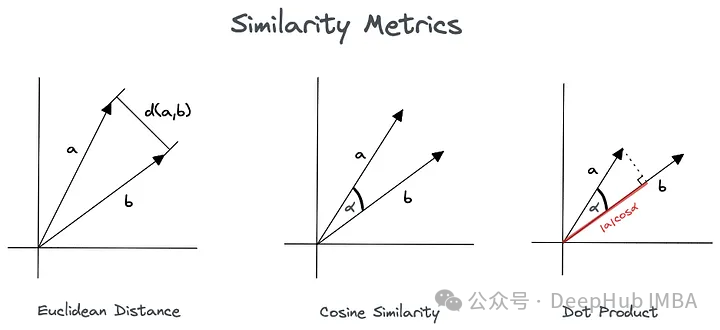
NLP中的嵌入和距离度量
本文将深入研究嵌入、矢量数据库和各种距离度量的概念,并提供示例和演示代码。
人工智能时代:AI提示工程的奥秘 —— 驾驭大语言模型的秘密武器
掌握了提示工程的艺术,你就能更好地与大语言模型沟通,发挥它们的最大效能。这不仅是一项技能,更是一种理解机器智能并能与之和谐共处的方式。让我们在智慧的海洋中乘风破浪,探索更多未知的可能。随着大语言模型的快速发展,语言AI已经进入了新的阶段。这种新型的语言AI模型具有强大的自然语言处理能力,能够理解和生
工信部颁发的人工智能证书《自然语言与语音处理设计开发工程师》证书到手啦!
由国家工信部权威认证的人工智能证书是跨入人工智能行业的敲门砖,随着人工智能技术的发展越来越成熟,相关的从业人员也会剧增,证书的考取难度也会变高。如果已经从事或者准备从事人工智能行业的人员,对于考证宜早不宜迟,早拿证早安心,国家对人工智能行业从业证书的要求将会越来越高,现在证书刚开始推广,无论从费用上
NLP自然语言处理的发展:从初创到人工智能的里程碑
自然语言处理(Natural Language Processing,NLP)是一种机器学习技术,使计算机能够解读、处理和理解人类语言。如今,组织具有来自各种通信渠道(例如电子邮件、短信、社交媒体新闻源、视频、音频)的大量语音和文本数据。他们使用 NLP 软件自动处理这些数据,分析消息中的意图或情绪
【GitHub项目推荐--AI 开源项目/涵盖 OCR、人脸检测、NLP、语音合成多方向】【转载】
今天为大家推荐一个相当牛逼的AI开源项目,当前 Star 3.4k,但是大胆预判,这个项目肯定要火,未来 Star 数应该可以到。,目前总数已经超过了180个,基本上是每个月都保持10-20个更新,而且更新的速度应该是越来越快,这个已经感觉到很爽了啊。首先,“无需深度学习背景、无需数据与训练过程”,
Mistral AI vs. Meta:顶级开源LLM比较
LLM在过去两年中有了巨大的发展,这使得获得高质量的回复成为可能,而且很难区分是谁写了这些回复,是人还是机器。目前的研究的重点正在从生成高质量的响应转向创建尽可能小的LLM,以便能够在资源较少的设备上运行,以节省成本并使其更容易获得。Mistral是积极研究这一领域的公司之一,正如我们所看到的他们取

使用mergekit 合并大型语言模型
在本文中我们将介绍各种合并算法,研究如何实现它们,并深入研究它们的工作原理。还将使用mergekit工具合并Mistral、WizardMath和CodeLlama模型。
引领AI变革:边缘计算与自然语言处理结合的无尽可能
随着人工智能(AI)和自然语言处理(NLP)的发展,边缘计算作为一种新兴的计算模式备受关注。边缘计算将计算和数据处理能力从云端移动到离用户更近的边缘设备上,提供更低的延迟和更高的实时性。然而,边缘计算仍面临数据安全、网络稳定性、实时性、异构性和应用场景等挑战。同时,边缘计算也在智能交通、智能医疗等领
机器学习中使用的独热编码
独热编码
2024年1月10日最热AI论文Top5:DebugBench、AI智能体对齐、开放域问答系统、谈判游戏、联邦学习
大型语言模型(LLMs)已经展示出了卓越的编码能力。然而,作为编程熟练度的另一个关键组成部分,LLMs的调试能力相对未被充分探索。之前对LLMs调试能力的评估受到数据泄露风险、数据集规模以及测试错误种类多样性的显著限制。为了克服这些不足,我们引入了DebugBench,一个由4,253个实例组成的L

Vision Mamba:将Mamba应用于计算机视觉任务的新模型
