
在2022年11月OpenAI的ChatGPT发布之后,大型语言模型(llm)变得非常受欢迎。从那时起,这些语言模型的使用得到了爆炸式的发展,这在一定程度上得益于HuggingFace的Transformer库和PyTorch等库。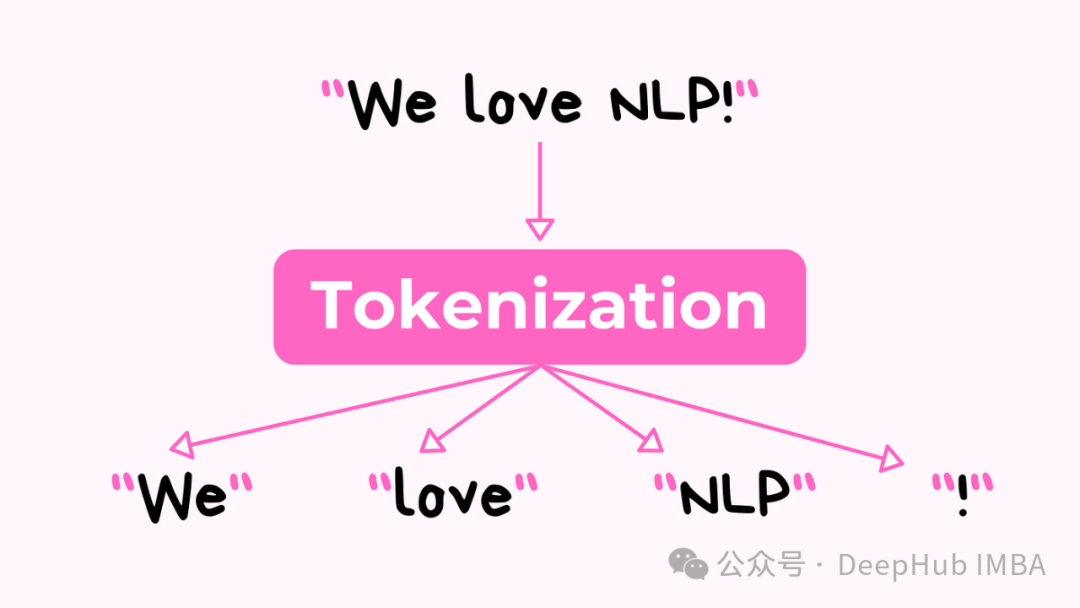
计算机要处理语言,首先需要将文本转换成数字形式。这个过程由一个称为标记化 Tokenization。
标记化分为2个过程
1、将输入文本划分为token
标记器首先获取文本并将其分成更小的部分,可以是单词、单词的部分或单个字符。这些较小的文本片段被称为标记。Stanford NLP Group[2]将标记更严格地定义为:
在某些特定的文档中,作为一个有用的语义处理单元组合在一起的字符序列实例。
2、为每个标记分配一个ID
标记器将文本划分为标记后,可以为每个标记分配一个称为标记ID的整数。例如,单词cat被赋值为15,因此输入文本中的每个cat标记都用数字15表示。用数字表示替换文本标记的过程称为编码。类似地将已编码的记号转换回文本的过程称为解码。
使用单个数字表示记号有其缺点,因此要进一步处理这些编码以创建词嵌入,这个不在本文的范围内,我们后面介绍。
标记方法
将文本划分为标记的主要方法有三种:
1、基于单词:
基于单词的标记化是三种标记化方法中最简单的一种。标记器将通过拆分每个空格字符(有时称为“基于空白的标记化”)或通过类似的规则集(如基于标点的标记化)将句子分成单词[12]。
例如,这个句子:
Cats are great, but dogs are better!
通过空格可以拆分为:
['Cats', 'are', 'great,', 'but', 'dogs', 'are', 'better!']
通过分隔标点和可以拆分为:
['Cats', 'are', 'great', ',', 'but', 'dogs', 'are', 'better', '!']
这里可以看到,用于确定分割的规则非常重要。空格方法可以更好地提供潜在的稀有标记!,而通过标点割则使两个不太罕见的标记更加突出!这里要说明下不要完全去掉标点符号,因为它们可以承载非常特殊的含义。’就是一个例子,它可以区分单词的复数形式和所有格形式。例如,“book’s”指的是一本书的某些属性,而“books”指的是许多书。
生成标记后,每个标记都会可以分配一个编号。下一次生成标记器已经看到的标记时,可以简单地为该标记分配为该单词指定的数字。例如,如果在上面的句子中,标记great被赋值为1,那么great的所有后续实例也将被赋值为1[3]。
优缺点:
基于单词的方法生成的标记包含高度的信息,因为每个标记都包含语义和上下文信息。但是这种方法最大的缺点之一是非常相似的单词被视为完全独立的标记。例如,cat和cats之间的联系将是不存在的,因此它们将被视为单独的单词。这在包含许多单词的大规模应用程序中成为一个问题,因为模型词汇表中可能出现的标记数量(模型所看到的标记总数)可能会变得非常大。英语大约有17万个单词,就会导致所谓的词汇爆炸问题。这方面的一个例子是TransformerXL标记器,它使用基于空白的分割。这导致词汇量超过25万[4]。
解决这个问题的一种方法是对模型可以学习的标记数量施加硬限制(例如10,000)。这将把10,000个最常见的标记之外的任何单词分类为词汇表外(OOV),并将标记值分配为UNKNOWN而不是数值(通常缩写为UNK)。在存在许多未知单词的情况下,这会导致性能下降,但如果数据中包含的大多是常见单词,这可能是一种合适的折衷方法。[5]
2、基于字符的分词器
基于字符的标记法根据每个字符拆分文本,包括:字母、数字和标点符号等特殊字符。这大大减少了词汇量的大小,英语可以用大约256个标记来表示,而不是基于单词的方法所需的170,000多个[5]。即使是东亚语言,如汉语和日语,其词汇量也会显著减少,尽管它们的书写系统中包含数千个独特的字符。
在基于字符的标记器中,以下句子:
Cats are great, but dogs are better!
