
Image fusion in the loop ofhigh-level vision tasks: A semantic-aware real-time infrared and visible image fusion network
(高级视觉任务循环中的图像融合:一种语义感知的实时红外与可见光图像融合网络)
红外与可见光图像融合的目的是合成一幅融合图像,该图像不仅包含显著的目标和丰富的纹理细节,而且有利于高级视觉任务。然而,现有的融合算法片面地关注融合图像的视觉质量和统计指标,而忽略了高层次视觉任务的要求。为了解决这些问题,本文在图像融合和高级视觉任务之间架起了差距,提出了一种语义感知的实时图像融合网络(SeAFusion)。一方面,将图像融合模块与语义分割模块级联,利用语义损失引导高层语义信息回流到图像融合模块,有效提高融合图像的高层视觉任务性能。另一方面,我们设计了梯度残差密集块(GRDB)来增强融合网络对细粒度空间细节的描述能力。广泛的对比和泛化实验证明了我们的SeAFfusion在保持像素强度分布和保留纹理细节方面优于最先进的替代方案。更重要的是,通过比较不同融合算法在任务驱动评估中的性能,揭示了该框架在高层次视觉任务处理中的天然优势。
介绍
由于理论和技术上的局限性,单一模态传感器拍摄的图像无法有效、全面地描述成像场景。红外传感器捕捉物体发出的热辐射,可以突出突出目标,但红外图像忽略了纹理,容易受到噪声的影响。相反,可见光传感器捕获反射光信息。可见光图像通常包含丰富的纹理和结构信息,但对光照、遮挡等环境敏感。这种互补作用促使我们将红外图像和可见光图像进行融合,生成既能突出目标又能显示丰富细节信息的理想图像。因此,红外和可见光图像融合已经被广泛地用作高级视觉任务的预处理模块,目标检测、跟踪、行人再识别和语义分割。图1中的示例直观地示出了融合图像对分割任务的贡献。
该分割网络可以从可见光图像中分割出汽车、自行车和多个人,但忽略了隐藏在黑暗中的行人。虽然红外图像有助于分割网络准确地分割汽车和所有行人,但它忽略了自行车。融合图像利用红外图像和可见光图像的互补信息,提高了自行车、汽车和行人的分割精度。
由于红外与可见光图像融合的实用性,引起了学术界的广泛关注。在过去的几十年中,已经提出了许多图像融合技术,包括传统方法和最近的基于深度学习的方法。传统的方法通常分为五类,即,基于多尺度变换(MST)的方法、基于稀疏表示(SR)的方法、基于子空间的方法、基于优化的方法和混合方法。在基于深度学习的方法中,基于自动编码器(AE)的框架、基于卷积神经网络(CNN)的框架和基于生成对抗网络(GAN)的框架是占主导地位的框架。
