
变分自编码器(VAEs)是一种生成式人工智能,因其能够创建逼真的图像而备受关注,它们不仅可以应用在图像上,也可以创建时间序列数据。标准VAE可以被改编以捕捉时间序列数据的周期性和顺序模式,然后用于生成合成数据。本文将使用一维卷积层、策略性的步幅选择、灵活的时间维度和季节性依赖的先验来模拟温度数据。
我们使用亚利桑那州菲尼克斯市50年的ERA5小时温度数据训练了一个模型。为了生成有用的合成数据,它必须捕捉原始数据的几个特征:
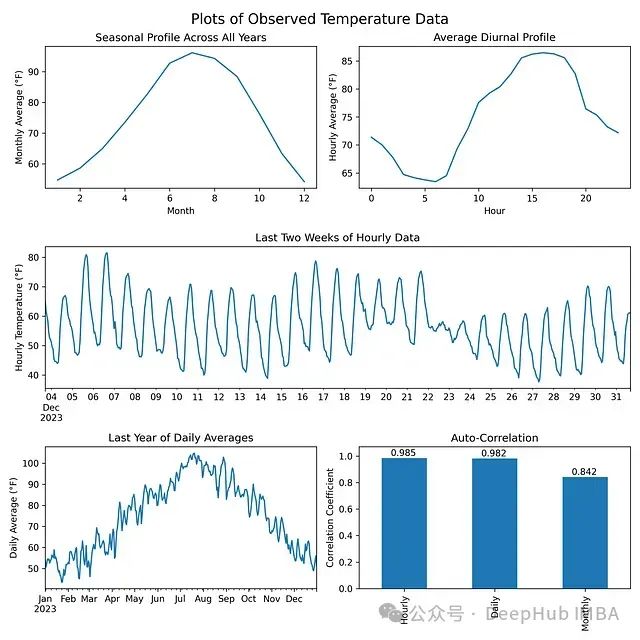
- 季节性概况 — 夏季应该比冬季更暖
- 昼夜概况 — 白天应该比夜晚更暖
- 自相关性 — 数据应该平滑,连续几天的温度应该相似
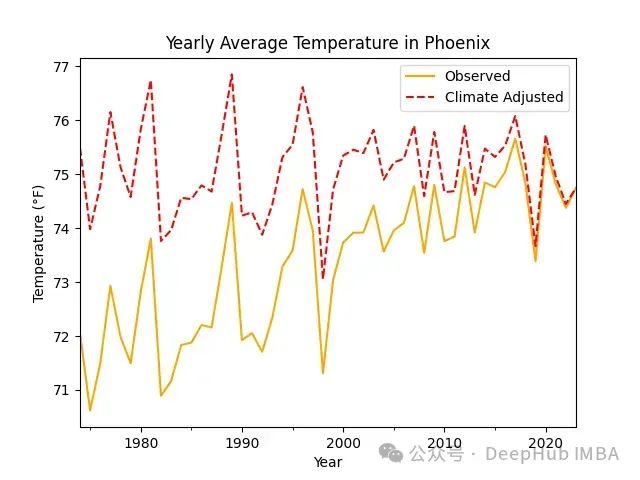
如果训练数据是平稳的,没有长期趋势,模型表现最佳。但是由于气候变化,温度呈现上升趋势,每十年约上升0.7°F — 这个值来自观测数据,与发表的显示近期各地区变暖趋势的地图一致。为了考虑到温度上升,需要对原始观测数据应用每十年-0.7°F的线性变换,消除上升趋势。
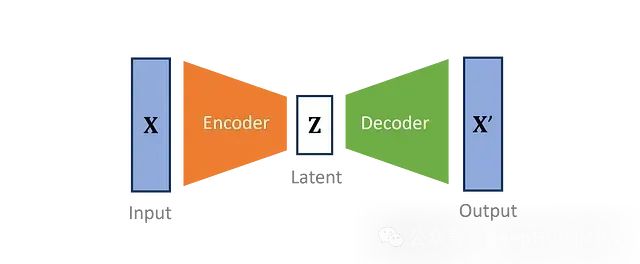
什么是VAE?
