
大模型的发展让CGI有了飞速的发展。一个好的艺术家可以创造出与现实几乎无法区分的产品。而如何检测AI生成的图片变得越来越困难,大多数模型的准确率只有70%左右,直到最近,模型突然能够以超过90%的准确率及逆行分辨。我们看看能否使用简单的方法也达到类似的检测指标。

我们这里要介绍的很多过程是特征工程而不是分类。这个过程包括几个步骤,看起来很复杂,但实际上他们的核心很简单。
1、将图像大小调整为256 * 256。2、应用傅里叶变换将图像转换为其频率表示。3、训练嵌入模型对图像进行分类并保留嵌入。4、应用梯度增强方法,如XGBoost,根据嵌入将图像分类为CGI或非CGI。
我们用的数据集是从ArtStation和Unsplash获得的真实照片和CGI图像,训练集中有大约630张图像,测试集中有158张图像。使用像XGBoost和嵌入这样的模型,CGI分类是困难的,但并非不可能。为什么要应用傅里叶变换?空间域图像将包含有关艺术作品主题的内容信息,但我们对此不感兴趣。我们只对噪声模式、风格和细微的美学差异感兴趣,这些可能会出现在频域,而不是空间域。
傅里叶变换本身有点复杂但总的来说,它是一系列不同频率的不同波的求和来形成原始图像。傅里叶变换将揭示噪声模式和其他频率信息被图像遮挡。嵌入模型将决定CGI和真实照片之间的差异。
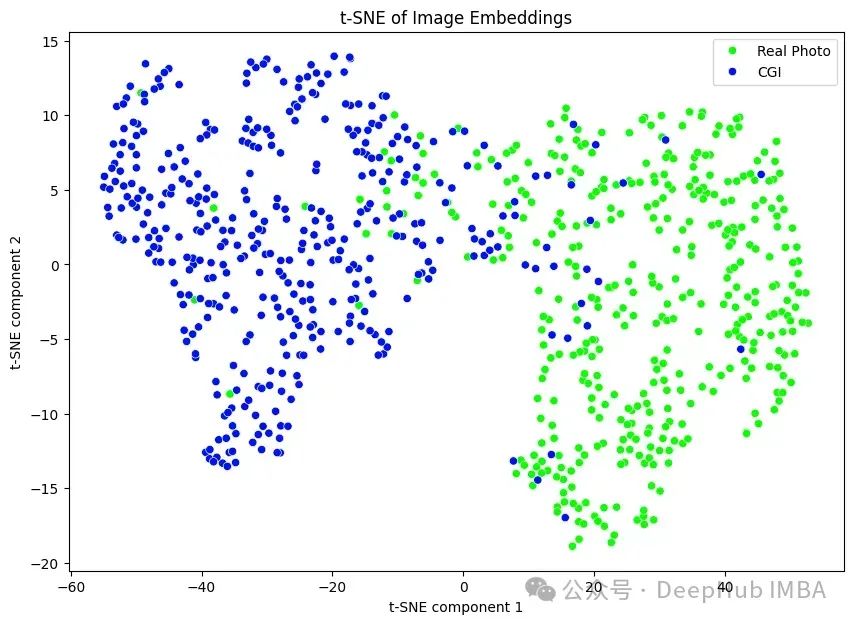
我们这首先通过应用FFT算法提取一系列特征,FFT是Numpy中傅里叶变换的一种变体,然后应用Scikit-learn中的PCA。
import numpy as np
from PIL import Image
from scipy.fftpack import fft2
from tensorflow.keras.models import load_model, Model
# Function to apply Fourier transform
def apply_fourier_transform(image):
image = np.array(image)
fft_image = fft2(image)
return np.abs(fft_image)
# Function to preprocess image
def preprocess_image(image_path):
image = Image.open(image_path).convert('L')
image = image.resize((256, 256))
image = apply_fourier_transform(image)
image = np.expand_dims(image, axis=-1) # Expand dimensions to match model input shape
image = np.expand_dims(image, axis=0) # Expand to add batch dimension
return image
# Function to load embedding model and calculate embeddings
def calculate_embeddings(image_path, model_path='embedding_model.keras'):
# Load the trained model
model = load_model(model_path)
# Remove the final classification layer to get embeddings
embedding_model = Model(inputs=model.input, outputs=model.output)
# Preprocess the image
preprocessed_image = preprocess_image(image_path)
# Calculate embeddings
embeddings = embedding_model.predict(preprocessed_image)
return embeddings
该嵌入模型产生128个长度的向量嵌入,可用于XGBoost模型。
xgb_clf = XGBClassifier(use_label_encoder=False, eval_metric='logloss', early_stopping_rounds=10)
xgb_clf.fit(X_train, y_train, eval_set=[(X_test, y_test)], verbose=False)
y_pred_xgb = xgb_clf.predict(X_test)
然后可以将模型保存为JSON文件,以便以后与嵌入模型一起重用。
xgb_clf.save_model("xgb_cgi_classifier.json")
我们可以测试模型的准确性,混淆矩阵告诉我们模型在不同输入下的表现。具体来说,比较了真实照片和CGI图像的准确性。
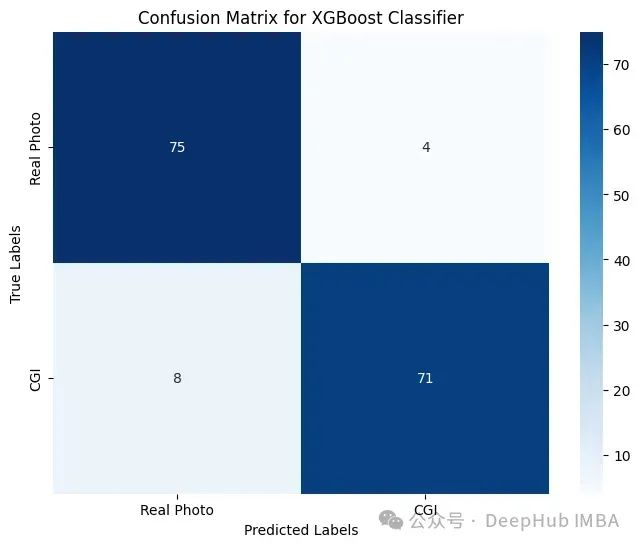
该模型的总体准确率为92.41%,F1得分为0.9221。F1分数是衡量模型的精度和召回率的指标。精确度是识别真实的CGI示例的频率,召回率是识别为CGI的示例与整个正面示例集的比例。
对于大多数图像,嵌入空间很容易区分CGI和真实照片。但是也有例外。其中一个例子是成龙的CGI图像,它预测真实照片的概率是96%。这不是一个完美的模型,即使像XGBoost这样好的检测模型也不能检测到所有的嵌入。
我个人认为,在模型无法区分的情况下,使用图像取证工具的人类将比机器学习模型更好地检测CGI,因为人类可以使用他们的先验知识逐个像素地评估图像,而模型只能依赖他们的训练数据。人类可能会注意到模型没有训练过的CGI图像和真实照片中的模式。其中包括眼睛颜色或头发的微妙变化,这些变化并不真实,但由于CGI模型不具备完整的世界知识,因此无法对其进行评估。CGI检测模型对世界的了解是不完整的,而人类对世界的了解要大得多。因此在某些情况下,人类分类器可能比CGI检测模型表现得更好。
https://avoid.overfit.cn/post/b559f9637b264a29a2237df9b924069f
作者:Noah Hradek
版权归原作者 deephub 所有, 如有侵权,请联系我们删除。