会被拆分成:
['C', 'a', 't', 's', ' ', 'a', 'r', 'e', ' ', 'g', 'r', 'e', 'a', 't', ',', ' ', 'b', 'u', 't', ' ', 'd', 'o', 'g', 's', ' ', 'a', 'r', 'e', ' ', 'b', 'e', 't', 't', 'e', 'r', '!'`]
优缺点:
与基于单词的方法相比,基于字符的方法的词汇表大小要小得多,而且词汇表外的标记也要少得多。它可以对拼写错误的单词进行标记(尽管与单词的正确形式不同)。
但是这种方法也有一些缺点。使用基于字符的方法生成的单个标记中存储的信息非常少。这是因为与基于单词的方法中的标记不同,没有捕获语义或上下文含义(特别是在使用基于字母的书写系统的语言中,如英语)。这种方法限制了可以输入语言模型的标记化输入的大小,因为需要许多数字来编码输入文本。
3、基于子词的分词器
基于子词的标记化可以实现基于词和基于字符的方法的优点,同时最大限度地减少它们的缺点。基于子词的方法采取了折中的方案,将单词中的文本分开,创建具有语义意义的标记,即使它们不是完整的单词。例如,符号ing和ed虽然本身不是单词,但它们具有语法意义。
这种方法产生的词汇表大小小于基于单词的方法,但大于基于字符的方法。对于每个标记中存储的信息量也是如此,它也位于前两个方法生成的标记之间。
只拆分不常用的单词,可以使词形、复数形式等分解成它们的组成部分,同时保留符号之间的关系。例如,cat可能是数据集中非常常见的单词,但cats可能不太常见。所以cats将被分成cat和s,其中cats现在被赋予与其他所有cats标记相同的值,而s被赋予不同的值,这可以编码复数的含义。另一个例子是单词tokenization,它可以分为词根token和后缀ization。这种方法可以保持句法和语义的相似性[6]。由于这些原因,基于子词的标记器在今天的NLP模型中非常常用。
标准化和预标记化
标记化过程需要一些预处理和后处理步骤,这些步骤组成了标记化管道。其中标记化方法(基于子词,基于字符等)发生在模型步骤[7]中。
当使用Hugging Face的transformer库中的标记器时,标记化管道的所有步骤都会自动处理。整个管道由一个名为Tokenizer的对象执行。本节将深入研究大多数用户在处理NLP任务时不需要手动处理的代码的内部工作原理。还将介绍在标记器库中自定义基标记器类的步骤,这样可以在需要时为特定任务专门构建标记器。
1、规范化方法
规范化是在将文本拆分为标记之前清理文本的过程。这包括将每个字符转换为小写,从字符中删除重复,删除不必要的空白等步骤。例如,字符串ThÍs is áN examplise sÉnteNCE。不同的规范化程序将执行不同的步骤,
Hugging Face的Normalizers包包含几个基本的Normalizers,一般常用的有:
NFC:不转换大小写或移除口音
Lower:转换大小写,但不移除口音
BERT:转换大小写并移除口音
我们可以看看上面三种方法的对比:
from tokenizers.normalizers import NFC, Lowercase, BertNormalizer
# Text to normalize
text = 'ThÍs is áN ExaMPlé sÉnteNCE'
# Instantiate normalizer objects
NFCNorm = NFC()
LowercaseNorm = Lowercase()
BertNorm = BertNormalizer()
# Normalize the text
print(f'NFC: {NFCNorm.normalize_str(text)}')
print(f'Lower: {LowercaseNorm.normalize_str(text)}')
print(f'BERT: {BertNorm.normalize_str(text)}')
#NFC: ThÍs is áN ExaMPlé sÉnteNCE
#Lower: thís is án examplé séntence
#BERT: this is an example sentence
下面的示例可以看到,只有NFC删除了不必要的空白。
from transformers import FNetTokenizerFast, CamembertTokenizerFast, \
BertTokenizerFast
# Text to normalize
text = 'ThÍs is áN ExaMPlé sÉnteNCE'
# Instantiate tokenizers
FNetTokenizer = FNetTokenizerFast.from_pretrained('google/fnet-base')
CamembertTokenizer = CamembertTokenizerFast.from_pretrained('camembert-base')
BertTokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
# Normalize the text
print(f'FNet Output: \
{FNetTokenizer.backend_tokenizer.normalizer .normalize_str(text)}')
print(f'CamemBERT Output: \
{CamembertTokenizer.backend_tokenizer.normalizer.normalize_str(text)}')
print(f'BERT Output: \
{BertTokenizer.backend_tokenizer.normalizer.normalize_str(text)}')
#FNet Output: ThÍs is áN ExaMPlé sÉnteNCE
#CamemBERT Output: ThÍs is áN ExaMPlé sÉnteNCE
#BERT Output: this is an example sentence
2、预标记化
预标记化步骤是标记化原始文本的第一次分割。执行分割是为了给出的最终标记的上限。一个句子可以在预标记步骤中被分割成几个词,然后在模型步骤中,根据标记方法(例如基于子词的方法),将其中的一些词进一步分割。因此,预先标记的文本表示标记化后仍然可能保留的最大标记。
例如,一个句子可以根据每个空格拆分,每个空格加一些标点,或者每个空格加每个标点。
下面显示了基本的Whitespacesplit预标记器和稍微复杂一点的BertPreTokenizer之间的比较。pre_tokenizers包。空白预标记器的输出保留标点完整,并且仍然连接到邻近的单词。例如,includes:被视为单个单词。而BERT预标记器将标点符号视为单个单词[8]。
from tokenizers.pre_tokenizers import WhitespaceSplit, BertPreTokenizer
# Text to normalize
text = ("this sentence's content includes: characters, spaces, and " \
"punctuation.")