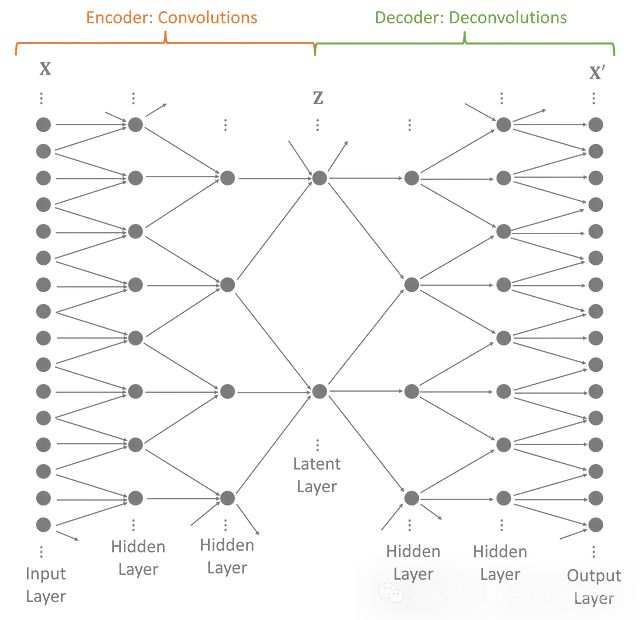
变分自编码器将输入数据的维度降低到一个更小的子空间。VAE定义了一个编码器,将观察到的输入转换成一种压缩形式,称为潜在变量。然后一个独特的镜像解码器尝试重建原始数据。编码器和解码器被共同优化,创建一个尽可能少损失信息的模型。
训练中使用的完整损失函数包括:
- 重建损失: 测量经过往返转换的数据与原始输入的匹配程度
- 正则化项: 测量潜在变量的编码分布与先验分布的匹配程度
这两个损失项是通过变分推断得出的,目标是最大化观测数据的证据下界(ELBO)。
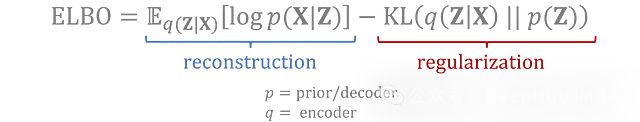
VAE对训练数据进行特征提取,使得最重要的特征(由潜在变量表示)遵循定义的先验分布。通过对潜在分布进行采样,然后将其解码为原始输入的形式,可以生成新的数据。
一维卷积层
为了模拟温度数据,我们编码器设计成一个具有一维卷积层的神经网络。每个卷积层应用一个核 。由于在整个输入中使用相同的核,卷积层被认为是平移不变的,非常适合具有重复序列模式的时间序列。
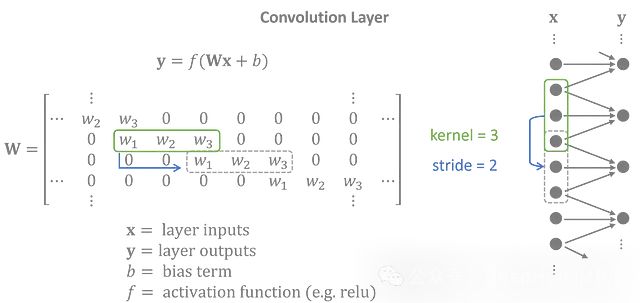
左: 作为矩阵运算的卷积层 | 右: 图形表示
通常,输入和输出有几个特征变量。为简单起见,矩阵运算显示了仅有一个特征的输入和输出之间的卷积。
解码器使用转置的一维卷积层(也称为反卷积层)执行与编码器相反的任务。潜在特征被投影到重叠的序列中,以创建一个与输入紧密匹配的输出时间序列。
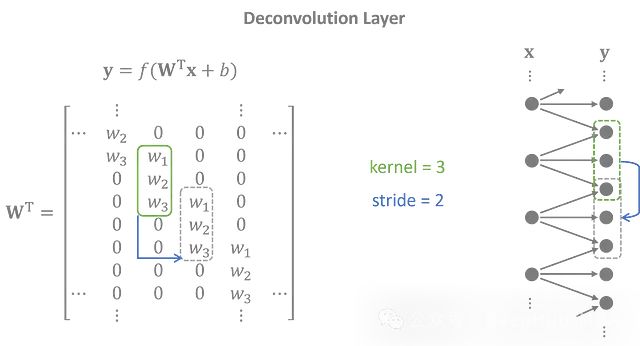
反卷积层的权重矩阵是卷积矩阵的转置。
完整的模型将几个卷积层和反卷积层堆叠在一起。每个中间的隐藏层扩展潜在变量的范围,使模型能够捕捉数据中的长期效应。
步幅
步幅 — 移动之间的跳跃 — 决定了下一层的大小。卷积层使用步幅来缩小输入,而反卷积层使用步幅将潜在变量扩展回输入大小。它们还有一个次要目的 — 捕捉时间序列中的周期性趋势。
你可以简单的认为选择卷积层的步幅是可以代表数据中的周期性模式。
将多个层堆叠在一起会产生一个由嵌套的子卷积组成的更大的有效周期。
考虑一个卷积网络,它将每小时的时间序列数据提炼成每天四个变量,代表早晨、下午、傍晚和夜晚。一个步幅为4的层将有唯一分配给一天中每个时间的权重,在隐藏层中捕捉昼夜概况。在训练过程中,编码器和解码器学习复制数据中发现的日循环的权重。
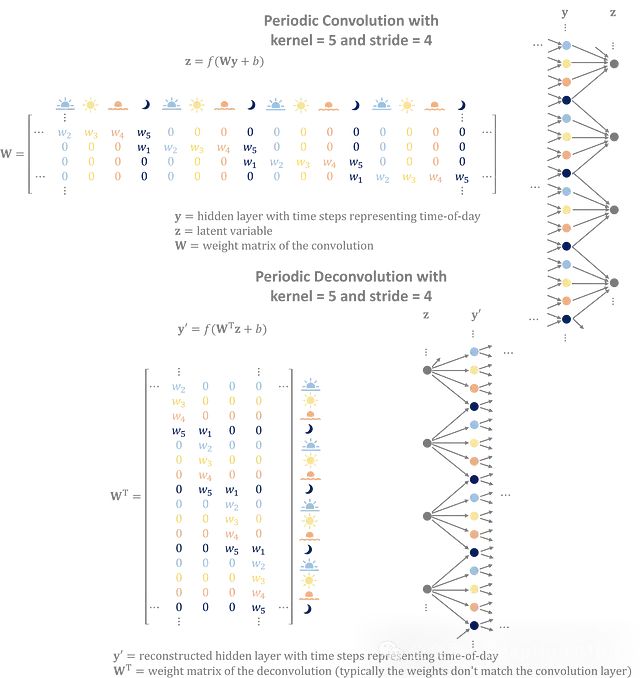
卷积利用输入的周期性来构建更好的潜在特征。反卷积将潜在特征转换为重叠的、重复的序列,以生成具有周期性模式的数据。
时间维度
生成图像的VAE通常有数千张预处理成固定宽度和高度的图像。生成的图像将与训练数据的宽度和高度相匹配。
对于这个温度的数据集,我们有一个50年的时间序列。我么可以为每96小时周期分配一个潜在变量。所以想要生成长于4天的时间序列,理想情况下,输出应该是平滑的,而不是在模拟中有离散的96小时块。
所以我门的潜在变量也包括一个可以变化的时间维度。在模型中,潜在空间中的每个时间步对应输入中的96小时。
![]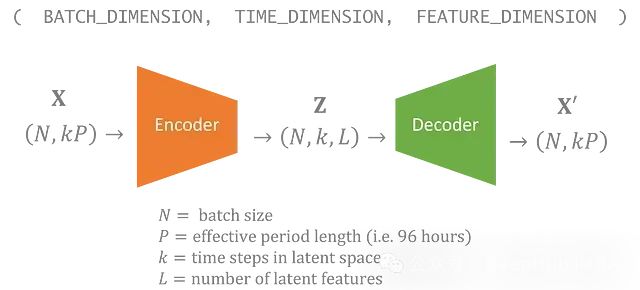
