
 渲染可以理解为三维模型或场景转换成二维图像的过程,广泛应用于电影、虚拟现实、建筑和产品设计等领域。在计算机图形学中,渲染通常指的是使用计算机程序对三维场景进行可视化的过程。假如游戏中的场景有一个3d模型、一个摄像机和光源,渲染要做的就是在摄像机的视角,3d模型结合光源进行计算,以2D的形式呈现出来。从三维重建算法角度考虑,渲染提供了以图片作为来源的三维重建算法的监督信号,可以通过将相同视角重建模型的渲染结果与输入图像做Loss以优化模型。
渲染可以理解为三维模型或场景转换成二维图像的过程,广泛应用于电影、虚拟现实、建筑和产品设计等领域。在计算机图形学中,渲染通常指的是使用计算机程序对三维场景进行可视化的过程。假如游戏中的场景有一个3d模型、一个摄像机和光源,渲染要做的就是在摄像机的视角,3d模型结合光源进行计算,以2D的形式呈现出来。从三维重建算法角度考虑,渲染提供了以图片作为来源的三维重建算法的监督信号,可以通过将相同视角重建模型的渲染结果与输入图像做Loss以优化模型。
 过去常用基于volumes、point clouds、meshes、depth maps和implicit进行场景表示。NeRF是一种新印的神经场景表示方法,推进了新颖的视图合成和逼真渲染的技术水平。