尽管近年来基于深度学习的图像融合算法能够产生令人满意的融合图像,但图像融合领域仍存在一些亟待解决的问题。一方面,现有的融合算法倾向于追求更好的视觉质量和更高的评价指标,而很少系统地考虑融合后的图像是否能满足高层次视觉任务的要求。一些研究表明,仅考虑视觉质量和定量指标对高级视觉任务没有帮助。虽然一些工作引入感知损失在特征层面对融合图像和源图像进行约束,但感知损失并不能有效地增强融合图像中的语义信息,如图1所示。此外,其他研究人员通过分割掩模来指导图像融合过程,但掩模仅分割一些显著目标,这对于增强语义信息是有限的。另一方面,现有的评价方式主要是直观比较和定量评价。视觉比较侧重于融合图像的对比度和纹理细节,而定量评估依赖于一些统计指标来评估融合性能。然而,无论是视觉比较还是定量评价都不能反映融合图像对高级视觉任务的促进作用。此外,现有的网络结构不能有效地提取细粒度的细节特征。最后但并非最不重要的是,许多现有的融合算法忽略了实时图像融合的要求,同时努力提高视觉质量和评价指标。
在本研究中,我们提出一个语意感知的融合网路,称为SeAFusion,以达成实时的红外与可见光影像融合。我们的方法的关键是同时获得图像融合和高级视觉任务的优越性能。具体地说,我们引入了一个分割网络来预测融合图像的分割结果,并利用它来构造语义损失。然后,利用语义损失通过反向传播来指导融合网络的训练,迫使融合图像包含更多的语义信息。此外,为了满足高层次视觉任务的实时性要求,我们开发了一种基于梯度残差稠密块(Gradient Residual Dense Block,GRDB)的轻量级网络。GRDB利用主密集流实现特征重用,利用残差梯度流提高对细粒度细节的描述能力。
贡献
1)设计了一种新的语义感知的红外与可见光图像融合框架,有效地实现了图像融合和高级视觉任务的上级性能。
2)设计了梯度残差密集块,提高了网络对细粒度细节的描述能力,实现了特征重用。
3)SeAFusion是一种轻量级的实时图像融合模型。这使得它可以作为高级视觉任务的预处理模块进行部署。
4)提出了一种任务驱动的评价方法,从高级视觉任务的角度评价图像融合的性能。
相关工作
Image fusion algorithms
Traditional image fusion methods