生成新数据就像从先验中采样潜在变量一样简单,可以选择想要包含在时间维度中的步数。
具有未受约束时间维度的VAE可以生成任意长度的数据。
季节性依赖的先验
在大多数VAE中,潜在变量的每个分量被假定遵循标准正态分布。这个分布,有时被称为先验,被采样然后解码并且生成新的数据。在这种情况下,我们可以选择一个稍微复杂一点的先验,它依赖于一年中的时间。
从季节性先验采样的潜在变量将生成具有随季节变化特征的数据。
在这个先验下,生成的一月数据将与七月数据看起来非常不同,而同一个月生成的数据将共享许多相同的特征。
将一年中的时间表示为一个角度,θ,其中0°是1月1日,180°是7月初,360°又回到1月。先验是一个正态分布,其均值和对数方差是θ的三次三角多项式,其中多项式的系数是在训练过程中与编码器和解码器一起学习的参数。
先验分布参数是θ的周期函数,而且良好行为的周期函数可以通过足够高阶的三角多项式以任何精度级别近似。
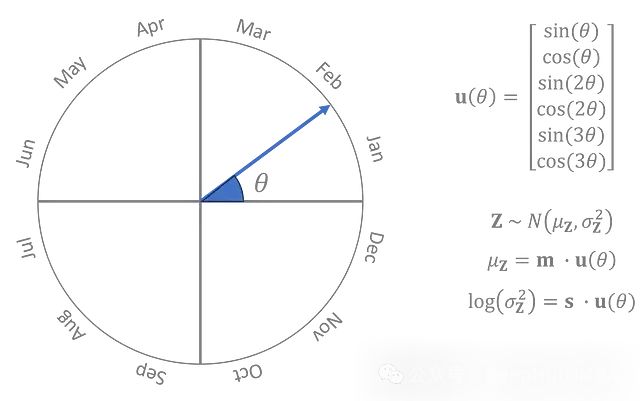
左: θ的可视化 | 右: Z的先验分布,用参数m和s表示
季节性数据仅用于先验,不影响编码器或解码器。完整的概率依赖关系在这里以图形方式显示。
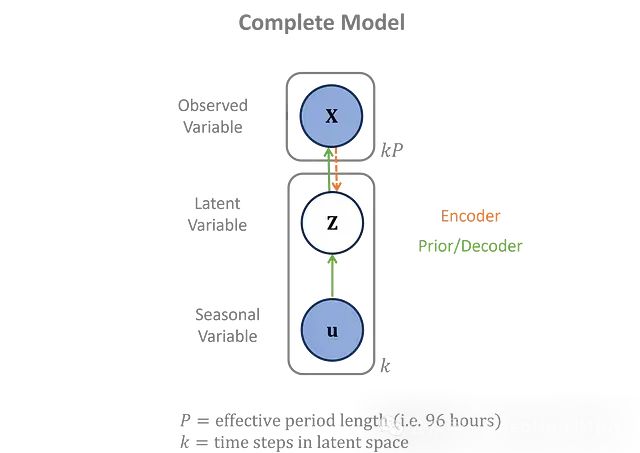
上图就是包括先验的概率图模型
代码实现
为了简化训练步骤,我们使用Tensorflow开发这个模型
fromtensorflow.kerasimportlayers, models
编码器
输入被定义为具有灵活的时间维度。在Keras中,你可以使用
None
指定一个未受约束的维度。
使用
'same'
填充将在输入层附加零,使得输出大小与输入大小除以步幅相匹配。
inputs=layers.Input(shape=(None,)) # (N, 96*k)
x=layers.Reshape((-1, 1))(inputs) # (N, 96*k, 1)
# Conv1D parameters: filters, kernel_size, strides, padding
x=layers.Conv1D(40, 5, 3, 'same', activation='relu')(x) # (N, 32*k, 40)
x=layers.Conv1D(40, 3, 2, 'same', activation='relu')(x) # (N, 16*k, 40)
x=layers.Conv1D(40, 3, 2, 'same', activation='relu')(x) # (N, 8*k, 40)
x=layers.Conv1D(40, 3, 2, 'same', activation='relu')(x) # (N, 4*k, 40)
x=layers.Conv1D(40, 3, 2, 'same', activation='relu')(x) # (N, 2*k, 40)
x=layers.Conv1D(20, 3, 2, 'same')(x) # (N, k, 20)
z_mean=x[: ,:, :10] # (N, k, 10)
z_log_var=x[:, :, 10:] # (N, k, 10)
z=Sampling()([z_mean, z_log_var]) # custom layer sampling from gaussian