# Define helper function to display pre-tokenized output
def print_pretokenized_str(pre_tokens):
for pre_token in pre_tokens:
print(f'"{pre_token[0]}", ', end='')
# Instantiate pre-tokenizers
wss = WhitespaceSplit()
bpt = BertPreTokenizer()
# Pre-tokenize the text
print('Whitespace Pre-Tokenizer:')
print_pretokenized_str(wss.pre_tokenize_str(text))
#Whitespace Pre-Tokenizer:
#"this", "sentence's", "content", "includes:", "characters,", "spaces,",
#"and", "punctuation.",
print('\n\nBERT Pre-Tokenizer:')
print_pretokenized_str(bpt.pre_tokenize_str(text))
#BERT Pre-Tokenizer:
#"this", "sentence", "'", "s", "content", "includes", ":", "characters",
#",", "spaces", ",", "and", "punctuation", ".",
我们可以直接从常见的标记器(如GPT-2和ALBERT (A Lite BERT)标记器)调用预标记化方法。这些方法与上面所示的标准BERT预标记器略有不同,因为在分割标记时不会删除空格字符。它们被替换为表示空格所在位置的特殊字符。这样做的好处是,在进一步处理时可以忽略空格字符,但如果需要,可以检索原始句子。GPT-2模型使用Ġ字符,其特征是大写G上面有一个点。ALBERT模型使用下划线字符。
from transformers import AutoTokenizer
# Text to pre-tokenize
text = ("this sentence's content includes: characters, spaces, and " \
"punctuation.")
# Instatiate the pre-tokenizers
GPT2_PreTokenizer = AutoTokenizer.from_pretrained('gpt2').backend_tokenizer \
.pre_tokenizer
Albert_PreTokenizer = AutoTokenizer.from_pretrained('albert-base-v1') \
.backend_tokenizer.pre_tokenizer
# Pre-tokenize the text
print('GPT-2 Pre-Tokenizer:')
print_pretokenized_str(GPT2_PreTokenizer.pre_tokenize_str(text))
#GPT-2 Pre-Tokenizer:
#"this", "Ġsentence", "'s", "Ġcontent", "Ġincludes", ":", "Ġcharacters", ",",
#"Ġspaces", ",", "Ġand", "Ġpunctuation", ".",
print('\n\nALBERT Pre-Tokenizer:')
print_pretokenized_str(Albert_PreTokenizer.pre_tokenize_str(text))
#ALBERT Pre-Tokenizer:
#"▁this", "▁sentence's", "▁content", "▁includes:", "▁characters,", "▁spaces,",
#"▁and", "▁punctuation.",
下面显示了同一个示例句子上的BERT预标记步骤的结果,返回的对象是一个包含元组的Python列表。每个元组对应一个预标记,其中第一个元素是预标记字符串,第二个元素是一个元组,包含原始输入文本中字符串的开始和结束的索引。
from tokenizers.pre_tokenizers import WhitespaceSplit, BertPreTokenizer
# Text to pre-tokenize
text = ("this sentence's content includes: characters, spaces, and " \
"punctuation.")
# Instantiate pre-tokenizer
bpt = BertPreTokenizer()
# Pre-tokenize the text
bpt.pre_tokenize_str(example_sentence)
结果如下:
[('this', (0, 4)),
('sentence', (5, 13)),
("'", (13, 14)),
('s', (14, 15)),
('content', (16, 23)),
('includes', (24, 32)),
(':', (32, 33)),
('characters', (34, 44)),
(',', (44, 45)),
('spaces', (46, 52)),
(',', (52, 53)),
('and', (54, 57)),
('punctuation', (58, 69)),
('.', (69, 70))]
子词标记化方法
在完成了分词和预标记后,就可以开始合并标记了,对于transformer模型,有三种通常用于实现基于子词的方法。它们都使用略微不同的技术将不常用的单词分成更小的标记。
1、字节对编码 Byte Pair Encoding
字节对编码算法是一种常用的标记器,例如GPT和GPT-2模型(OpenAI), BART (Lewis等人)等[9-10]。它最初被设计为一种文本压缩算法,但人们发现它在语言模型的标记化任务中工作得非常好。BPE算法将一串文本分解为在参考语料库(用于训练标记化模型的文本)中频繁出现的子词单元[11]。BPE模型的训练方法如下:
a)构建语料库
输入文本被提供给规范化和预标记化模型,创建干净的单词列表。然后将这些单词交给BPE模型,模型确定每个单词的频率,并将该数字与单词一起存储在称为语料库的列表中。
b)构建词汇
然后语料库中的单词被分解成单个字符,并添加到一个称为词汇表的空列表中。该算法将在每次确定哪些字符对可以合并在一起时迭代地添加该词汇表。
c)找出字符对的频率
然后记录语料库中每个单词的字符对频率。例如,单词cat将具有ca, at和ts的字符对。所有单词都以这种方式进行检查,并贡献给全局频率计数器。在任何标记中找到的ca实例都会增加ca对的频率计数器。
d)创建合并规则
当每个字符对的频率已知时,最频繁的字符对被添加到词汇表中。词汇表现在由符号中的每个字母以及最常见的字符对组成。这也提供了一个模型可以使用的合并规则。例如,如果模型学习到ca是最常见的字符对,它已经学习到语料库中所有相邻的c和a实例可以合并以得到ca。现在可以将其作为单个字符ca处理其余步骤。
重复步骤c和d,找到更多合并规则,并向词汇表中添加更多字符对。这个过程一直持续到词汇表大小达到训练开始时指定的目标大小。
下面是BPE算法的Python实现
class TargetVocabularySizeError(Exception):
def __init__(self, message):
super().__init__(message)
class BPE:
'''An implementation of the Byte Pair Encoding tokenizer.'''
def calculate_frequency(self, words):
''' Calculate the frequency for each word in a list of words.
Take in a list of words stored as strings and return a list of
tuples where each tuple contains a string from the words list,
and an integer representing its frequency count in the list.
Args:
words (list): A list of words (strings) in any order.