过去常用基于volumes、point clouds、meshes、depth maps和implicit进行场景表示。NeRF是一种新印的神经场景表示方法,推进了新颖的视图合成和逼真渲染的技术水平。
NeRF的思想是通过多张图片重构出场景的3D隐式表示——辐射场,由观察方向像素发射一条射线,采样得到辐射场中若干个点的(x,y,z),与观察方向通过position encoding映射到高维空间,输入到MLP,计算出点的RGB和体密度。一条射线采样的所有点加权求和得出该像素值,最后将预测的像素值与GT值计算损失。
贡献:引入MLP预测像素颜色和体密度;将position encoding引入网络,增强其在高分辨率下的表征能力;采用coarse fine分层采样方式,能够更好适应高分辨率的表征(先均匀采样64个点估计出密度分布函数,再使用逆采样对高密度区域随机采样128个点。
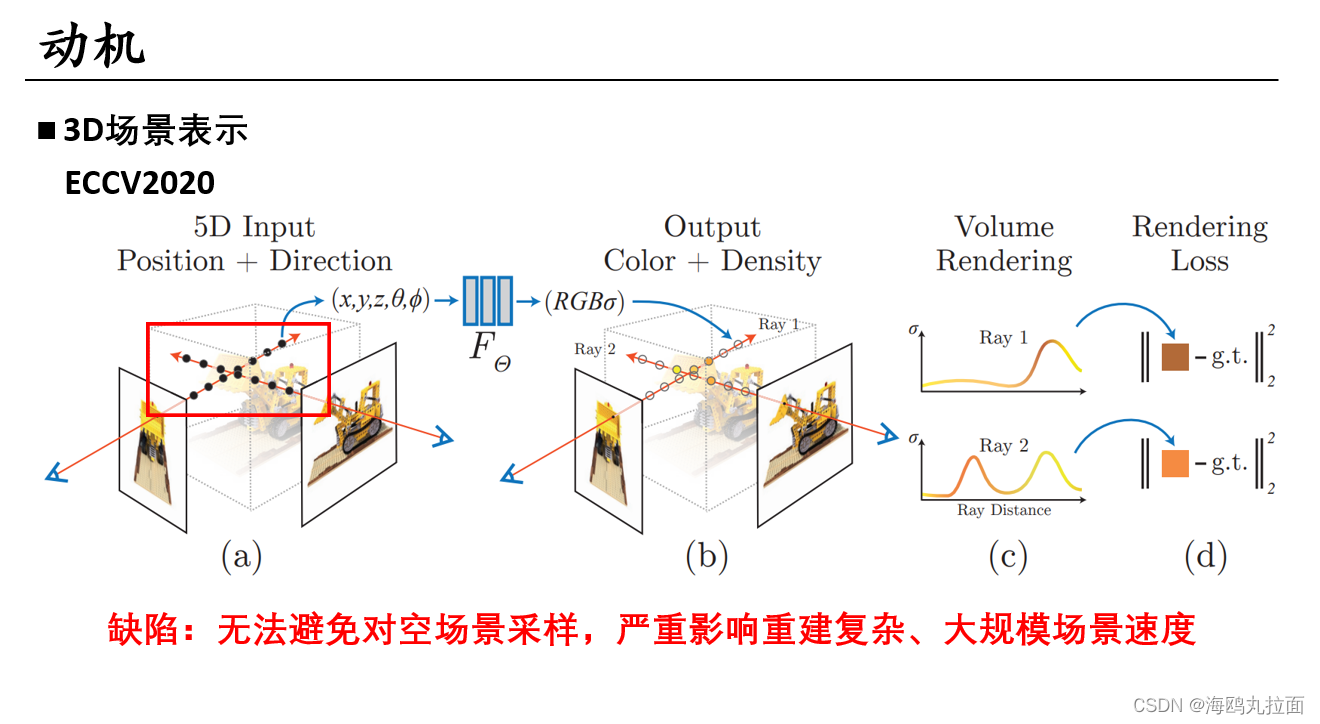
缺陷:nerf无法避免对空场景进行采样,严重影响重建复杂、大规模场景的速度。

