【人工智能】企业如何使用 AI与人工智能的定义、研究价值、发展阶段的深刻讨论
企业如何使用 AI与人工智能的定义、研究价值、发展阶段的深刻讨论定义详解研究价值发展阶段企业如何使用 AI?科学介绍
ZED使用指南(一)
一、连接相机将相机插入USB3.0端口。二、下载ZED SDK(Jetson)1、NVIDIA Jetson安装操作系统Jetpack2、下载和系统匹配的ZED SDK进入下载的文件夹:cd path/to/download/folder使用chmod +x命令增加安装程序的执行权限,注意将名称替换
Opencv cv2.putText 函数详解
【代码】Opencv cv2.putText 函数详解。
论文中常用的注意力模块合集(上)
在深度卷积神经网络中,通过构建一系列的卷积层、非线性层和下采样层使得网络能够从全局感受野上提取图像特征来描述图像,但归根结底只是建模了图像的空间特征信息而没有建模通道之间的特征信息,整个特征图的各区域均被平等对待。在一些复杂度较高的背景中,容易造成模型的性能不佳,因此可以引入注意力机制,而注意力机制
论文阅读:multimodal remote sensing survey 遥感多模态综述
从多模态表示,对齐,融合,跨模态转换,协同学习等5个大方面来介绍在遥感领域的分类和相关工作

Recognize Anything:一个强大的图像标记模型
Recognize Anything是一种新的图像标记基础模型,与传统模型不同,它不依赖于手动注释进行训练;相反,它利用大规模的图像-文本对
深入浅出CenterFusion
结合论文和代码理解CenterFusion
用C++部署yolov5模型
要在C语言中部署YoloV5模型,可以使用以下步骤:安装C语言的深度学习库,例如Darknet或者ncnn。下载训练好的YoloV5模型权重文件(.pt文件)和模型配置文件(.yaml文件)。将下载的权重文件和配置文件移动到C语言深度学习库中指定的目录下。在C语言中编写代码,使用深度学习库加载Yol
医学nii图像 预处理——图像裁剪 重采样 灰度区域 归一化 修改图像尺寸
当处理的图像为肺部图像时,也称为截取肺窗,即肺所在灰度范围,常见肺窗[窗宽:900,窗位:-550],宽肺窗[窗宽:1600,窗位:-600]由算法(有些算法要求输入图片尺寸统一,有些算法则需要保证原图)或电脑性能(显存小,只能缩小图片咯~)决定。鄙人主要研究方向为医学图像配准,在使用CT数据集之前