由于特征重构通常是特征提取的逆过程,传统图像融合算法的关键在于两个关键要素,即:特征提取和融合。多尺度分解是特征提取中最常用的变换方法。在过去的几十年中,许多多尺度变换,如拉普拉斯金字塔(LP)、离散小波、剪切波、非下采样轮廓波变换和潜在低秩表示已经成功地嵌入到基于多尺度变换的图像融合框架中。此外,稀疏表示被用作特征提取技术,其使用过完备字典中的稀疏基来表示源图像。此外,基于子空间的方法也引起了广泛的关注,它将高维图像投影到低维子空间中,以捕捉源图像的内在结构。独立分量分析、主分量分析和非负矩阵分解是基于子空间的融合框架中的代表性方法。
除上述方法外,基于优化的方法为图像融合领域提供了新的视角和前景。特别是Ma等人将红外和可见光图像融合定义为整体强度保持和纹理结构保持,这为基于CNN的方法和基于GAN的方法奠定了坚实的基础。此外,一些研究人员结合了不同框架的优点,提出了混合模型,以追求更好的图像融合性能。特别地,Liu等人通过结合多尺度变换(MST)和稀疏表示(SR)开发了通用图像融合框架,以同时克服基于MST和基于SR的融合方法的固有缺陷。
值得注意的是,日益复杂的变换或表示无法响应实时图像融合的需求。此外,手工活动水平度量和融合规则活动水平度量不能集成语义信息,这将限制融合结果对高级视觉任务的贡献。
AE-based image fusion methods
凭借神经网络上级的特征学习能力,深度学习已成为众多视觉任务的新宠。图像融合社区也积极探索基于深度学习的解决方案,并开发了许多有前途的方案。基于自动编码器(AE)的框架是训练自动编码器实现特征提取和重构的一个重要分支。Li等人提出了一种简单的融合架构,其包括三个组件:编码器层、融合层和解码器层。编码器层包含卷积层和高层次特征的密块,其中密块在编码过程中被利用来获得更多有用的特征。融合层利用逐元素加法策略或l1范数策略融合高层特征,特征重构网络包含4层卷积,用于重构融合图像。此外,他们还引入了多尺度编解码器架构和嵌套连接,以提取更全面的特征。然而,上述方法采用人工规则融合深度特征,严重制约了融合性能。为了解决人工设计融合规则的局限性,Xu等人提出了一种基于分类显著性的规则,用于基于AE的图像融合框架。新的融合规则采用分类器来度量特征图中每个像素的显著性,并根据每个像素的贡献来计算融合权重。
CNN-based image fusion methods
基于神经网络的融合框架要么在精细的损失函数指导下实现隐式特征提取、聚合和图像重建,要么采用卷积神经网络(CNN)作为整体融合框架的一部分来实现活动水平测量和特征集成。LP-CNN是将CNN应用于图像融合领域的先驱,它将LP与分类型CNN相结合,实现医学图像融合。此外,Zhang等人通过通用网络结构开发了通用图像融合框架,即:特征提取层、融合层和图像重建层。值得注意的是,它们的融合层嵌入在训练过程中。因此,IFCNN可以减轻由人工设计的融合规则(逐元素最大值、逐元素最小值或逐元素平均值)强加的限制。
