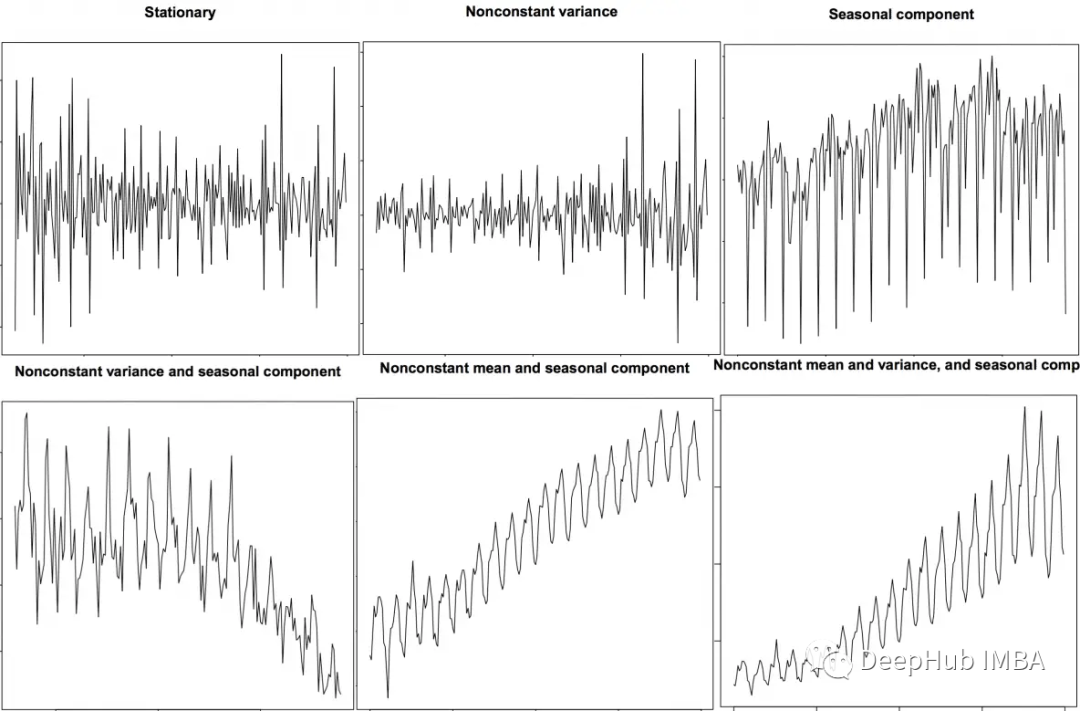
时间序列特征提取的Python和Pandas代码示例
使用Pandas和Python从时间序列数据中提取有意义的特征,包括移动平均,自相关和傅里叶变换。
vit的cam和注意力图: VIT模型的可解释性
VIT的热力图怎么画
人工智能学习(十):什么是贝叶斯网络——伯克利版
模型描述了世界的(一部分)运作方式。模型总是简化的:可能没有考虑到每个变量,不关心或者无法为其建模。可能没有考虑到变量之间的所有相互作用,无法发现或者代价昂贵。所有的模型都是错的;但有些是有用的。在<人工智能学习(七):概率>中,我们主要谈论了动作,选择动作,动作序列,链式推理。但是在这一篇博文,我
调频连续波(FMCW)原理
FMCW(Frequency Modulated Continuous Wave),即调频的连续信号。在许多方面得到应用,比如生物雷达,车载雷达,无人机雷达等等方面都有FMCW波的应用,目前的商业化的雷达模块大多使用的该原理来实现雷达的测距,测速。
【目标检测】YOLOv5模型从大变小,发生了什么?
记录一个实验小问题
【达摩院OpenVI】AIGC技术在图像超分上的创新应用
随着扩散模型DiffusionModel在理论和实践中的有效性得到越来越多的验证,在大数据、大模型的加持下,多模态学习发展如火如荼,促成了当今AIGC的火爆。同时以此为基础的视觉增强底层任务,也带来了一些突破性成果。今天重点给大家展示下,扩散模型在图像超分辨率这方面的新的应用,展现出其超过GAN的生
NLP关系抽取和事件抽取
关系抽取又称实体关系抽取,以实体识别为前提,在实体识别之后,判断给定文本中的任意两个实体是否构成事先定义好的关系,是文本内容理解的重要支撑技术之一,对于问答系统,智能客服和语义搜索等应用都十分重要。当前深度学习方法在关系抽取任务上取得了很好的效果,这是由于深度学习可以自动抽取文本特征。深度学习做关系
【数据分析实战】基于python对Airbnb房源进行数据分析
在本文中,我们基于Airbnb房源进行了数据分析,并从多种角度对其展开了探索性的工作,这对于养成数据分析习惯有很大的帮助。
OTFS从零开始(一)
传统信号有两种表示方法。一种是时间表示法,即信号作为时间的函数(delta函数的叠加),另一种是频率表示法,即信号作为频率的函数(复指数的叠加)。这两种表示法可以用傅里叶变换来互相变换。而时间表示和频率表示是互补的。这种互补性的数学表达方式是由海森堡不确定性原理确定的,该原理指出一个信号不能同时在时
KITTI数据集详解
三维目标检测常用的数据集——KITTI数据集的详解,包括文件目录、文件格式说明、文件使用说明。
光流估计(三) PWC-Net 模型介绍
PWC-Net 的网络模型在由提出,发表文章为与FlowNet2.0模型相比,PWCNet的大小缩小了17倍,训练成本更低且精确度稳定。此外,它在Sintel数据集(1024×436)图像上的运行速度大约为35 fps,是光流估计深度学习中非常基础且具有重要意义的一个网络模型。FlowNet2.0
你升级GPT-4了吗?,如何申请GPT-4 API?最全攻略
如何申请GPT-4 API?必须有ChatGPT plus 会员,才能调用GPT-4 API



