10大AI搜索终极比拼,谁最强?超详细评测
10大AI搜索终极比拼
Qualcomm QCS6490 开发板运行高通AI Hub图像分类程序
高通的 AI Hub 是一个全新的 AI 模型库,专为搭载骁龙和高通平台的终端设备提供优化的 AI 模型。这些模型经过验证,可在不同执行环境中部署,实现卓越的终端侧 AI 性能、降低内存占用并提高能效。本文将介绍如何在Qualcomm QCS6490开发板上运行高通AI Hub图像分类提供的示例An
人工智能 | 大模型之提示词工程:少样本提示
在学习零样本提示之后,很容易联想到与之对应的少样本提示。零样本提示虽然已经能解决大部分问题,但是在面对一些更复杂的任务的时候,表现并不是很好。而少样本提示可以通过提示词,直接为大模型提供对应的示例,更方便大模型理解我们的想法。
通义千问AI+Java
基于“通义千问”AI模型,帮助实现Java项目。
AI人工智能代理工作流AI Agent WorkFlow:互动学习在工作流中的角色与方法
1.背景介绍本文档旨在探讨AI人工智能代理工作流(AI Agent WorkFlow)中互动学习的角色与方法。随着物联网、大数据、云计算等技术的快速发展,智能系统越来越需要具备自主学习和适应环境变化的能力。在这样的背景下,互动学习成为了AI代理工作流中的一个重要组成部分。2.核心概念与联系
手把手带你搭建一个语音对话机器人,5分钟定制个人AI小助手(新手入门篇)
如果你的身边有一个随时待命、聪明绝顶的AI小助手,能够听懂你的话,理解你的需求,用温暖的声音回应你,会是一种什么体验?今天,带大家一起搭建一个语音对话机器人,拥有一个专属的个人AI小助手。本文面向技术小白,以最通俗易懂的语言,最贴心的步骤指导,确保你能够轻松上手,快速掌握。
AI的好处和坏处!
总的来说,虽然AI技术为社会带来了诸多便利和进步,但同时也引发了一系列的挑战和问题。在发展AI技术的同时,我们需要对这些潜在的风险保持警觉,并采取相应的措施来减轻其负面影响。
分子AI预测赛笔记
#ai夏令营#datawhale#夏令营
为啥AI要卷应用?
李彦宏提出的“不要卷模型,要卷应用”这一观点,在人工智能(AI)领域引发了广泛的讨论和深思。这句话不仅是对当前AI技术发展现状的深刻洞察,更是对未来AI技术发展方向的明确指引。本文对这一观点的全面理解和深入剖析。
AI赋能新闻写作:自动生成新闻报道
1. 背景介绍新闻报道作为信息传播的重要途径,一直以来都扮演着不可或缺的角色。然而,传统的新闻写作流程往往需要耗费大量的人力物力,从事件的采集、核实、撰写到最终的发布,都需要记者和编辑付出巨大的努力。随着人工智能技术的飞速发展,AI赋能新闻写作逐渐成为可能,自动生成新闻报道的技术也应运而生。1.
使用Python进行开发人工智能
以上是使用 Python 开发人工智能的基本学习路线 通过循序渐进地学习 你将逐步掌握这项技术 并能够应用到各种实际场景中!