Point-NeRF采用点云进行渲染并不是首创,但之前的方法都没有取得很好地效果。原因是使用的方法是splatting(抛雪球法)。它用一个函数计算每个点投影的影响范围,再用高斯函数定义范围内的点或者小区域像素的强度分布,从而计算出它们对图像的总体贡献。所有的splatting合起来就是一张渲染图片。模拟了雪球被抛到墙壁上留下的扩散状痕迹。
之前的方法要么对点云栅格化后做splatting要么对特征splatting,再用CNN渲染。Point-NeRF直接从3D渲染,效果更好。
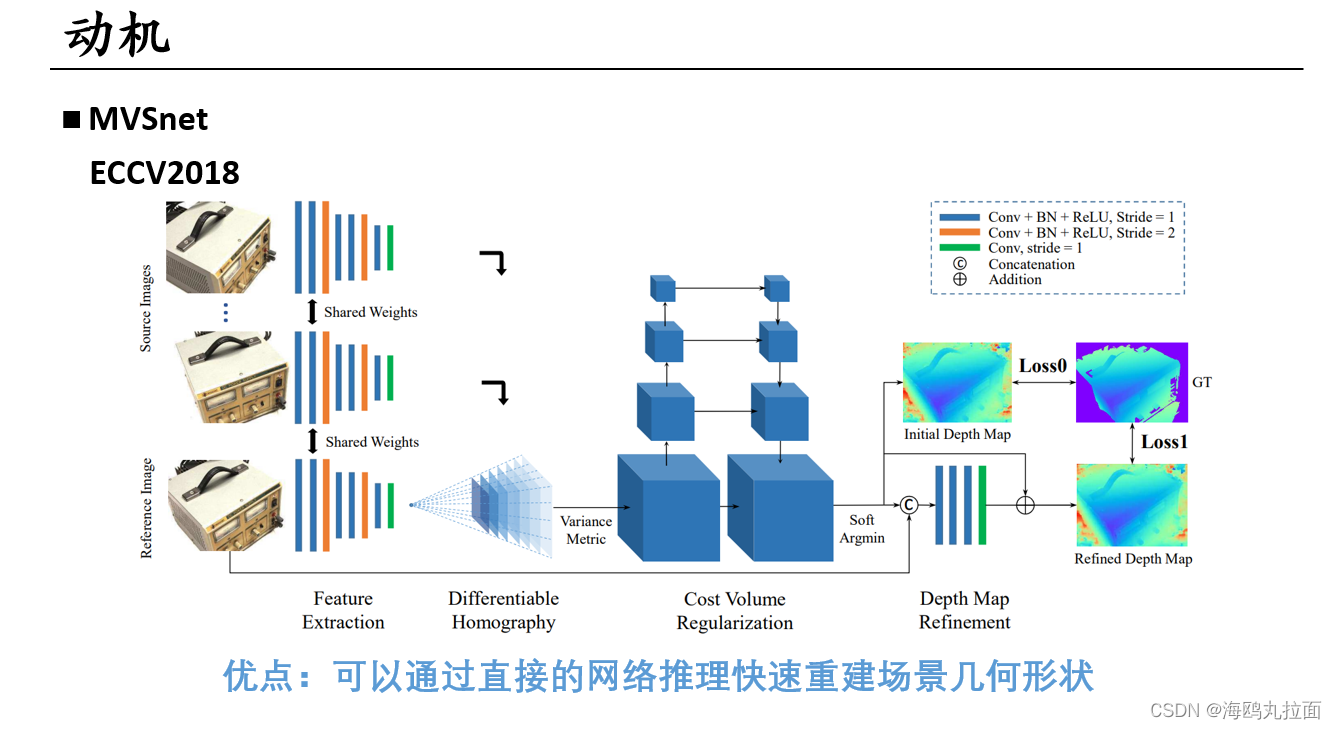 Nerf渲染同样为输入多视角图片,想到用MVSnet作为生成点云方法是合情合理的 。
Nerf渲染同样为输入多视角图片,想到用MVSnet作为生成点云方法是合情合理的 。
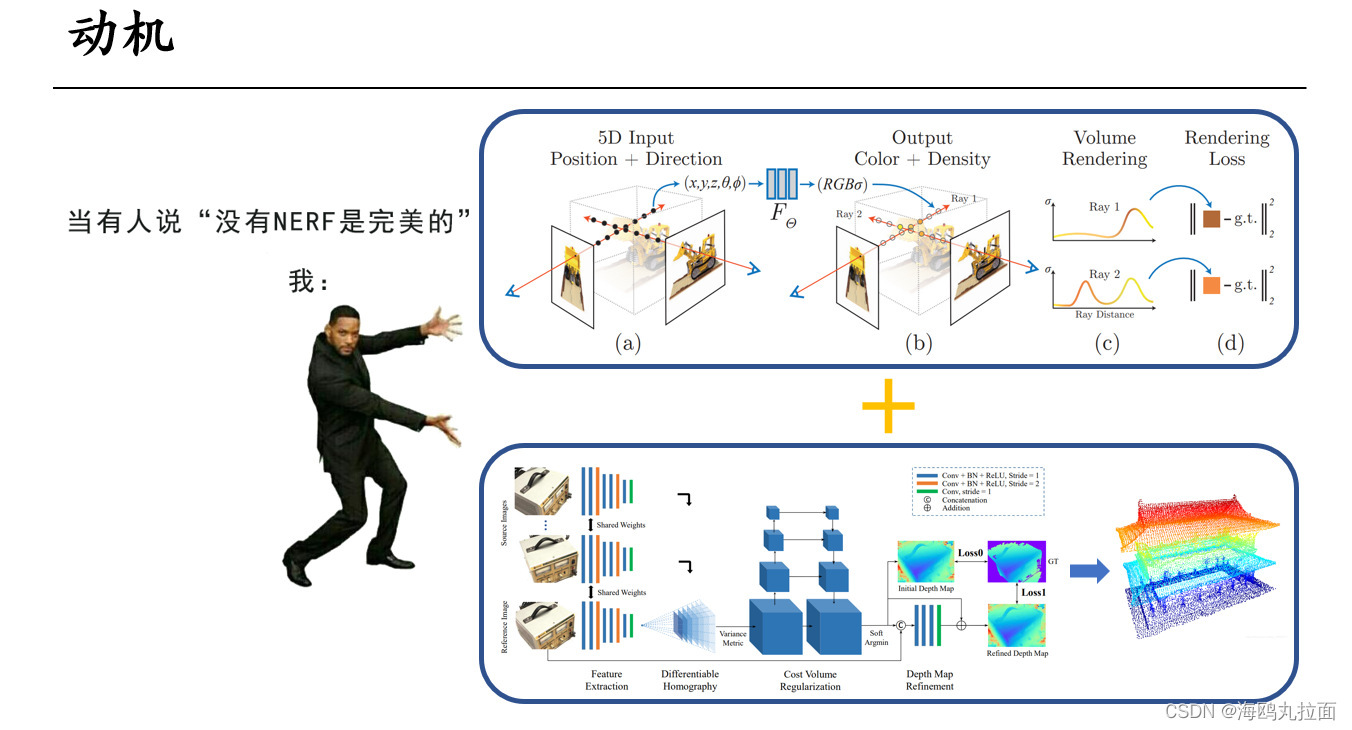 Mvsnet+Nerf,点云+神经渲染,既普通又新奇的方法。
Mvsnet+Nerf,点云+神经渲染,既普通又新奇的方法。


1.为了克服nerf逐场景训练很慢的缺陷,pointnerf在网络中采用了一些预训练的手段,实现了场景生成的高效初始化。
2.尽管NeRF采用了coarse and fine的分层采样策略来尽可能多的在物体表面采样,但难免还是会对大量空区域进行采样,不如点云。