Returns:
corpus (list[tuple(str, int)]): A list of tuples where the
first element is a string of a word in the words list, and
the second element is an integer representing the frequency
of the word in the list.
'''
freq_dict = dict()
for word in words:
if word not in freq_dict:
freq_dict[word] = 1
else:
freq_dict[word] += 1
corpus = [(word, freq_dict[word]) for word in freq_dict.keys()]
return corpus
def create_merge_rule(self, corpus):
''' Create a merge rule and add it to the self.merge_rules list.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
None
'''
pair_frequencies = self.find_pair_frequencies(corpus)
most_frequent_pair = max(pair_frequencies, key=pair_frequencies.get)
self.merge_rules.append(most_frequent_pair.split(','))
self.vocabulary.append(most_frequent_pair)
def create_vocabulary(self, words):
''' Create a list of every unique character in a list of words.
Args:
words (list): A list of strings containing the words of the
input text.
Returns:
vocabulary (list): A list of every unique character in the list
of input words.
'''
vocabulary = list(set(''.join(words)))
return vocabulary
def find_pair_frequencies(self, corpus):
''' Find the frequency of each character pair in the corpus.
Loop through the corpus and calculate the frequency of each pair
of adjacent characters across every word. Return a dictionary of
each character pair as the keys and the corresponding frequency as
the values.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
pair_freq_dict (dict): A dictionary where the keys are the
character pairs from the input corpus and the values are an
integer representing the frequency of the pair in the
corpus.
'''
pair_freq_dict = dict()
for word, word_freq in corpus:
for idx in range(len(word)-1):
char_pair = f'{word[idx]},{word[idx+1]}'
if char_pair not in pair_freq_dict:
pair_freq_dict[char_pair] = word_freq
else:
pair_freq_dict[char_pair] += word_freq
return pair_freq_dict
def get_merged_chars(self, char_1, char_2):
''' Merge the highest score pair and return to the self.merge method.
This method is abstracted so that the BPE class can be used as the
base class for other Tokenizers, and so the merging method can be
easily overwritten. For example, in the BPE algorithm the
characters can simply be concatenated and returned. However in the
WordPiece algorithm, the # symbols must first be stripped.
Args:
char_1 (str): The first character in the highest-scoring pair.
char_2 (str): The second character in the highest-scoring pair.
Returns:
merged_chars (str): Merged characters.
'''
merged_chars = char_1 + char_2
return merged_chars
def initialize_corpus(self, words):
''' Split each word into characters and count the word frequency.
Split each word in the input word list on every character. For each
word, store the split word in a list as the first element inside a
tuple. Store the frequency count of the word as an integer as the
second element of the tuple. Create a tuple for every word in this
fashion and store the tuples in a list called 'corpus', then return
then corpus list.
Args:
None
Returns:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters of the word),
and the second element is an integer representing the
frequency of the word in the list.
'''
corpus = self.calculate_frequency(words)
corpus = [([*word], freq) for (word, freq) in corpus]
return corpus
def merge(self, corpus):
''' Loop through the corpus and perform the latest merge rule.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
new_corpus (list[tuple(list, int)]): A modified version of the
input argument where the most recent merge rule has been
applied to merge the most frequent adjacent characters.
'''
merge_rule = self.merge_rules[-1]
new_corpus = []
for word, word_freq in corpus:
new_word = []
idx = 0
while idx < len(word):
# If a merge pattern has been found
if (len(word) != 1) and (word[idx] == merge_rule[0]) and\
(word[idx+1] == merge_rule[1]):
new_word.append(self.get_merged_chars(word[idx],word[idx+1]))
idx += 2
# If a merge patten has not been found
else:
new_word.append(word[idx])
idx += 1
new_corpus.append((new_word, word_freq))
return new_corpus
def train(self, words, target_vocab_size):
''' Train the model.
Args:
words (list[str]): A list of words to train the model on.
target_vocab_size (int): The number of words in the vocabulary
to be used as the stopping condition when training.
Returns:
None.
'''
self.words = words
self.target_vocab_size = target_vocab_size
self.corpus = self.initialize_corpus(self.words)
self.corpus_history = [self.corpus]
self.vocabulary = self.create_vocabulary(self.words)
self.vocabulary_size = len(self.vocabulary)
self.merge_rules = []
# Iteratively add vocabulary until reaching the target vocabulary size
if len(self.vocabulary) > self.target_vocab_size:
raise TargetVocabularySizeError(f'Error: Target vocabulary size \
must be greater than the initial vocabulary size \
({len(self.vocabulary)})')
else:
while len(self.vocabulary) < self.target_vocab_size:
try:
self.create_merge_rule(self.corpus)
self.corpus = self.merge(self.corpus)
self.corpus_history.append(self.corpus)
# If no further merging is possible
except ValueError:
print('Exiting: No further merging is possible')
break
def tokenize(self, text):
''' Take in some text and return a list of tokens for that text.
Args:
text (str): The text to be tokenized.
Returns:
tokens (list): The list of tokens created from the input text.