此外,研究人员还探索了一种替代解决方案,即,基于端到端神经网络的图像融合框架,避免了手工制定规则的缺点。基于神经网络的方法继承了传统优化方法的核心概念,其将图像融合的目标函数定义为整体强度保真度和纹理结构保留。Zhang等人将统一图像融合建模为梯度和强度的比例保持,并针对不同的图像融合任务设计了通用的损失函数。基于梯度和强度路径,他们还设计了挤压和分解网络来提高融合图像的保真度。此外,引入自适应决策块,根据源图像的纹理丰富度为梯度损失项分配权值。考虑到不同图像融合任务之间的相互影响,Xu等人为多融合任务训练了一个统一模型。为了增强融合图像中的语义信息,Ma等人利用显著掩模来构造红外和可见光图像融合所需的信息。虽然提出的网络可以检测显著目标,但简单的显著目标掩码仅增强了显著目标区域的语义信息。此外,对于图像融合任务,难以提供地面真实值来构造损失函数,这意味着基于神经网络的融合网络不能充分发挥其潜在性能。
GAN-based image fusion methods
由于对抗损失从概率分布的角度构建网络,因此生成式对抗网络对于无监督任务是理想的,例如,图像到图像转换和图像融合。Ma等人创造性地将GAN引入图像融合社区,其利用鉴别器来迫使生成器合成具有丰富纹理的融合图像。为了提高热目标的细节信息质量,锐化热目标的边缘,又引入了细节损失和边缘增强损失。然而,单个鉴频器可能导致模式塌陷,即,融合图像偏向可见光或红外图像。因此,Ma等人进一步提出了双鉴别器条件生成对抗网络,以提高基于GAN框架的鲁棒性,保持红外和可见光图像之间的平衡。随后,Li等人将多尺度注意机制整合到基于GAN的融合框架中,促使生成器和鉴别器更多地关注典型区域。此外,Ma等人将图像融合转化为多分布同时估计问题,从分类器的角度实现了红外和可见光图像的平衡。鲁棒的图像融合算法应在充分融合源图像互补信息的同时增强融合图像的语义信息。一些基于深度学习的算法试图通过引入感知损失或显著目标遮罩来增强融合图像中的语义信息。但感知损失对语义信息增强的益处有限。此外,显著目标掩码仅加强显著目标区域中的语义信息。为此,研究一种语义感知的图像融合算法势在必行。
Task-driven low-level vision algorithms
