豆包MarsCode:开启AI辅助编程的新时代
豆包MarsCode是一款集成到IDE中的AI编程助手,它通过深度学习技术,为开发者提供代码补全、代码审查、自动测试和学习编程技能等功能。豆包MarsCode作为AI编程助手,为开发者提供了强大的辅助功能,从代码补全到自动测试,极大地提升了开发效率和代码质量。
人工智能在C/C++中的应用
随着技术的飞速发展,人工智能(AI)已经成为我们日常生活中不可或缺的一部分。从智能手机的语音助手到自动驾驶汽车,AI的应用无处不在。在众多编程语言中,C和C++因其高性能和灵活性,成为实现复杂AI算法的理想选择。人工智能是计算机科学的一个分支,它试图理解智能的实质,并生产出一种新的能以人类智能相似方
AI:266-利用机器学习提升金融预测准确性与风险控制【技术与案例分析】
在现代金融市场中,机器学习技术已成为预测和风险管理的重要工具。金融市场预测涉及利用历史数据预测股票价格、市场趋势以及其他金融指标,而风险管理则侧重于识别和缓解潜在的金融风险。本文将探讨机器学习在这两个领域中的应用,包括具体的代码实例,以帮助理解其实际应用。
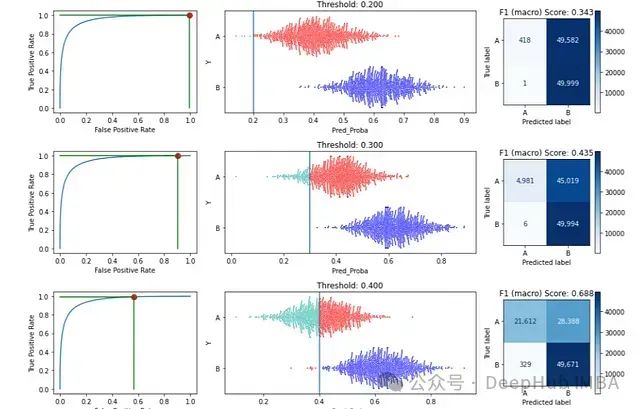
使用ClassificationThresholdTuner进行二元和多类分类问题阈值调整,提高模型性能增强结果可解释性
本文将深入探讨阈值调整的具体机制 — 特别是在多类分类问题中,这个过程可能会比较复杂。我们还将介绍一个名为 ClassificationThresholdTuner 的开源工具,这是笔者开发的一个自动化阈值调整和解释的工具。
使用 MongoDB 构建 AI:Patronus 如何自动进行大语言模型评估来增强对生成式 AI 的信心
Patronus通过与MongoDB Atlas等技术集成,提供托管评估服务,确保RAG系统能够持续提供可靠的信息,并为开发者提供了工具和指南来提高系统性能和稳定性。
【每天值得看】文章获得《每天值得看》人工智能板块推荐第三名!为自己点个赞!!!
尽管在学术文献中“注意力”有多种定义,但我们在这里采用以下定义:注意力机制指的是基于输入查询和元素键动态计算权重的元素加权平均。具体来说,这意味着什么?摘要:文本转音频(TTS),与上一篇音频转文本(STT)是对称技术,给定文本生成语音,实际使用上,更多与语音克隆技术相结合:先通过一段音频(few-
人工智能发展史
1982年,马尔(David Marr)发表代表作《视觉计算理论》提出计算机视觉(Computer Vision)的概念,并构建系统的视觉理论,对认知科学(CognitiveScience)也产生了很深远的影响。通过误差的梯度做反向传播,更新模型权重, 以下降学习的误差,拟合学习目标,实现'网络的万
数据结构详解---顺序表
数据结构线性表中的顺序表详细讲解
在亚马逊云科技上利用Agent和生成式AI写小说(下篇)
Amazon Bedrock Agent 是亚马逊云科技推出的一项生成式AI功能,它利用生成式AI(Generative AI)帮助开发者构建能够跨多个系统和数据源执行任务的智能应用程序。通过 Amazon Bedrock,开发者可以轻松地接入预训练的大模型,并通过 Agents 赋能应用程序,实现
opencv-python图像增强七:图像亮度对比度饱和度调整
在图像处理领域,对比度、亮度和饱和度是影响图像视觉效果的重要因素。合理调整这三个参数,可以使图像更具表现力,满足不同场景的需求。本文将带领大家使用OpenCV,这一强大的开源计算机视觉库,轻松实现图像对比度、亮度和饱和度的修改。本文将从基础知识入手,详细介绍如何使用OpenCV对图像进行操作,包括对