'''
tokens = [*text]
for merge_rule in self.merge_rules:
new_tokens = []
idx = 0
while idx < len(tokens):
# If a merge pattern has been found
if (len(tokens) != 1) and (tokens[idx] == merge_rule[0]) and \
(tokens[idx+1] == merge_rule[1]):
new_tokens.append(self.get_merged_chars(tokens[idx],
tokens[idx+1]))
idx += 2
# If a merge patten has not been found
else:
new_tokens.append(tokens[idx])
idx += 1
tokens = new_tokens
return tokens
使用的详细步骤:
# Training set
words = ['cat', 'cat', 'cat', 'cat', 'cat',
'cats', 'cats',
'eat', 'eat', 'eat', 'eat', 'eat', 'eat', 'eat', 'eat', 'eat', 'eat',
'eating', 'eating', 'eating',
'running', 'running',
'jumping',
'food', 'food', 'food', 'food', 'food', 'food']
# Instantiate the tokenizer
bpe = BPE()
bpe.train(words, 21)
# Print the corpus at each stage of the process, and the merge rule used
print(f'INITIAL CORPUS:\n{bpe.corpus_history[0]}\n')
for rule, corpus in list(zip(bpe.merge_rules, bpe.corpus_history[1:])):
print(f'NEW MERGE RULE: Combine "{rule[0]}" and "{rule[1]}"')
print(corpus, end='\n\n')
结果输出
INITIAL CORPUS:
[(['c', 'a', 't'], 5), (['c', 'a', 't', 's'], 2), (['e', 'a', 't'], 10),
(['e', 'a', 't', 'i', 'n', 'g'], 3), (['r', 'u', 'n', 'n', 'i', 'n', 'g'], 2),
(['j', 'u', 'm', 'p', 'i', 'n', 'g'], 1), (['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "a" and "t"
[(['c', 'at'], 5), (['c', 'at', 's'], 2), (['e', 'at'], 10),
(['e', 'at', 'i', 'n', 'g'], 3), (['r', 'u', 'n', 'n', 'i', 'n', 'g'], 2),
(['j', 'u', 'm', 'p', 'i', 'n', 'g'], 1), (['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "e" and "at"
[(['c', 'at'], 5), (['c', 'at', 's'], 2), (['eat'], 10),
(['eat', 'i', 'n', 'g'], 3), (['r', 'u', 'n', 'n', 'i', 'n', 'g'], 2),
(['j', 'u', 'm', 'p', 'i', 'n', 'g'], 1), (['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "c" and "at"
[(['cat'], 5), (['cat', 's'], 2), (['eat'], 10), (['eat', 'i', 'n', 'g'], 3),
(['r', 'u', 'n', 'n', 'i', 'n', 'g'], 2),
(['j', 'u', 'm', 'p', 'i', 'n', 'g'], 1), (['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "i" and "n"
[(['cat'], 5), (['cat', 's'], 2), (['eat'], 10), (['eat', 'in', 'g'], 3),
(['r', 'u', 'n', 'n', 'in', 'g'], 2), (['j', 'u', 'm', 'p', 'in', 'g'], 1),
(['f', 'o', 'o', 'd'], 6)]
NEW MERGE RULE: Combine "in" and "g"
[(['cat'], 5), (['cat', 's'], 2), (['eat'], 10), (['eat', 'ing'], 3),
(['r', 'u', 'n', 'n', 'ing'], 2), (['j', 'u', 'm', 'p', 'ing'], 1),
(['f', 'o', 'o', 'd'], 6)]
我们的代码只是为了学习流程,在实际应用中可以直接使用transformer库
BPE标记器只能识别出现在训练数据中的字符(characters)。如果出现不包含的词汇,会将这个字符转换为一个未知的字符。如果模型被用来标记真实数据。但是BPE错误处理没有添加未知的字符的标记,所以有的productionized模型是会产生崩溃。
但是GPT-2和RoBERTa中使用的BPE标记器没有这个问题。它们不是基于Unicode字符分析训练数据,而是分析字符的字节。这被称为字节级BPE Byte-Level BPE,它允许一个小的基本词汇表能够标记模型可能看到的所有字符。
2、WordPiece
WordPiece是Google为的BERT模型开发的一种标记化方法,并用于其衍生模型,如DistilBERT和MobileBERT。
WordPiece算法的全部细节尚未完全向公众公布,因此本文介绍的方法是基于Hugging Face[12]给出的解释。WordPiece算法类似于BPE,但使用不同的度量来确定合并规则。系统不会选择出现频率最高的字符对,而是为每对字符计算一个分数,分数最高的字符对决定合并哪些字符。WordPiece的训练如下:
a)构建语料库
输入文本被提供给规范化和预标记化模型,以创建干净的单词。
b)构建词汇
与BPE一样,语料库中的单词随后被分解为单个字符,并添加到称为词汇表的空列表中。但是这一次不是简单地存储每个单独的字符,而是使用两个#符号作为标记来确定该字符是在单词的开头还是在单词的中间/结尾找到的。例如,单词cat在BPE中会被分成['c', 'a', 't'],但在WordPiece中它看起来像['c', '##a', '##t']。单词开头的c和单词中间或结尾的##c将被区别对待。每次算法确定哪些字符对可以合并在一起时,都会迭代地向这个词汇表中添加内容。
c)计算每个相邻字符对的配对得分
与BPE模型不同,这次为每个字符对计算一个分数。识别语料库中每个相邻的字符对。'c##a', ##a##t等,并计算频率。每个字符单独出现的频率也是确定的。已知这些值后,可以根据以下公式计算配对得分:
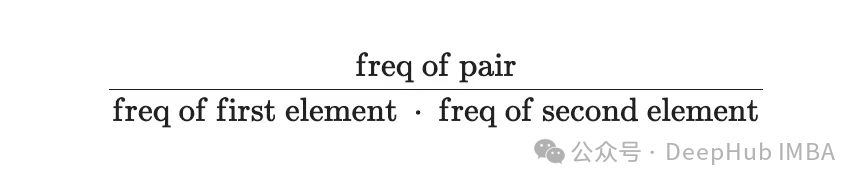
这个指标会给经常一起出现的字符分配更高的分数,但单独出现或与其他字符一起出现的频率较低。这是WordPiece和BPE的主要区别,因为BPE不考虑单个字符本身的总体频率。
d)创建合并规则
高分代表通常一起出现的字符对。也就是说,如果c##a的配对得分很高,那么c和a在语料库中经常一起出现,而不是单独出现。与BPE一样,合并规则是由得分最高的字符对决定的,但这次不是由频率决定得分,而是由字符对得分决定。
然后重复步骤c和d,找到更多合并规则,并向词汇表添加更多字符对。这个过程一直持续到词汇表大小达到训练开始时指定的目标大小。
简单代码示例如下:
class WordPiece(BPE):
def add_hashes(self, word):
''' Add # symbols to every character in a word except the first.