encoder=models.Model(inputs, [z_mean, z_log_var, z], name='encoder')
Sampling()
是一个自定义层,从给定均值和对数方差的正态分布中采样数据。
解码器
反卷积是通过
Conv1DTranspose
执行的。
# input shape: (batch_size, time_length/96, latent_features)
inputs=layers.Input(shape=(None, 10)) # (N, k, 10)
# Conv1DTranspose parameters: filters, kernel_size, strides, padding
x=layers.Conv1DTranspose(40, 3, 2, 'same', activation='relu')(inputs) # (N, 2*k, 40)
x=layers.Conv1DTranspose(40, 3, 2, 'same', activation='relu')(x) # (N, 4*k, 40)
x=layers.Conv1DTranspose(40, 3, 2, 'same', activation='relu')(x) # (N, 8*k, 40)
x=layers.Conv1DTranspose(40, 3, 2, 'same', activation='relu')(x) # (N, 16*k, 40)
x=layers.Conv1DTranspose(40, 3, 2, 'same', activation='relu')(x) # (N, 32*k, 40)
x=layers.Conv1DTranspose(1, 5, 3, 'same')(x) # (N, 96*k, 1)
outputs=layers.Reshape((-1,))(x) # (N, 96*k)
decoder=models.Model(inputs, outputs, name='decoder')
先验
先验期望输入已经是[sin(θ), cos(θ), sin(2 θ), cos(2 θ), sin(3 θ), cos(3 θ)]的形式。
Dense
层没有偏置项,这是为了防止先验分布偏离零太远或整体方差过高或过低。
# seasonal inputs shape: (N, k, 6)
inputs=layers.Input(shape=(None, 2*3))
x=layers.Dense(20, use_bias=False)(inputs) # (N, k, 20)
z_mean=x[:, :, :10] # (N, k, 10)
z_log_var=x[:, :, 10:] # (N, k, 10)
z=Sampling()([z_mean, z_log_var]) # (N, k, 10)
prior=models.Model(inputs, [z_mean, z_log_var, z], name='seasonal_prior')
完整模型
损失函数包含一个重建项和一个潜在正则化项。
函数
log_lik_normal_sum