【OpenCV教程】OpenCV中的数据类型
【OpenCV教程】OpenCV中的数据类型
【SeAFusion:语义感知:分割+融合】
仅供自己参考
VS2019配置opencv4.6.0手把手一步一步实现
配置环境真是让人痛苦不堪,踩了无数个坑,网上的文章五花八门,完全不知道参考哪个,直接劝退。为了能顺利配置,此处进行记录,以后可以回过头来看,也分享给大家。
NWD(2022)
检测微小物体是一个非常具有挑战性的问题,因为微小物体仅包含几个像素大小。我们证明,由于缺乏外观信息,最先进的检测器无法在微小物体上产生令人满意的结果**。我们的主要观察结果是,基于联合交集 (IoU) 的指标(例如 IoU 本身及其扩展)对微小物体的位置偏差非常敏感,并且在用于基于锚点的检测器中时会
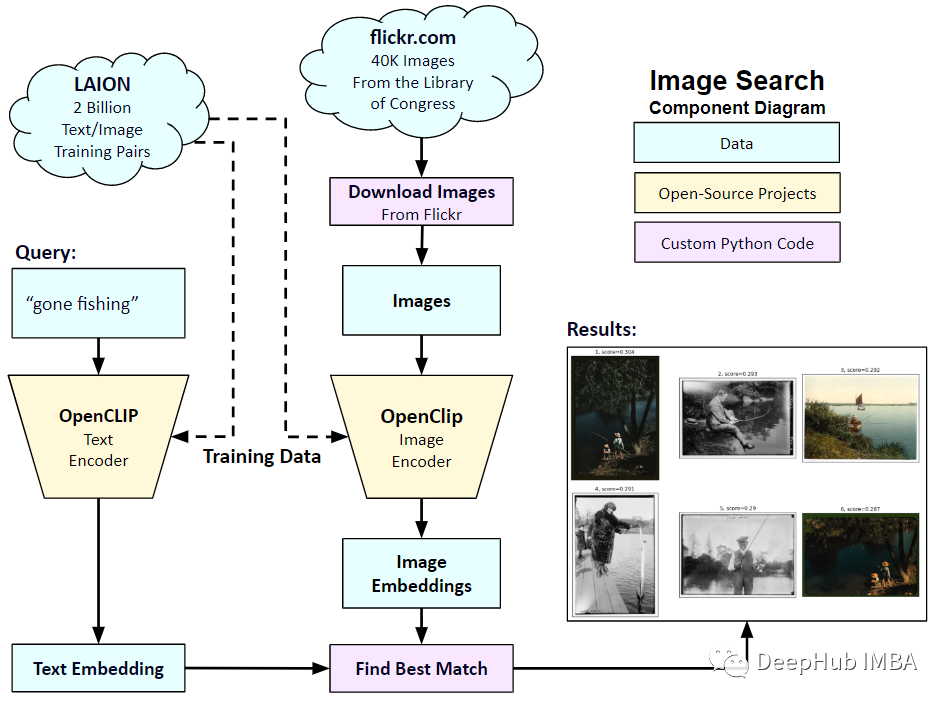
在自定义数据集上实现OpenAI CLIP
在本文中,我们将使用PyTorch中从头开始实现CLIP模型,以便我们对CLIP有一个更好的理解
ISP-长短曝光融合生成HDR图像
根据Debevec等人提出的相机响应曲线(Camera Response Curve,CRV),采集图像数据计算长曝光与像素值的关系,短曝光与像素值的关系,再利用权重函数,将长曝光、短曝光对应的低动态范围图像数据合成,得到高动态范围图像。第二,像素点亮度值与曝光时间成线性关系。2、**长短曝光融合:
Autolabelimg自动标注工具
在做机器视觉有监督方面,通常会面对很多数据集,然后去进行标注,而有些时候我们面对庞大数量数据集的情况下也会感到十分头疼,这个时候Autolabelimg这个自动标注神器就应运而生了。让我们可以实现批量处理图片和标注文件。
【计算机视觉】Visual grounding系列
【计算机视觉】Visual grounding系列
Point-NeRF总结记录
Point-NeRF阅读总结记录 PPT形式
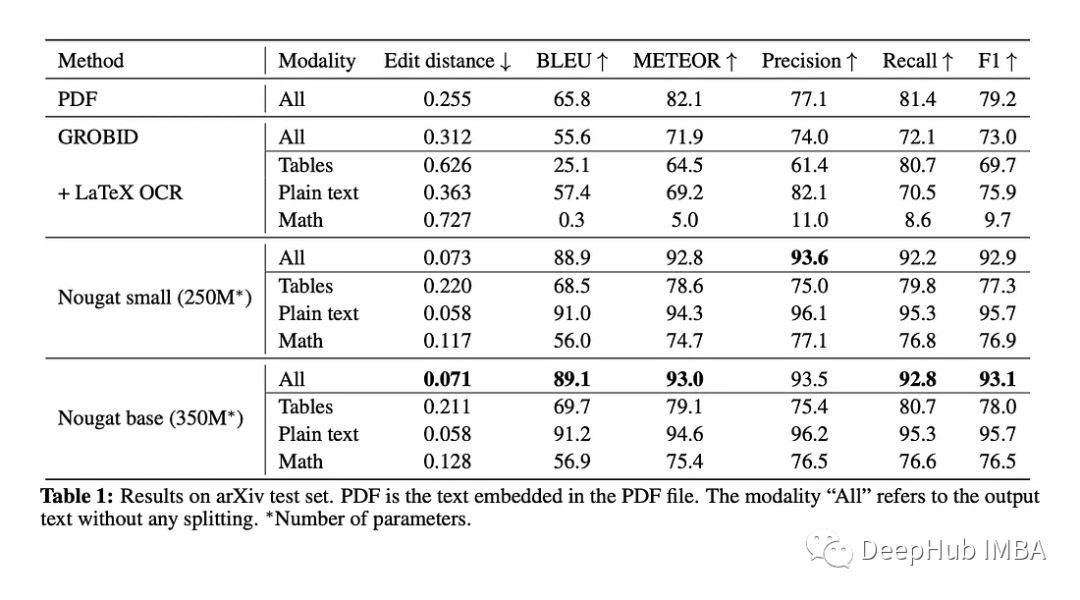
Nougat:一种用于科学文档OCR的Transformer 模型
Nougat是一种VIT模型。它的目标是将这些文件转换为标记语言,以便更容易访问和机器可读。
PointPillars 工程复现
PointPillars 工程复现, 学习并复现PointPillars,解决部署时遇到的各类问题。