Take in a word as a string and add # symbols to every character
except the first. Return the result as a list where each element is
a character with # symbols in front, except the first character
which is just the plain character.
Args:
word (str): The word to add # symbols to.
Returns:
hashed_word (list): A list of the characters with # symbols
(except the first character which is just the plain
character).
'''
hashed_word = [word[0]]
for char in word[1:]:
hashed_word.append(f'##{char}')
return hashed_word
def create_merge_rule(self, corpus):
''' Create a merge rule and add it to the self.merge_rules list.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
None
'''
pair_frequencies = self.find_pair_frequencies(corpus)
char_frequencies = self.find_char_frequencies(corpus)
pair_scores = self.find_pair_scores(pair_frequencies, char_frequencies)
highest_scoring_pair = max(pair_scores, key=pair_scores.get)
self.merge_rules.append(highest_scoring_pair.split(','))
self.vocabulary.append(highest_scoring_pair)
def create_vocabulary(self, words):
''' Create a list of every unique character in a list of words.
Unlike the BPE algorithm where each character is stored normally,
here a distinction is made by characters that begin a word
(unmarked), and characters that are in the middle or end of a word
(marked with a '##'). For example, the word 'cat' will be split
into ['c', '##a', '##t'].
Args:
words (list): A list of strings containing the words of the
input text.
Returns:
vocabulary (list): A list of every unique character in the list
of input words, marked accordingly with ## to denote if the
character was featured in the middle/end of a word, instead
of as the first character of the word.
'''
vocabulary = set()
for word in words:
vocabulary.add(word[0])
for char in word[1:]:
vocabulary.add(f'##{char}')
# Convert to list so the vocabulary can be appended to later
vocabulary = list(vocabulary)
return vocabulary
def find_char_frequencies(self, corpus):
''' Find the frequency of each character in the corpus.
Loop through the corpus and calculate the frequency of characters.
Note that 'c' and '##c' are different characters, since the first
represents a 'c' at the start of a word, and '##c' represents a 'c'
in the middle/end of a word. Return a dictionary of each character
pair as the keys and the corresponding frequency as the values.
Args:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters (or subwords in
later iterations) of the word), and the second element is
an integer representing the frequency of the word in the
list.
Returns:
pair_freq_dict (dict): A dictionary where the keys are the
characters from the input corpus and the values are an
integer representing the frequency.
'''
char_frequencies = dict()
for word, word_freq in corpus:
for char in word:
if char in char_frequencies:
char_frequencies[char] += word_freq
else:
char_frequencies[char] = word_freq
return char_frequencies
def find_pair_scores(self, pair_frequencies, char_frequencies):
''' Find the pair score for each character pair in the corpus.
Loops through the pair_frequencies dictionary and calculate the
pair score for each pair of adjacent characters in the corpus.
Store the scores in a dictionary and return it.
Args:
pair_frequencies (dict): A dictionary where the keys are the
adjacent character pairs in the corpus and the values are
the frequencies of each pair.
char_frequencies (dict): A dictionary where the keys are the
characters in the corpus and the values are corresponding
frequencies.
Returns:
pair_scores (dict): A dictionary where the keys are the
adjacent character pairs in the input corpus and the values
are the corresponding pair score.
'''
pair_scores = dict()
for pair in pair_frequencies.keys():
char_1 = pair.split(',')[0]
char_2 = pair.split(',')[1]
denominator = (char_frequencies[char_1]*char_frequencies[char_2])
score = (pair_frequencies[pair]) / denominator
pair_scores[pair] = score
return pair_scores
def get_merged_chars(self, char_1, char_2):
''' Merge the highest score pair and return to the self.merge method.
Remove the # symbols as necessary and merge the highest scoring
pair then return the merged characters to the self.merge method.
Args:
char_1 (str): The first character in the highest-scoring pair.
char_2 (str): The second character in the highest-scoring pair.
Returns:
merged_chars (str): Merged characters.
'''
if char_2.startswith('##'):
merged_chars = char_1 + char_2[2:]
else:
merged_chars = char_1 + char_2
return merged_chars
def initialize_corpus(self, words):
''' Split each word into characters and count the word frequency.
Split each word in the input word list on every character. For each
word, store the split word in a list as the first element inside a
tuple. Store the frequency count of the word as an integer as the
second element of the tuple. Create a tuple for every word in this
fashion and store the tuples in a list called 'corpus', then return
then corpus list.
Args:
None.
Returns:
corpus (list[tuple(list, int)]): A list of tuples where the
first element is a list of a word in the words list (where
the elements are the individual characters of the word),
and the second element is an integer representing the
frequency of the word in the list.
'''
corpus = self.calculate_frequency(words)
corpus = [(self.add_hashes(word), freq) for (word, freq) in corpus]
return corpus
def tokenize(self, text):
''' Take in some text and return a list of tokens for that text.
Args:
text (str): The text to be tokenized.
Returns:
tokens (list): The list of tokens created from the input text.