3.但点云包含的信息往往很少,所以传统点云重建中往往要特别稠密才能表达复杂的几何特征。Point-NeRF为了让点云储存更多信息,在采样时取临近的一些点,按一定的权重进行特征融合。这些点的特征来自于生成网络中,对输入图像进行2D卷积,并融合到生成的点云中。
4.根据相机内参(焦距、主点)外参(位姿),将每个像素点深度值转换为相机坐标系下的三维坐标,再根据相机坐标系变换到世界坐标系。

端到端的渲染损失一起训练。
以合理的权重初始化mlp,节省了每个场景的拟合时间。
除了使用完整的生成网络,还支持使用从其他方法(如COLMAP)重建的点云,其中不包括MVS网络的模型仍然可以为每个点提供有意义的初始神经特征。
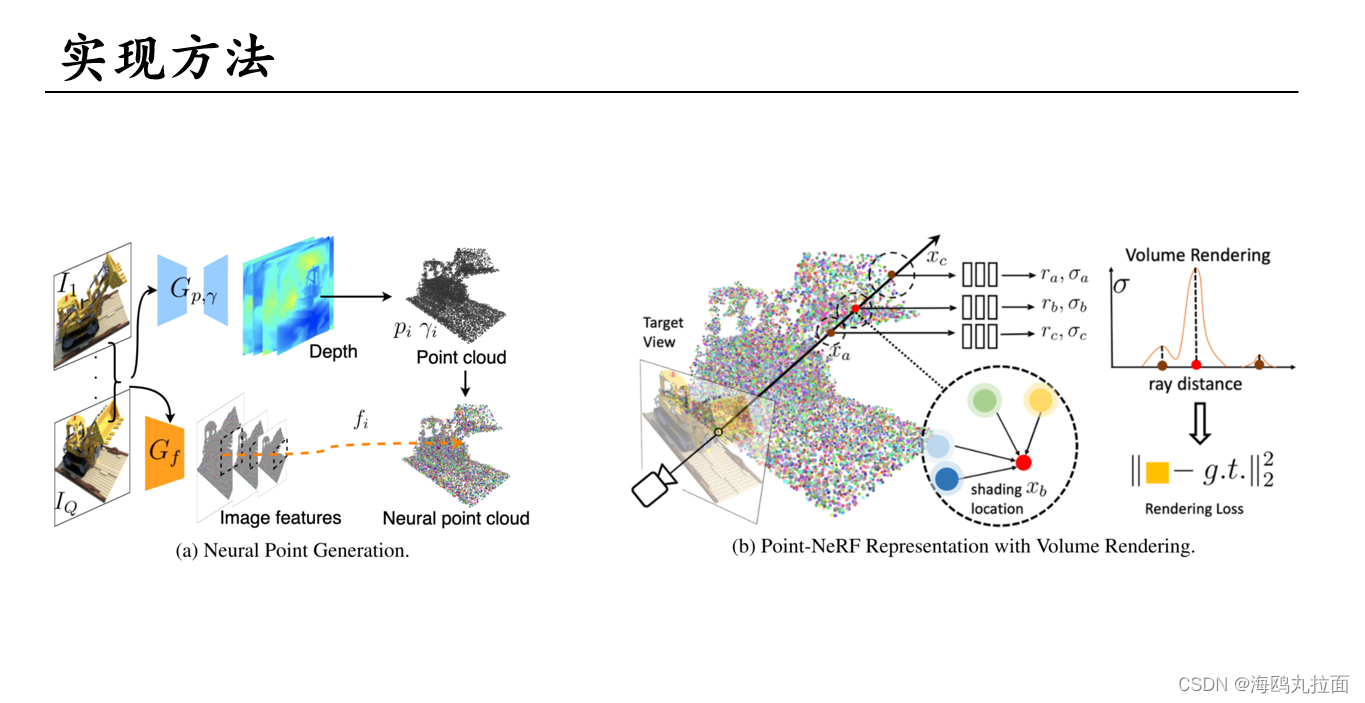
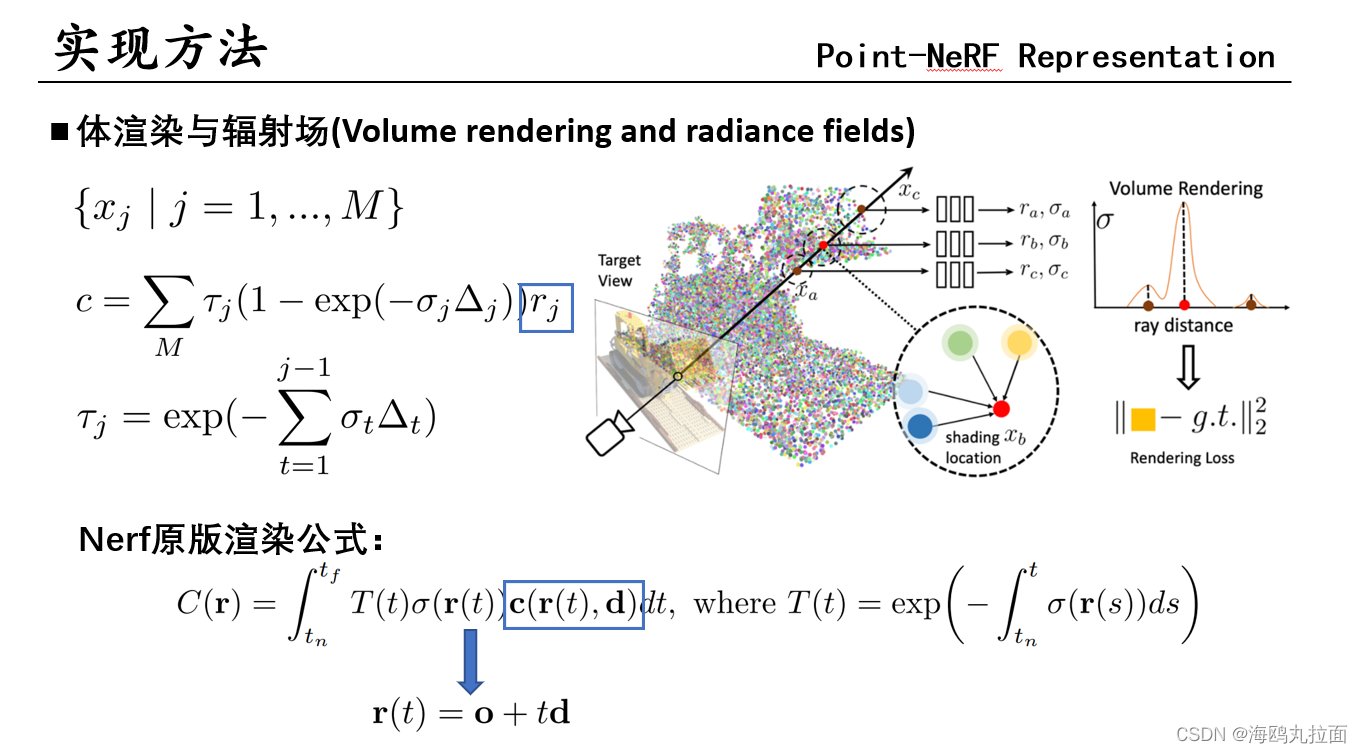 沿着采样射线采样M个点,r为辐射值和NeRF的c是差不多的概念。整个场景表达公式和NeRF差不多。
沿着采样射线采样M个点,r为辐射值和NeRF的c是差不多的概念。整个场景表达公式和NeRF差不多。
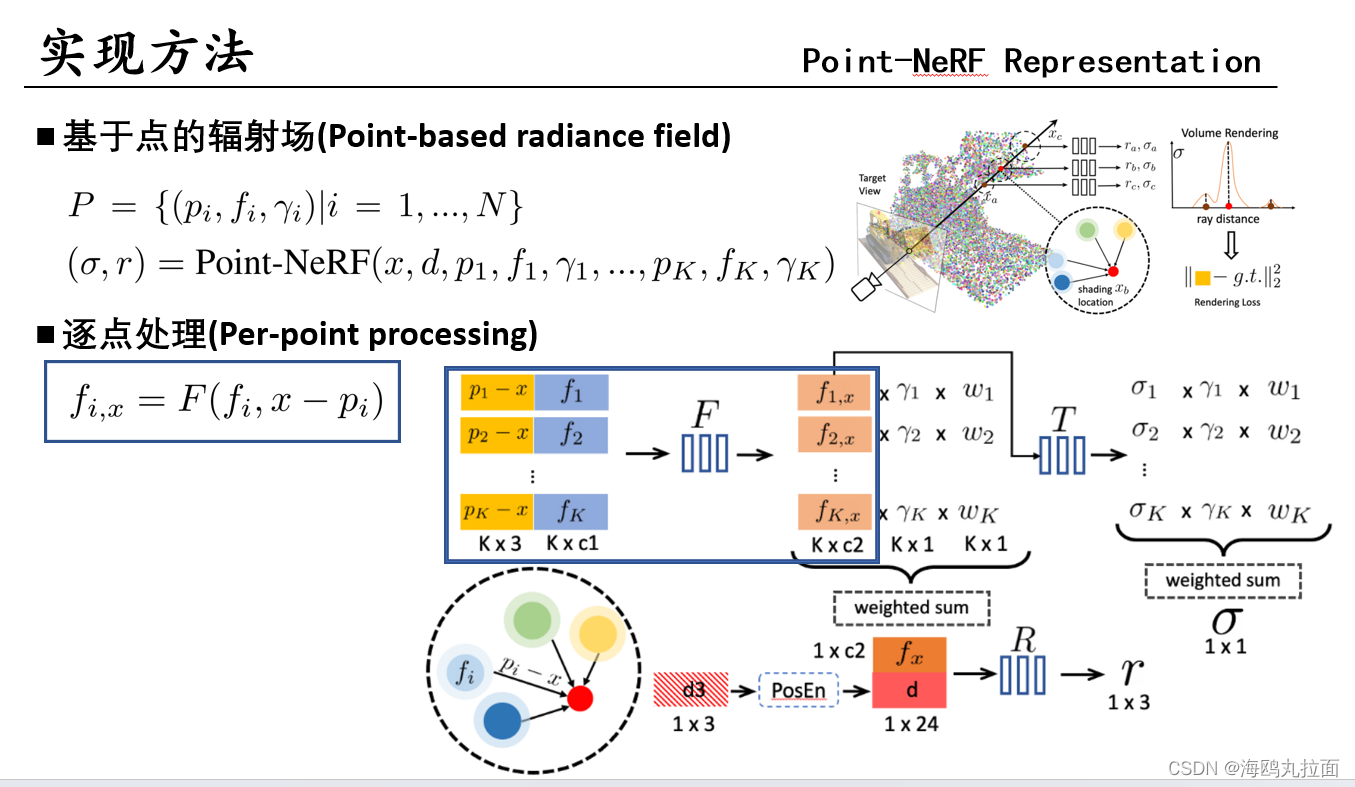 输入x采样位置(着色点) 视角d 周围K个点及其特征f、置信度γ,输出体密度σ,辐射值r。