事实上,一些实用的解决方案,结合低层次的算法和高层次的视觉任务的要求,已经被提出。Li等人设计了一种轻量级去雾网络,称为AOD-Net,它可以很容易地嵌入到其他深度模型中,例如,Faster RCNN,用于改善模糊图像上的高级视觉任务。AODNet是第一个探索去雾算法与高级视觉任务性能之间相关性的工作。随后,Haris等人探索了图像超分辨率如何有助于低分辨率图像中的物体检测。他们开发了一个新的超分辨率框架,其中超分辨率子网络明确地将检测损失纳入其训练目标。而且,Liu等人提出了一种任务驱动的图像去噪方案,该方案级联了用于图像去噪和各种高级视觉任务的两个模块,并使用一个联合损失用于仅更新去噪模式的参数。他们的解决方案可以克服高级视觉任务的性能下降,并在高级视觉信息的指导下生成更具视觉吸引力的结果。最近,考虑到自动驾驶的实际需求,Guo等人设计了一种新颖的去训练框架,该框架包含语义细化残差网络和两阶段分割感知联合训练策略。
在本文中,我们设计了一个语义感知的实时红外和可见光图像融合框架,以增强融合图像中的语义信息。更具体地说,我们首先引入语义损失,以整合更多的语义信息到融合图像。然后,我们量身定制一个联合的低水平和高水平适应性训练策略,以保持低水平和高水平视觉任务的平衡。最后,我们的融合模型可以生成更具视觉吸引力的融合图像,同时在语义损失的指导下实现高级视觉任务的优异性能。
方法
Problem formulation
给定一对配准后的红外图像𝐼𝑖𝑟∈ R𝐻×𝑊×1 和可见光图像𝐼𝑣𝑖∈ R𝐻×𝑊×3,通过特征提取、融合和重构,在一个定制的损失函数的指导下实现图像融合。因此,融合图像𝐼𝑓∈ R𝐻×𝑊×3的质量在很大程度上取决于损失函数。为了提高融合性能,设计了一种由内容损失和语义损失组成的联合损失来约束融合网络。我们的语义感知红外和可见光图像融合算法的总体框架如图2所示。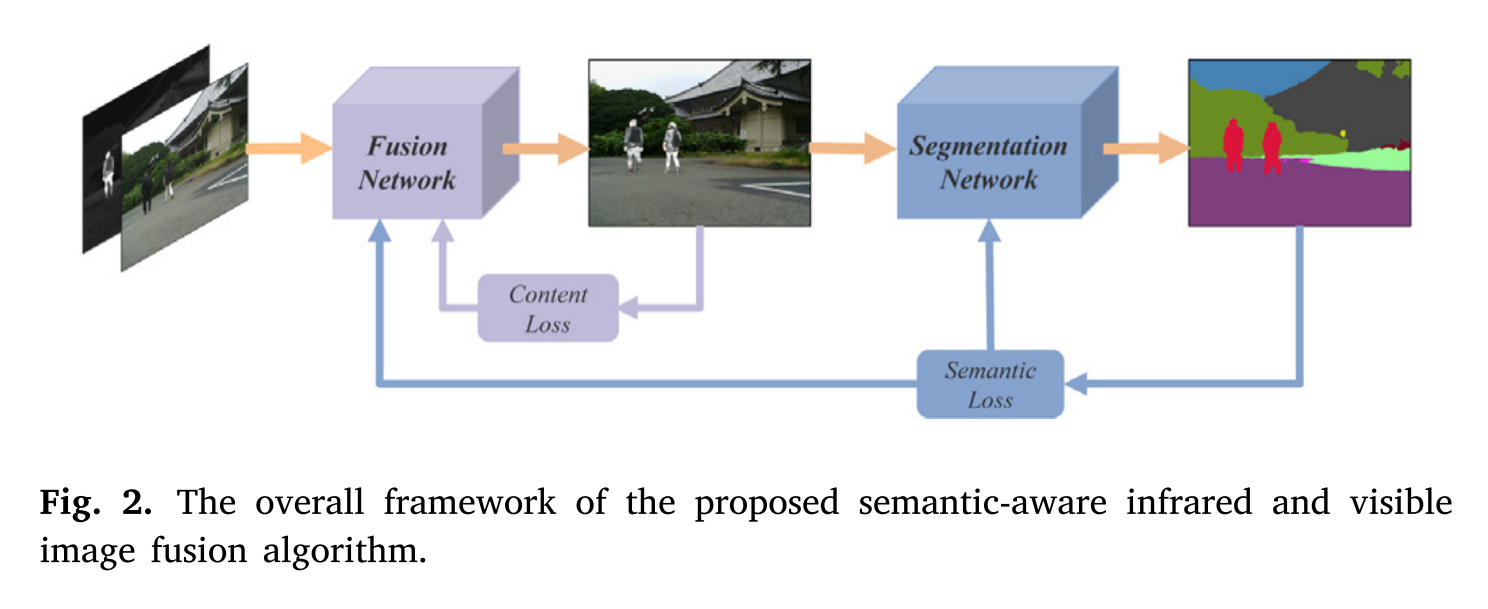
首先,设计了一种基于梯度残差密集块(GRDB)的轻量级融合网络,充分融合源图像中的互补信息。更具体地,我们应用特征提取模块𝐸𝐹从红外和可见光图像中提取具有丰富的细粒度细节信息的深度特征,其可以表示为:
其中𝐹𝑖𝑟和𝐹𝑣𝑖分别表示红外特征和可见特征。此外,在特征提取模块中嵌入了GRDB,在提取高层语义特征的同时,增强了对细粒度细节的描述能力。给定GRDB的输入𝐹𝑖,其输出𝐹𝑖+1可表示为: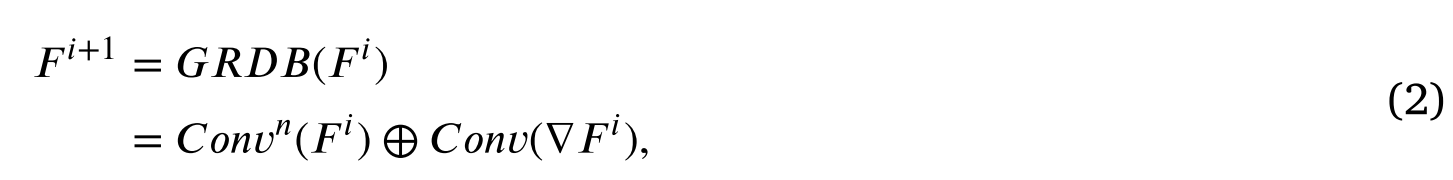