'''
# Create cleaned vocabulary list without # and commas to check against
clean_vocabulary = [word.replace('#', '').replace(',', '')
for word in self.vocabulary]
clean_vocabulary.sort(key=lambda word: len(word))
clean_vocabulary = clean_vocabulary[::-1]
# Break down the text into the largest tokens first, then smallest
remaining_string = text
tokens = []
keep_checking = True
while keep_checking:
keep_checking = False
for vocab in clean_vocabulary:
if remaining_string.startswith(vocab):
tokens.append(vocab)
remaining_string = remaining_string[len(vocab):]
keep_checking = True
if len(remaining_string) > 0:
tokens.append(remaining_string)
return tokens
WordPiece与BPE算法学习的标记非常不同。可以清楚地看到,WordPiece更倾向于这样的组合:字符相互出现的频率比单独出现的频率更高,因此m和p会立即合并,因为它们只一起存在于数据集中,而不是单独存在。
wp = WordPiece()
wp.train(words, 30)
print(f'INITIAL CORPUS:\n{wp.corpus_history[0]}\n')
for rule, corpus in list(zip(wp.merge_rules, wp.corpus_history[1:])):
print(f'NEW MERGE RULE: Combine "{rule[0]}" and "{rule[1]}"')
print(corpus, end='\n\n')
结果
INITIAL CORPUS:
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['r', '##u', '##n', '##n', '##i', '##n', '##g'], 2),
(['j', '##u', '##m', '##p', '##i', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "##m" and "##p"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['r', '##u', '##n', '##n', '##i', '##n', '##g'], 2),
(['j', '##u', '##mp', '##i', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "r" and "##u"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['ru', '##n', '##n', '##i', '##n', '##g'], 2),
(['j', '##u', '##mp', '##i', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "j" and "##u"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['ru', '##n', '##n', '##i', '##n', '##g'], 2),
(['ju', '##mp', '##i', '##n', '##g'], 1), (['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "ju" and "##mp"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['ru', '##n', '##n', '##i', '##n', '##g'], 2),
(['jump', '##i', '##n', '##g'], 1), (['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "jump" and "##i"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##i', '##n', '##g'], 3),
(['ru', '##n', '##n', '##i', '##n', '##g'], 2), (['jumpi', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "##i" and "##n"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['ru', '##n', '##n', '##in', '##g'], 2), (['jumpi', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "ru" and "##n"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['run', '##n', '##in', '##g'], 2), (['jumpi', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "run" and "##n"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['runn', '##in', '##g'], 2), (['jumpi', '##n', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "jumpi" and "##n"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['runn', '##in', '##g'], 2), (['jumpin', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "runn" and "##in"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##in', '##g'], 3),
(['runnin', '##g'], 2), (['jumpin', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "##in" and "##g"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##ing'], 3),
(['runnin', '##g'], 2), (['jumpin', '##g'], 1),
(['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "runnin" and "##g"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##ing'], 3),
(['running'], 2), (['jumpin', '##g'], 1), (['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "jumpin" and "##g"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##ing'], 3),
(['running'], 2), (['jumping'], 1), (['f', '##o', '##o', '##d'], 6)]
NEW MERGE RULE: Combine "f" and "##o"
[(['c', '##a', '##t'], 5), (['c', '##a', '##t', '##s'], 2),
(['e', '##a', '##t'], 10), (['e', '##a', '##t', '##ing'], 3),
(['running'], 2), (['jumping'], 1), (['fo', '##o', '##d'], 6)]