2024 年 Python 基于 Kimi 智能助手 Moonshot Ai 模型搭建微信机器人(更新中)
Telegram(非正式简称TG或电报)是跨平台的即时通讯软件,其客户端是自由及开放源代码软件,但服务器端是专有软件。用户可以相互交换加密与自毁消息(类似于“阅后即焚”),发送照片、影片等所有类型文件。官方提供手机版(Android、iOS、Windows Phone)、电脑版(Microsoft
软件测试下的AI之路(5)
所以在我们制定断言预期值的时候需要保持明确的目标,很多测开同学在写自动测试脚本的过程中会为了断言而去定制断言的具体内容,这个做法本身没有什么错误,举个例子,要测试一个登录页面登录成功后跳转到对应的业务界面,那测试用例的断言内容可以是跳转页面中的某一个元素的内容嘛?这些说的种种其实都是没有搞清楚断言的
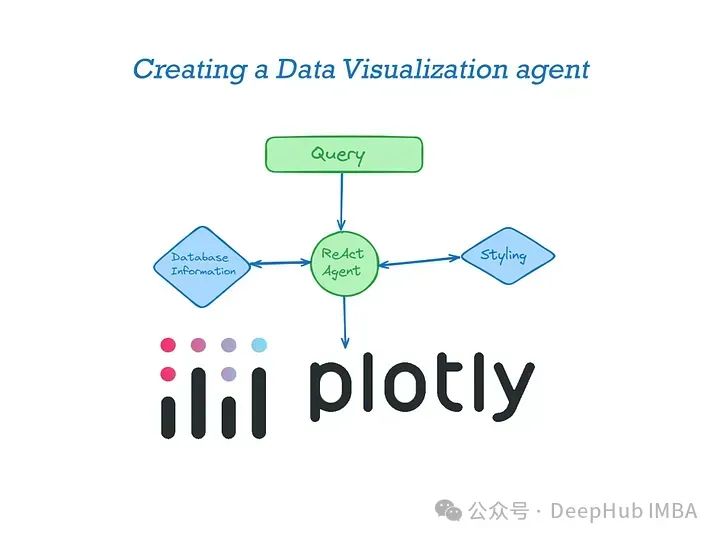
LLM代理应用实战:构建Plotly数据可视化代理
我们构建一个数据可视化的代理,通过代理我们只需提供很少的信息就能够让LLM生成我们定制化的图表。
AI:164- python获取图像边缘轮廓
边缘检测是图像处理中的重要步骤之一:它可以帮助我们找到图像中的边缘轮廓,从而进行对象检测、分割等应用。常用的边缘检测算法:包括Sobel算子、Canny边缘检测算法等。每种算法都有其特定的优点和适用场景,我们可以根据具体需求来选择合适的算法。OpenCV提供了丰富的图像处理功能:通过使用OpenCV
Blackbox AI : 全新的人工智能编码助手 您的高效AI开发全能助手
提起AI 智能编码助手,相信到了如今大家都不陌生。其对我们开发的代码时的效率有显著的提升,可以说是开发者的编程利器了,但大家脑海中最先想的是哪家产品呢?而今天给大家介绍的是 Blackbox AI 全新的人工智能编码助手。
【Python】搭建属于自己 AI 机器人
现在,AI 已经进入了人们生活的每个角落,而 AI 大模型更是大火,诸如文心一言、Chatgpt、Kimi、清谱智言等等。那为什么不能拥有一个自己的 AI 呢?于是我稍微研究了一下,本篇文章就将介绍如何搭建一个属于自己的 AI 机器人。
20240710 每日AI必读资讯
消息源:https://pymnts.com/artificial-intelligence-2/2024/report-microsoft-wont-follow-openai-in-blocking-chinas-access-to-ai-models/- OdysseyML 正在训练四个生成模
【人工智能】Transformers之Pipeline(概述):30w+大模型极简应用
本文为transformers之pipeline专栏的第0篇,后面会以每个task为一篇,共计讲述28+个tasks的用法,通过28个tasks的pipeline使用学习,可以掌握语音、计算机视觉、自然语言处理、多模态乃至强化学习等30w+个huggingface上的开源大模型。让你成为大模型领域的
springboot接入springai-openAi代理和智谱ai调用示例
背景配置具体代码总结现在想使用大模型真的门槛超低了,不管是直接使用还是api调用,怎么用这个问题解决起来还是很快的,不过我的问题大部分还是不知道用它做什么,我自己的能力不足以支撑我很好的使用它。