其中𝐶𝑜𝑛𝑣(·)表示卷积层,𝐶𝑜𝑛𝑣𝑛(·)表示𝑛级联卷积层。▽为梯度算子,即一种特殊的卷积运算,其卷积核是人工设计的。梯度算子将输入特征与高频卷积核进行卷积以提取细粒度细节信息。在本研究中,我们利用著名的 Sobel算子来计算梯度大小。此外,⊕表示元素求和。GRDB将可学习的卷积特征与梯度幅值信息聚合在一起。
然后,通过特征融合与图像重建模块对融合后的图像进行重建。采用级联融合策略融合深红外和可见光特征,包含丰富的细粒度空间细节。融合过程表示如下:
其中С(⋅)指通道维度中的连接。最后,通过图像重建器R𝐼从融合特征恢复𝐹𝑓融合图像𝐼𝑓,表示为:
此外,充分考虑到高级视觉任务对融合图像的要求,采用语义损失度量融合图像所包含的语义信息。更具体地说,我们引入了一个 分割模型𝑁𝑠 来对融合图像𝐼𝑓∈ R𝐻×𝑊×3 执行分割。分割结果𝐼𝑠∈ R𝐻×𝑊×𝐶与语义标签𝐿𝑠∈(1,𝐶)𝐻×𝑊之间差距可以反映融合图像所包含的语义信息的丰富程度,其中𝐻和𝑊分别为图像的高度和宽度,𝐶表示对象类别的数量。给定融合图像𝐼𝑓,语义感知过程表示为:
切分结果与语义标签之间差距表示为𝐿𝑠𝑒𝑚𝑎𝑛𝑡𝑖𝑐,定义为:
其中ε(·)表示误差函数。
Loss function
我们的SeAFusion旨在增强融合图像中的语义信息,同时提高视觉质量和评估指标。为了实现这些目标,我们从两个角度设计损失函数。一方面,SeAFusion需要充分融合源图像中的互补信息,如红外图像中的突出目标和可见光图像中的纹理细节。为此,内容损失被设计为确保融合图像的视觉保真度。另一方面,融合图像应当有效地促进高级视觉任务。为此,我们构造了一个语义损失来反映融合图像对高级视觉任务的贡献程度。
Content loss
为了促进融合模型融合更多有意义的信息,提高视觉质量和量化指标,我们设计了一个内容损失。内容物损失由两部分组成,即,强度损失𝐿𝑖𝑛𝑡和纹理损失𝐿𝑡𝑒𝑥𝑡𝑢𝑟𝑒。内容损失的确切定义表示如下:
其中,𝐿𝑖𝑛𝑡约束融合图像的整体表观强度,并𝐿𝑡𝑒𝑥𝑡𝑢𝑟𝑒强制融合图像包含更细粒度的纹理细节。这里,𝛼用于在强度损失𝐿𝑖𝑛𝑡和纹理损失之间取得平衡𝐿𝑡𝑒𝑥𝑡𝑢𝑟𝑒。
强度损失在像素级度量融合图像和源图像之间的差异。因此,我们将红外和可见光图像的强度损失定义为: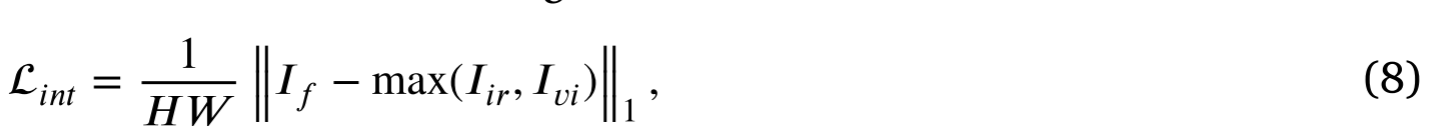
其中𝐻和𝑊分别是图像的高度和宽度,‖⋅‖1表示𝑙1范数,max(⋅)表示元素级最大选择。们通过最大选择策略整合红外和可见光图像的像素强度分布。然后,利用积分分布约束融合图像的像素强度分布。