输入x采样位置(着色点) 视角d 周围K个点及其特征f、置信度γ,输出体密度σ,辐射值r。
对目标着色点x,不是直接取周边点特征进行融合。周边点特征提取后,先经过一个MLP_F,这个神经网络实现了输入周围一个点的特征,以及着色点和该点间距,预测该点在着色点的特征向量。这样做的原因是该点的特征通过2DCNN提取,编码了点pi周边的局部内容。使用点间距作为输入,使网络对点具有平移不变性,泛化性更好

w(反距离权重)和γ(点置信度)作为权重,融合采样点周围点特征,计算出采样点处特征。将特征和视角d送入MLP_R,算出采样点处辐射值r。
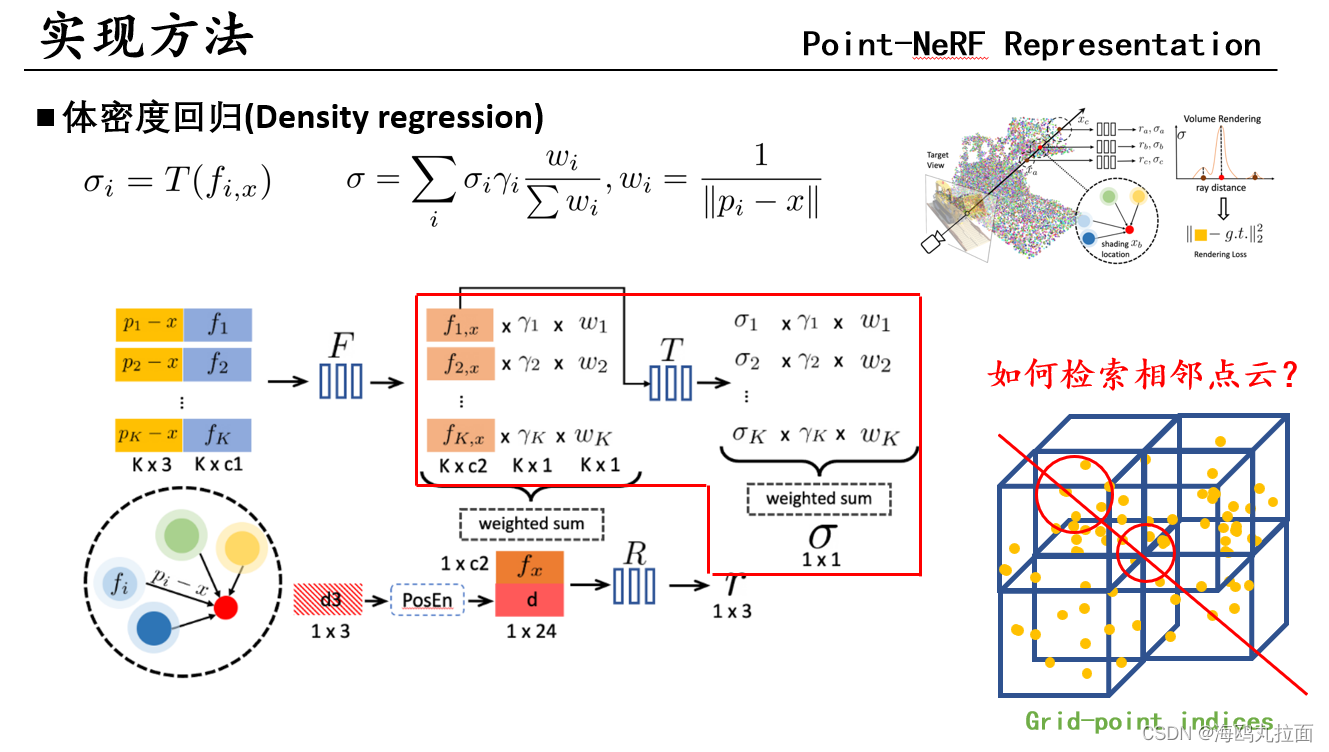
公式跟计算r差不多,变为先解码周围点的体密度,再聚合。
渲染时候需要对点云进行检索,相较于体素网格,点云的检索要慢得多。Point-NeRF建立了grid-point indices(网格-点索引)储存神经点到均匀间隔的立方体3D网格中,具有球形体素的形状。通过光线行进,只搜索神经点近邻,并在被占据的网格或附近网格中进行着色计算。
优势:因为着色点只存在于存在神经点的位置,就避免了在空白空间进行计算;可以根据索引高效检索附近的点,大大加快查询速度。实验中取K = 8个点作为近邻。