生成式AI时代,让Amazon Q 帮助我们编写代码~
总的来说,Amazon Q作为现代云计算时代的智能编程助手,凭借其强大的功能和便捷的用户体验,帮助企业和开发者更加高效地应对日益复杂的技术挑战。利用Amazon Q,企业能够在快速上云的过程中显著减少开发成本、提升代码质量,并推动业务创新。展望未来,Amazon Q将继续进化,推出更多功能支持,为用
基于YOLO的植物病害识别系统:从训练到部署全攻略
使用Kaggle上的植物叶片病害数据集,包含多种植物叶片的病害图像和标注。数据集下载链接:https://www.kaggle.com/datasetsYOLO (You Only Look Once) 是一种快速准确的目标检测模型。YOLOv8/v7/v6/v5 是不同版本的YOLO模型,性能和速
ai工具推荐系列:文生图,图生图工具liblibAi
介绍一款比较专业的文生图工具
生物研究新范式!AI语言模型在生物研究中的应用
尽管生物学从根本上依赖于物理实体(蛋白质、基因和细胞)的特性,但我们对该领域的理解是通过科学论文、教科书、网页等以自然语言记录的。因此,人们越来越有兴趣使用自然语言模型,让生物学研究人员可以轻松访问这些书面资源中包含的大量生物学信息。此外,自然语言模型可以通过来自其他模态(例如图像或基因序列)的数据
探秘The Pile:大规模、多领域的人工智能训练数据集
探秘The Pile:大规模、多领域的人工智能训练数据集 the-pile项目地址:https://gitcode.com/gh_mirrors/th/the-pile 是一个由EleutherAI社区构建的开源数据集,旨在为自然语言处理(NLP)模型提供丰富、多样化的训练素材。该项目的核心理念是提
智谱AI最新开源模型CHATGLM4-9B试用
具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓
Datawhale X 李宏毅苹果书 AI夏令营 Task1-机器学习初认识
作为一个技术小白,我的逻辑可能并不严密,专业知识并不丰富,但还是想通过这样的一种输出方式,谈谈自己的感受和理解,在写文章的同时帮助自己梳理思路,也为大家提供一点见解。机器要找一个函数 f,其输入是可能是种种跟预测 PM2.5 有关的指数,包括今天的 PM2.5 的数值、平均温度、平均的臭氧浓度等等,
torch.nn.Linear的维度变换过程详解(有图有公式有代码)
当初在学习nn.Linear时了解到的博客都是关于一维变换的,比如输入3通道,输出6通道;又比如得到(3,4,4)的特征图,需要进行拉平为(48,)的向量,然后通过nn.Linear(48,10)得到10个输出(分类任务很常见)。nn.Linear除了可以进行分类,主要的作用就是改变维度便于下一个卷
24华数杯ABC题初步思路+选题想法!!!!
请注意,这只是一个非常简化的示例,实际的解题过程需要更复杂的数据处理和模型建立。您需要根据具体的数据结构和问题要求来调整和完善代码。由于这是一个数学建模问题,实际的解决方案可能需要使用专业的数学建模软件和优化工具。请注意,这只是一个非常简化的示例,实际的解题过程需要更复杂的数据处理和模型建立。通过以
AI:246-YOLOv8改进 | 轻量级跨尺度特征融合模块CCFM的设计与应(超级涨点)(附yaml文件+添加教程)
在本文中,我们详细探讨了如何在YOLOv8中引入轻量级跨尺度特征融合模块(CCFM),旨在提升目标检测模型的性能。CCFM模块通过利用深度可分离卷积和自适应通道注意力机制,有效融合不同尺度的特征。CCConv:一个轻量级的深度可分离卷积单元,旨在减少计算复杂度。特征融合:通过卷积操作和自适应通道注意