我们期望融合后的图像能够保持最佳的亮度分布,同时保留源图像丰富的纹理细节。然而,强度损失仅为模型学习提供粗粒度分布约束。因此,引入了纹理损失,迫使融合图像包含更多的细粒度纹理信息。纹理损失定义为: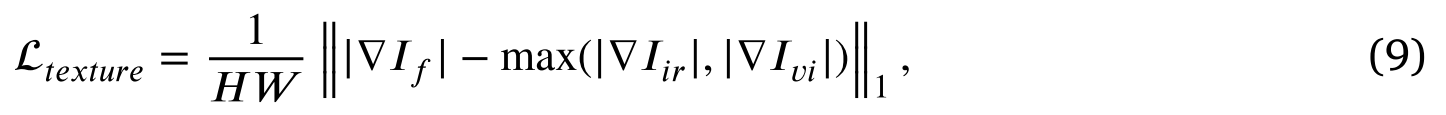
其中▽表示Sobel梯度算子,它测量图像的细粒度纹理信息。| ⋅|是绝对值操作。我们假设融合图像的最优纹理是红外和可见光图像纹理的最大集合。
结果表明,基于梯度残差密集块的融合网络在内容损失的指导下,能够同时获得最优的灰度分布和保留丰富的细节信息。换句话说,内容丢失可以有效地保证我们的模型实现第一个目标,即:改善融合图像的视觉质量和统计评估度量。
Semantic loss
充分增强融合图像的语义信息是算法的最大创新。我们创造性地设计了一个语义丢失来实现这个目标。具体地说,我们引入了一个实时语义分割模型[52]来分割融合图像,分割网络输出分割结果𝐼𝑠∈ R𝐻×𝑊×𝐶和辅助分割结果𝐼𝑠𝑎∈ R𝐻×𝑊×𝐶。语义损失包括两个因素,即,主要语义损失和辅助语义损失。主要语义损失和辅助语义损失定义如下: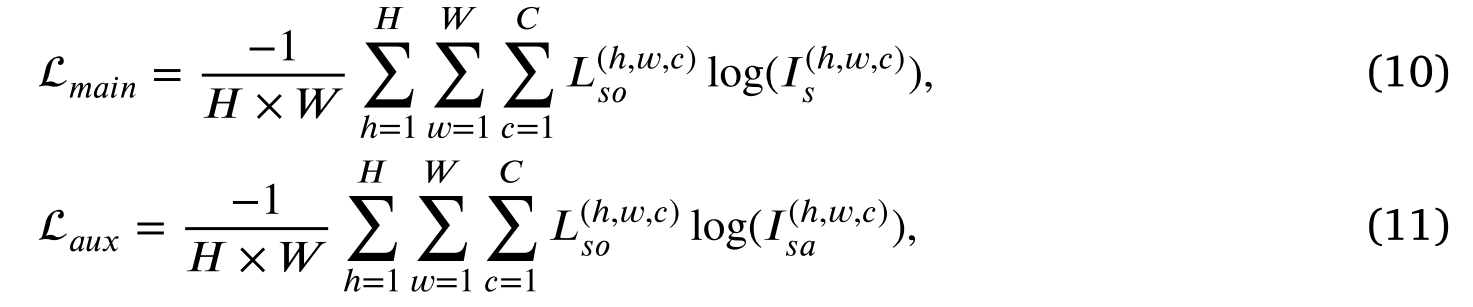
其中𝐿𝑠𝑜∈ R𝐻×𝑊×𝐶表示从分割标签变换的独热向量𝐿𝑠∈(1,𝐶)𝐻×𝑊。主语义丢失和辅助语义丢失从不同角度反映了融合图像所包含的语义信息。最终,语义损失表示如下:
其中𝜆为平衡主义损失和助义损失的常数,参考原文取0.1。值得注意的是,除了约束融合网络之外,还部署语义损失来训练分割模型。分割模型的损失函数和网络架构的更详细描述参见。
最后,构造一个联合损失来指导融合模型的训练,定义为:
其中𝛽是表征语义损失重要性的超参数𝐿𝑠𝑒𝑚𝑎𝑛𝑡𝑖𝑐。重要的是要强调,𝛽由于分割网络随着训练的进行而变得与融合模型自适应,所以根据联合的低级和高级自适应训练策略逐渐增加。
Network architecture
为了实现实时图像融合,提出了一种基于GRDB的轻量级红外与可见光图像融合网络,如图3所示。我们的融合网络由特征提取器和图像重建器组成,其中特征提取器包含两个GRDB以提取细粒度特征。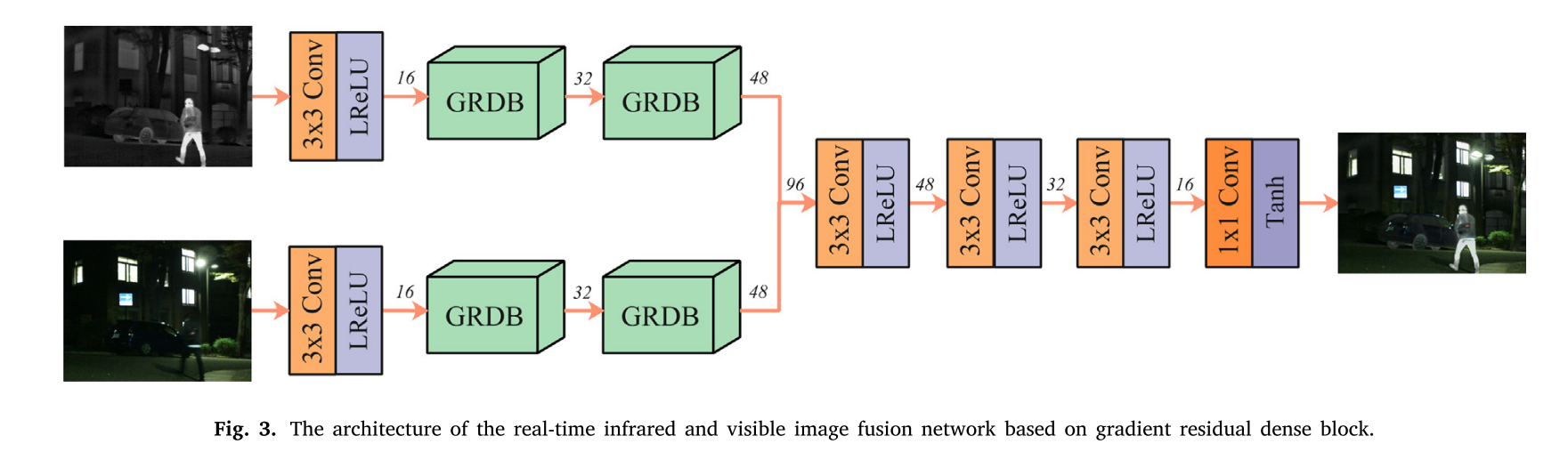
如图3所示,特征提取器包括两个并行的红外和可见光特征提取流,并且每个特征提取流包含公共卷积层和两个GRDB。采用核大小为3 × 3、激活函数为Leaky校正线性单元(Leaky Rectified Linear Unit,LReLU)的普通卷积层提取浅层特征。紧接着是两个GRDB,用于从浅层特征中提取细粒度特征。GRDB的具体设计如图4所示。梯度剩余稠密块是resblock的变体,其中主流采用密集连接,而残差流集成梯度操作。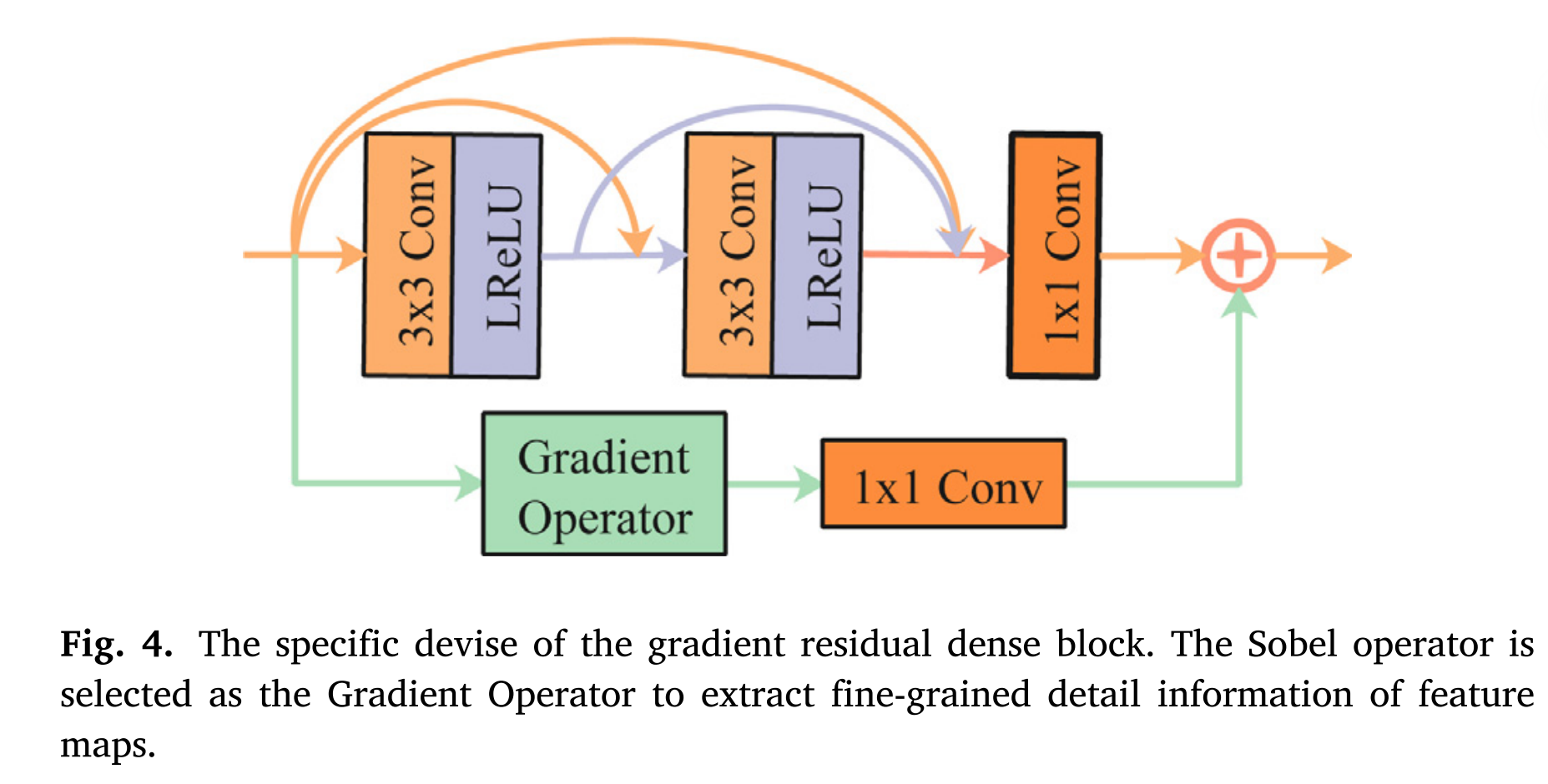