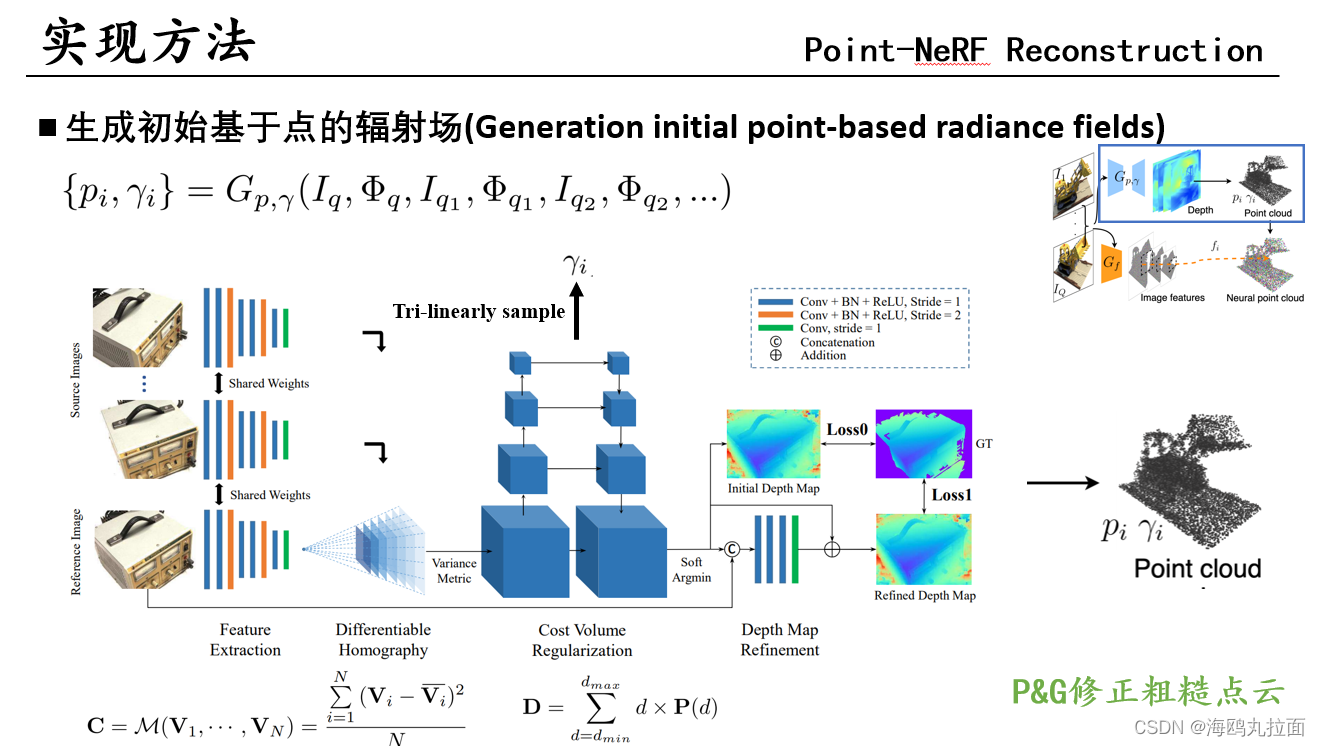
普通的MVSNet,用于计算出点云p和置信度γ。γ由概率空间三线性插值得到。 公式输入为基准视图和用于基准视图外的相邻视图,通常只采用两个。
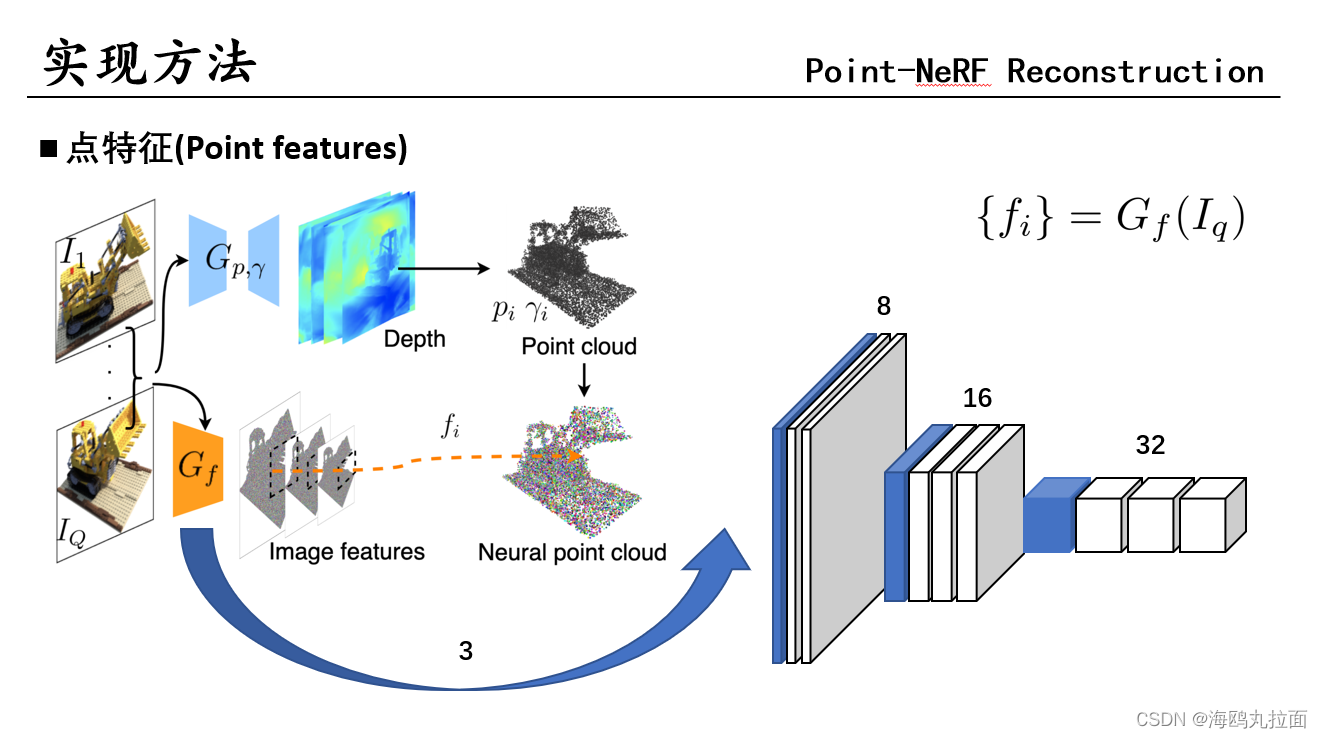 普通的VGG网络,特征和点对齐。
普通的VGG网络,特征和点对齐。
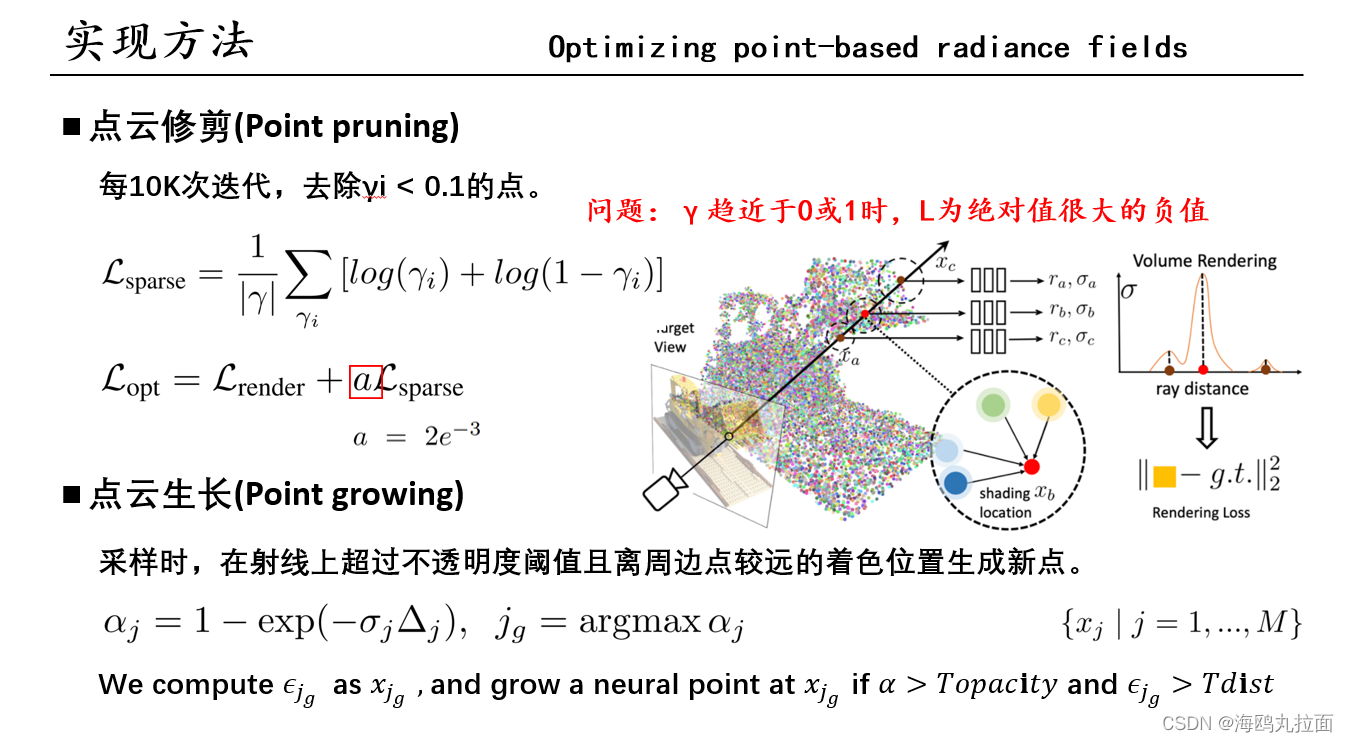
初始点云通常会包含降低渲染质量的空洞和异常值。在逐场景优化过程中,为了解决这个问题,作者发现直接优化现有点的位置会使训练不稳定,无法填充较大的空洞,于是采用了新颖的点pruning和growing策略,逐渐提高集合建模和渲染质量。
在重建出初始点云之后,对点云里的特征f、置信度γ还有MLP里的参数进行优化。之前的几个计算公式都用到了置信度γ,它用于描述一个点位于物体表面的概率,它也被用在体密度渲染上,所以当一个点的γ较低时,说明体密度很低,可以认为那个位置是空的,可以被删除。实际实验中,每10K次迭代,去除γi<0.1的点。