是一个自定义函数,用于计算给定重建输出的观测数据的正态对数似然。计算对数似然需要解码输出周围的噪声分布,这被假定为正态分布,其对数方差由
self.noise_log_var
给出,在训练过程中学习。
对于正则化项,
kl_divergence_sum
计算两个高斯分布之间的Kullback-Leibler散度 — 在这种情况下,是潜在编码分布和先验分布。
classVAE(models.Model):
def__init__(self, encoder, decoder, prior, **kwargs):
super(VAE, self).__init__(**kwargs)
self.encoder=encoder
self.decoder=decoder
self.prior=prior
self.noise_log_var=self.add_weight(name='var', shape=(1,), initializer='zeros', trainable=True)
@tf.function
defvae_loss(self, data):
values, seasonal=data
z_mean, z_log_var, z=self.encoder(values)
reconstructed=self.decoder(z)
reconstruction_loss=-log_lik_normal_sum(values, reconstructed, self.noise_log_var)/INPUT_SIZE
seasonal_z_mean, seasonal_z_log_var, _=self.prior(seasonal)
kl_loss_z=kl_divergence_sum(z_mean, z_log_var, seasonal_z_mean, seasonal_z_log_var)/INPUT_SIZE
returnreconstruction_loss, kl_loss_z
deftrain_step(self, data):
withtf.GradientTape() astape:
reconstruction_loss, kl_loss_z=self.vae_loss(data)
total_loss=reconstruction_loss+kl_loss_z
gradients=tape.gradient(total_loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
return {'loss': total_loss}
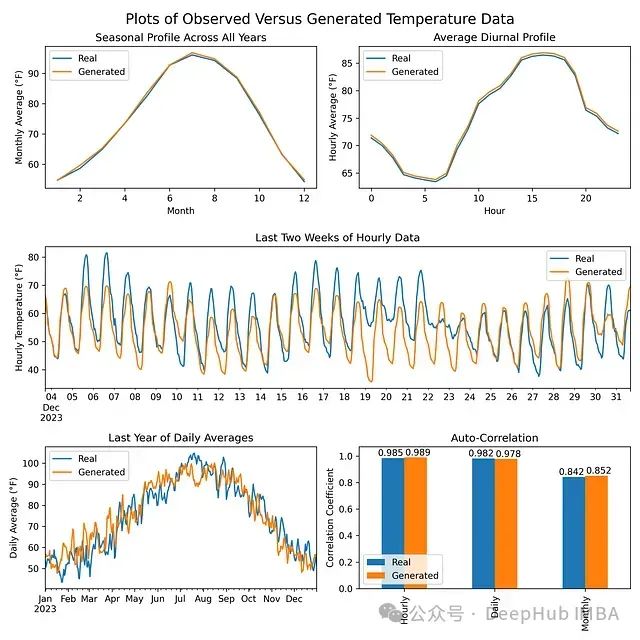
结果
在训练模型后,生成的数据与原始温度数据的季节性/昼夜概况和自相关性相匹配。
总结
构建生成式时间序列建模技术是一个关键领域,其应用远不止于模拟数据。我们这个方法可以适用于数据插补、异常检测和预测等应用。
通过使用一维卷积层、策略性步幅、灵活的时间输入和季节性先验,可以构建一个能够复制时间序列中复杂模式的VAE。让我们合作完善时间序列建模的最佳实践。
本文代码如下:
https://github.com/davidthemathman/vae_for_time_series
作者:David Kyle