从图4中我们可以观察到,主流部署了两个3 × 3的卷积层和一个普通的卷积层,卷积层的核大小为1 × 1。需要强调的是,我们在主流中引入了密集连接,充分利用了各个卷积层提取的特征。残差流采用梯度运算计算特征的梯度大小,并采用1 × 1规则卷积层消除信道维数差异。然后,通过逐元素加法将主密集流和残差梯度流的输出相加,以集成深度特征和细粒度细节特征。
然后,采用拼接策略对红外和可见光图像的细粒度特征进行融合,并将融合结果送入图像重构器,实现特征聚合和图像重构。该图像重建器由三层3 × 3卷积层和一层1 × 1卷积层组成。所有3 × 3卷积层都使用LReLU作为激活函数,而1 × 1卷积层的激活函数是Tanh。
众所周知,在图像融合任务中,信息丢失是一个灾难性的问题。因此,我们的融合网络中的填充被设置为相同,并且除了1 × 1卷积层之外,跨距被设置为1。结果表明,该网络不引入任何降采样,融合后的图像大小与源图像一致。
Joint low-level and high-level adaptive training strategy
现有的任务驱动低级视觉方法要么采用预先训练好的高级模型指导低级视觉任务模型的训练,要么在一个阶段联合训练低级和高级视觉任务模型。然而,在图像融合领域中,难以提供融合图像的地面真值来训练高级视觉任务模型。此外,单阶段联合训练策略可能导致难以维持低水平和高水平视觉任务之间的性能平衡。为此,我们设计了一个低水平和高水平联合训练策略来训练我们的融合网络。更具体地,我们迭代地训练融合网络和分割网络,并且将迭代次数设置为𝑀。首先,在联合损耗的指导下,利用Adam优化器对融合网络中的所有参数进行优化。此外,𝛽通过迭代动态调整节点损耗超参数,其表示如下:
其中𝑚表示第𝑚次迭代。𝛽 由于随着迭代次数的增加,分割网络更好地拟合融合模型,因此随着训练的进行,语义损失逐渐增加,并且语义损失可以更准确地指导融合网络的训练。𝛾 是用于平衡语义损失和内容损失的常数。然后,在当前融合结果的基础上,通过优化语义损失来更新分割模型的参数。在每次迭代中,融合模型和分割模型的训练步骤分别为𝑝和𝑞。算法1中总结了联合低层和高层自适应训练策略。
版权归原作者 小郭同学要努力 所有, 如有侵权,请联系我们删除。