使用如公式所示Loss来优化γ,作者认为这样的loss可以让置信度趋于0或者1。这个loss是一个负值,当γ趋近于0或1时,都会让这个Loss成为一个绝对值很大的负值。计算出来后,乘以一个值很小的a与渲染损失相加,作为整体的Loss。实验中取了a = 2e^-3
点云扩展工作在着色点采样的时候,会计算一条采样射线上着色位置的不透明度,在该射线上不透明度超过阈值且离周边点较远的着色位置生成新点。这样的方法不仅可以实现空洞填补,还能控制新点的生成。因为需要满足不透明度和距离两个条件,所以添加的点都是相对有效、缺失的点。
xj = 每条射线的着色位置;αj = 着色位置的不透明度,体密度σ越大(该点存在物体概率)越大,不透明度越小,即该点在物体表面概率越大,αjg = 最大不透明度;jg = 每条射线采样点取得了最大不透明度的位置;xjg = Cjg = 取得了最大不透明度的位置间距。


作者死鸭子嘴硬,某些精度比不过别人就找理由(虽然确实很有道理)。赢就完事了。
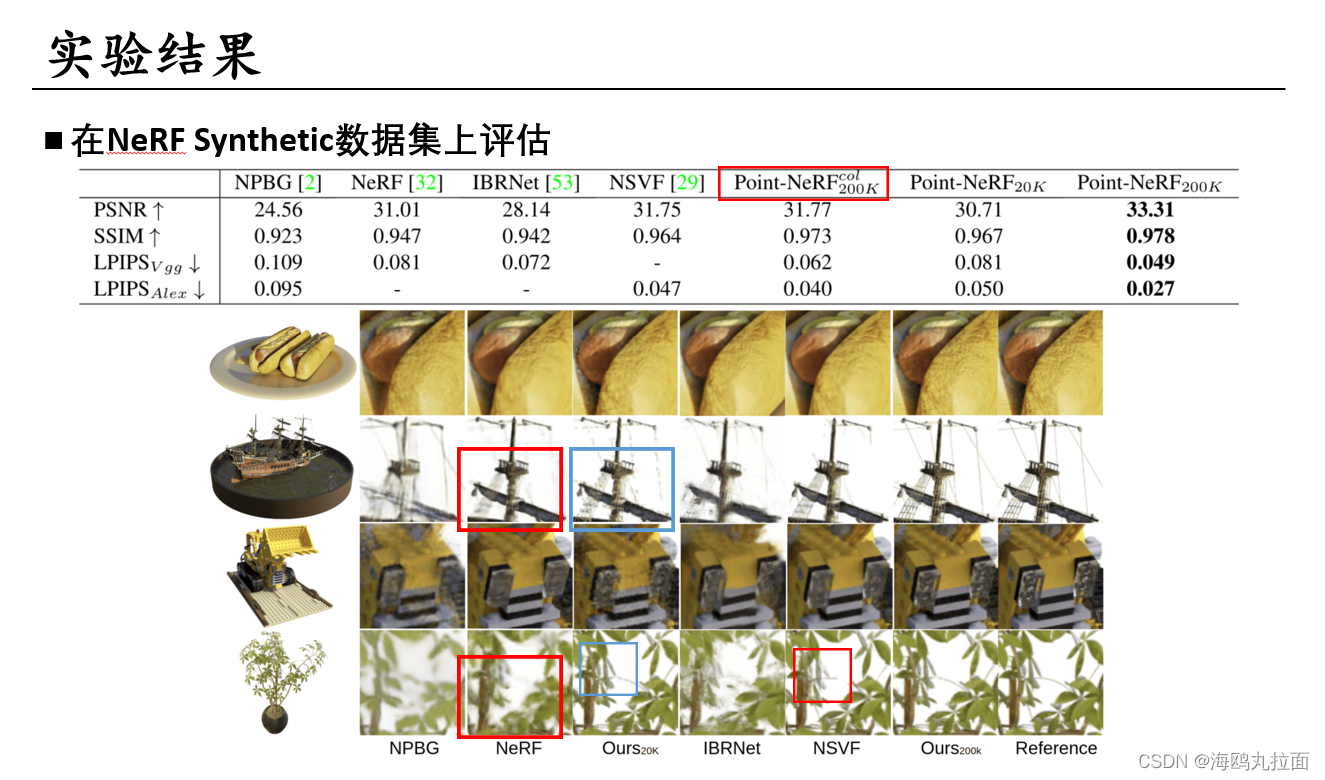 细节部分重建的精度很好。
细节部分重建的精度很好。

大场景同样表现优秀。ScanNet的结果很震撼,看不出是渲染出来的。