Mamba是LLM的一种新架构,与Transformers等传统模型相比,它能够更有效地处理长序列。就像VIT一样现在已经有人将他应用到了计算机视觉领域
Flowise+LocalAI部署--Agent应用
Flowise 是一个开源的用户界面可视化工具,它允许用户通过拖放的方式来构建自定义的大型语言模型(LLM)流程。Flowise基于LangChain.js,是一个非常先进的图形用户界面,用于开发基于LLM的应用程序。Flowise还支持Docker和NodeJS,可以在本地或者在容器中运行。如果有
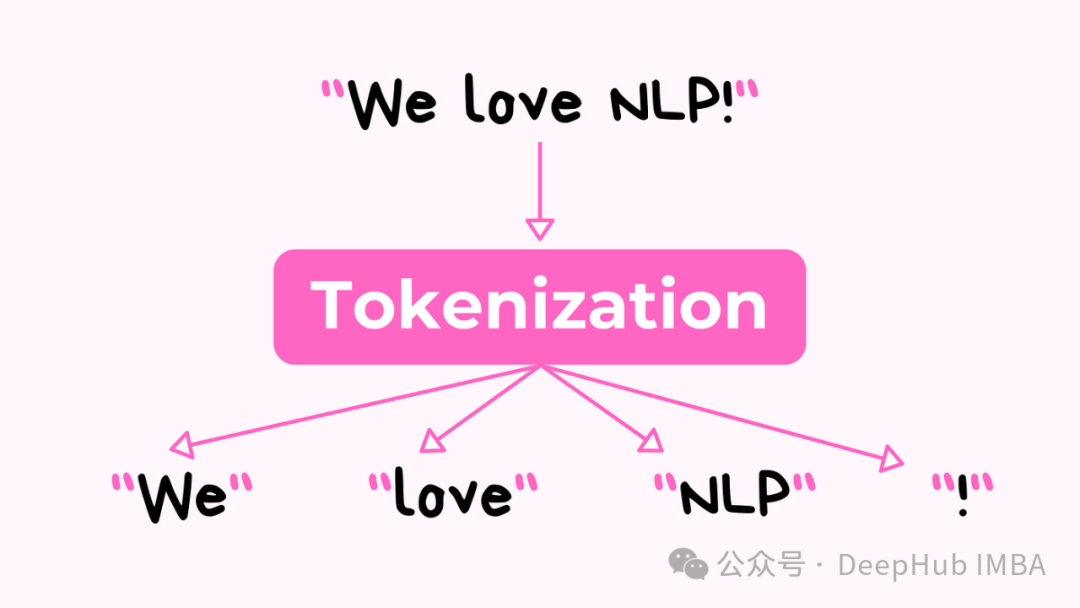
Tokenization 指南:字节对编码,WordPiece等方法Python代码详解
计算机要处理语言,首先需要将文本转换成数字形式。这个过程由一个称为标记化 Tokenization。
【AI视野·今日NLP 自然语言处理论文速览 第七十一期】Fri, 5 Jan 2024
AI视野·今日CS.NLP 自然语言处理论文速览Fri, 5 Jan 2024Totally 28 papers👉上期速览✈更多精彩请移步主页Daily Computation and Language PapersLLaMA Pro: Progressive LLaMA with Block
LLM、AGI、多模态AI 篇一:开源大语言模型简记
Qwen是阿里云推出的大型模型系列(通义千问),其多模态版本Qwen-Audio支持各种音频和文本输入,能输出文本,适用于所有类型音频的多任务学习,在各种基准测试任务中都取得了令人印象深刻的性能。Llama2-Chinese是基于 Llama2进行中文预训练的开源大模型,是开源社区第一个能下载、能运
人工智能的新篇章:深入了解大型语言模型(LLM)的应用与前景
LLM(Large Language Model)技术是一种基于深度学习的自然语言处理技术,旨在训练能够处理和生成自然语言文本的大型模型。
【NLP】2024年改变人工智能的前六大NLP语言模型
2018年,谷歌人工智能团队推出了一种新的自然语言处理(NLP)尖端模型——BERT,即变形金刚的双向编码器表示。它的设计使模型能够考虑每个单词左右两侧的上下文。虽然概念上很简单,但BERT在11项NLP任务上获得了最先进的结果,包括问答、命名实体识别和其他与一般语言理解有关的任务。该模型标志着NL
【AI视野·今日NLP 自然语言处理论文速览 第六十一期】Tue, 24 Oct 2023
AI视野·今日CS.NLP 自然语言处理论文速览Tue, 24 Oct 2023 (showing first 100 of 207 entries)Totally 100 papers👉上期速览✈更多精彩请移步主页Daily Computation and Language PapersLIN
【自然语言处理】用Python从文本中删除个人信息-第二部分
根据维基百科,NER是:命名实体识别(NER)(也称为(命名)实体识别、实体分块和实体提取)是信息提取的一个子任务,旨在定位非结构化文本中提到的命名实体,并将其分类为预定义的类别,如人名、组织、位置、医疗代码、时间表达式、数量、货币值、百分比等。因此,这一切都是关于寻找和识别文本中的实体。一个实体可
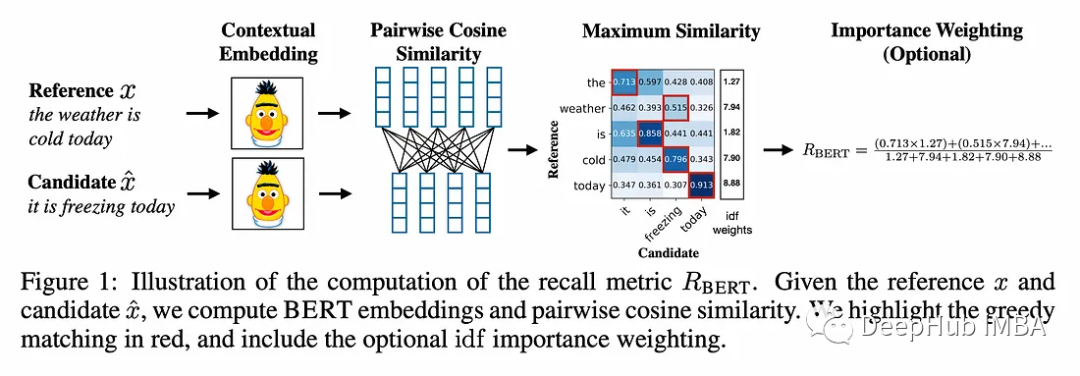
如何避免LLM的“幻觉”(Hallucination)
生成式大语言模型(LLM)可以针对各种用户的 prompt 生成高度流畅的回复。然而,大模型倾向于产生幻觉或做出非事实陈述,这可能会损害用户的信任。