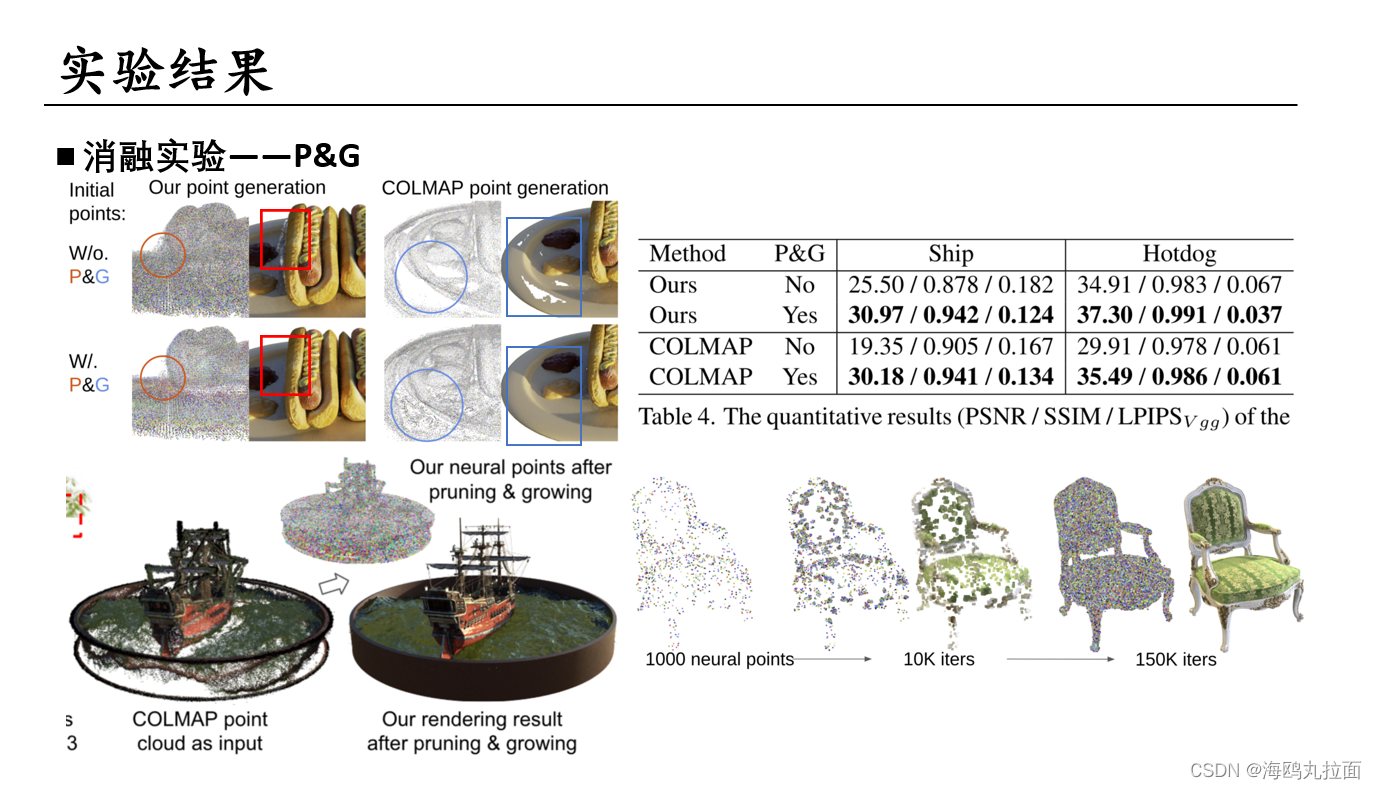 显而易见经过pruning&growing处理后效果很好,特别是COLMAP重建出的粗糙点云,经过处理后取得了巨大的提升。原始仅有1000个COLMAP产生点的椅子,经过growing后产生了高质量的新视图。
显而易见经过pruning&growing处理后效果很好,特别是COLMAP重建出的粗糙点云,经过处理后取得了巨大的提升。原始仅有1000个COLMAP产生点的椅子,经过growing后产生了高质量的新视图。
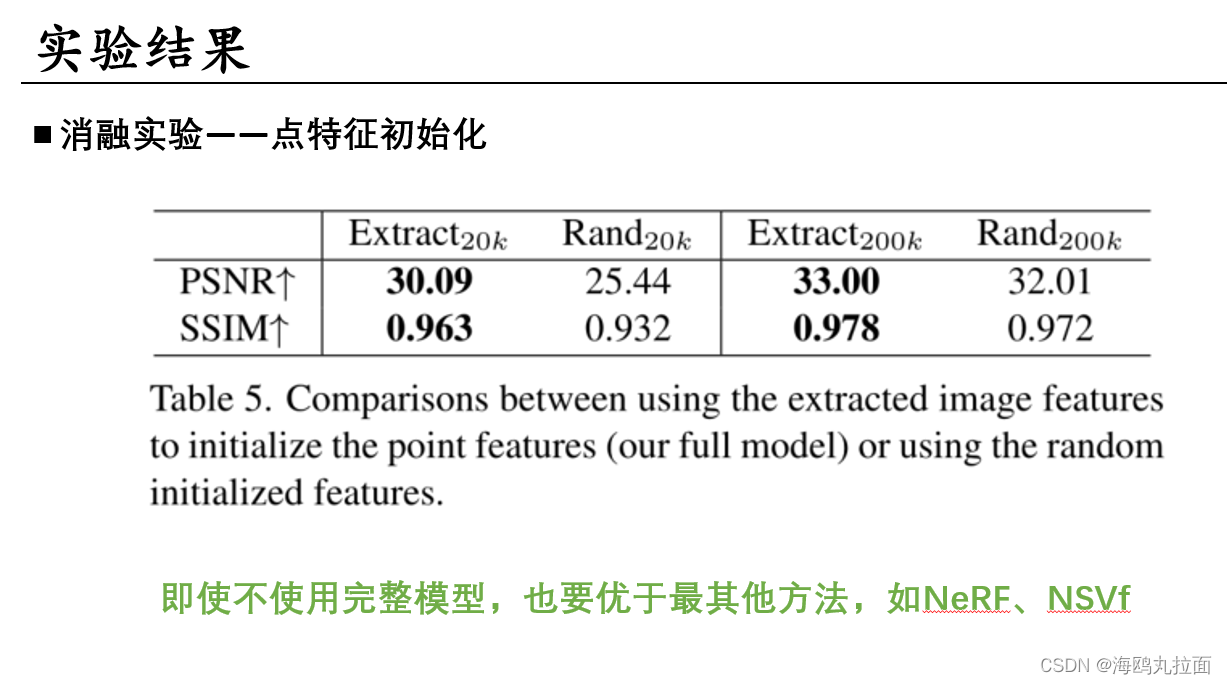
比较使用提取图像特征,即Gf 2DVGG网络来初始化特征,和使用随机初始化特征(没懂是什么)。实验表明具有图像特征的神经点不仅性能更优,收敛速度也快得多。不过即使随机初始化的神经点不能达到完整模型效果,也仍然优于NeRF、NSVF等方法。
 总结,展望部分保密。
总结,展望部分保密。

论文链接:https://arxiv.org/abs/2201.08845
代码:GitHub - Xharlie/pointnerf: Point-NeRF: Point-based Neural Radiance Fields
有点bug,不过训练好的模型可以直接跑出测试结果。
版权归原作者 海鸥丸拉面 所有, 如有侵权,请联系我们删除。