尽管训练数据有限,但模型仍然设法学习了一些有用的标记,比如单词jumper开始。首先,字符串被分解成['jump','er'],因为jump是训练集中可以在单词开头找到的最大token。接下来,字符串er被分解成单个字符,因为模型还没有学会将字符e和r组合在一起。
print(wp.tokenize('jumper'))
#['jump', 'e', 'r']
3、Unigram
Unigram标记器采用与BPE和WordPiece不同的方法,从一个大词汇表开始,然后迭代地减少它,直到达到所需的大小。
Unigram模型使用统计方法,其中考虑句子中每个单词或字符的概率。这些列表中的每个元素都可以被认为是一个标记t,而一系列标记t1, t2,…,tn出现的概率由下式给出:
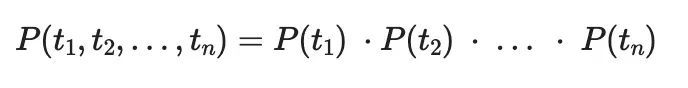
a)构建语料库
与往常一样,输入文本被提供给规范化和预标记化模型,以创建干净的单词
b)构建词汇
Unigram模型的词汇表大小一开始非常大,然后迭代地减少,直到达到所需的大小。要构造初始词汇表,请在语料库中找到所有可能的子字符串。例如,如果语料库中的第一个单词是cats,则子字符串['c', 'a', 't', 's', 'ca', 'at', 'ts', 'cat', 'ats']将被添加到词汇表中。
c)计算每个标记的概率
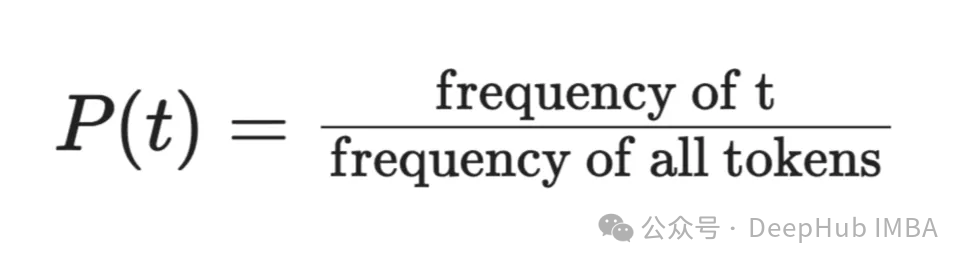
通过查找语料库中标记的出现次数,然后除以标记出现的总次数,可以近似地计算出标记出现的概率。
d)找出单词的所有可能的切分
假设训练语料库中的一个单词是cat。这可以通过以下方式进行细分:
['c', 'a', 't']
(“ca”、“t”)
[' c ', 'at']
(“cat”)
e)计算语料库中每个分割出现的近似概率
结合上面的方程式将给出每个系列标记的概率。
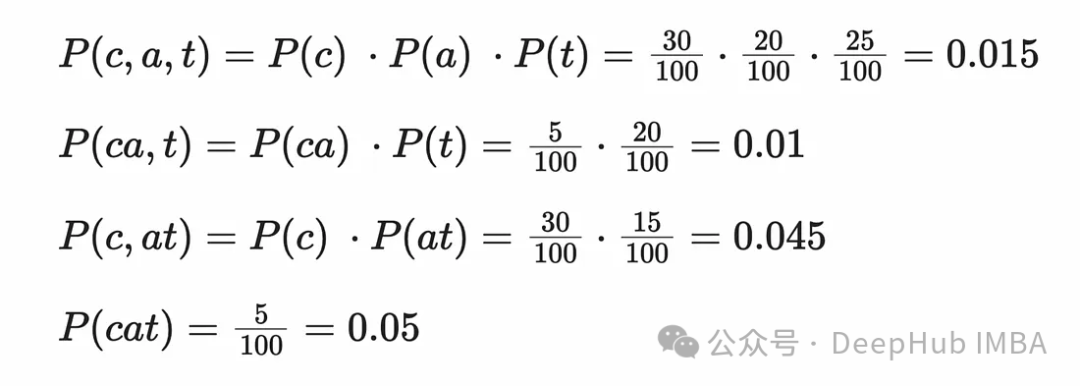
由于段['ca', 't']具有最高的概率得分,因此这是用于标记单词的段。单词cat将被标记为['ca', 't']。可以想象,对于像tokenization这样的较长的单词,拆分可能出现在整个单词的多个位置,例如['token', 'iza', tion]或['token', 'ization]。
f)计算损失
这里的损失是指模型的分数,如果从词汇表中删除一个重要的标记,则损失会大大增加,但如果删除一个不太重要的标记,则损失不会增加太多。通过计算每个标记被删除后在模型中的损失,可以找到词汇表中最没用的标记。这可以迭代地重复,直到词汇表大小减少到只剩下训练集语料库中最有用的标记。
这里的损失计算公式如下:
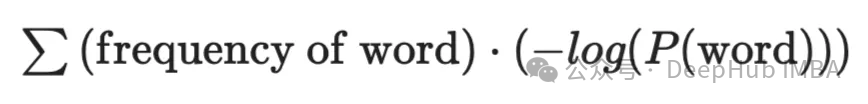
一旦删除了足够的字符,使词汇表减少到所需的大小,训练就完成了,模型就可以用于对单词进行标记。
比较BPE、WordPiece和Unigram
根据训练集和要标记的数据,一些标记器可能比其他标记器表现得更好。在为语言模型选择标记器时,最好使用用于特定用例的训练集进行实验,看看哪个能提供最好的结果。
在这三种方法中,BPE似乎是当前语言模型标记器中最流行的选择。尽管在这样一个瞬息万变的领域,这种变化在未来是很有可能发生的。但是其他子词标记器,如sentencepece,近年来越来越受欢迎[13]。
与BPE和Unigram相比,WordPiece似乎产生了更多的单词标记,但无论模型选择如何,随着词汇量的增加,所有标记器似乎都产生了更少的标记[14]。
标记器的选择取决于打算与模型一起使用的数据集。这里的建议是尝试BPE或sentencepece进行实验。
后处理
标记化的最后一步是后处理,如果有必要,可以对输出进行任何最终修改。BERT使用这一步骤添加了两种额外类型的标记:
[CLS] -这个标记代表“分类”,用于标记输入文本的开始。这在BERT中是必需的,因为它被训练的任务之一是分类(因此标记的名称)。即使不用于分类任务,该标记仍然是模型所期望的。
[SEP] -这个标记代表“分隔”,用于分隔输入中的句子。这对于BERT执行的许多任务都很有用,包括在同一提示符中同时处理多条指令[15]。
tokenizers库
tokenizers库使得使用预训练的tokenizer非常容易。只需导入Tokenizer类,调用from_pretrained方法,并传入要使用Tokenizer from的模型名称。模型列表见[16]。
from tokenizers import Tokenizer
tokenizer = Tokenizer.from_pretrained('bert-base-cased')
我们可以直接使用下面的实现
BertWordPieceTokenizer - The famous Bert tokenizer, using WordPiece
CharBPETokenizer - The original BPE
ByteLevelBPETokenizer - The byte level version of the BPE
SentencePieceBPETokenizer - A BPE implementation compatible with the one used by SentencePiece
h爱可以使用train方法进行自定义的训练。训练完成后使用save方法保存训练好的标记器,这样就不必再次执行训练。
# Import a tokenizer
from tokenizers import BertWordPieceTokenizer, CharBPETokenizer, \
ByteLevelBPETokenizer, SentencePieceBPETokenizer
# Instantiate the model
tokenizer = CharBPETokenizer()
# Train the model
tokenizer.train(['./path/to/files/1.txt', './path/to/files/2.txt'])
# Tokenize some text
encoded = tokenizer.encode('I can feel the magic, can you?')
# Save the model
tokenizer.save('./path/to/directory/my-bpe.tokenizer.json')
下面是一个完整的自定义训练的流程代码:
from tokenizers import Tokenizer, models, pre_tokenizers, decoders, trainers, \
processors
# Initialize a tokenizer
tokenizer = Tokenizer(models.BPE())
# Customize pre-tokenization and decoding
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=True)
tokenizer.decoder = decoders.ByteLevel()
tokenizer.post_processor = processors.ByteLevel(trim_offsets=True)
# And then train
trainer = trainers.BpeTrainer(
vocab_size=20000,
min_frequency=2,
initial_alphabet=pre_tokenizers.ByteLevel.alphabet()
)
tokenizer.train([
"./path/to/dataset/1.txt",
"./path/to/dataset/2.txt",
"./path/to/dataset/3.txt"
], trainer=trainer)
# And Save it
tokenizer.save("byte-level-bpe.tokenizer.json", pretty=True)
总结
标记化管道是语言模型的关键部分,在决定使用哪种类型的标记器时应该仔细考虑。虽然Hugging Face为了我们处理了这部分的工作,但是对标记方法的深刻理解对于微调模型和在不同数据集上获得的性能是非常重要的。
以下是本文引用
[1] Large Language Model image
[2] Token Definition
[3] Word Tokenizers
[4] TransformerXL Paper
[5] Tokenizers
[6] Word-Based, Subword, and Character-Based Tokenizers
[7] The Tokenization Pipeline
[8] Pre-tokenizers
[9] Language Models are Unsupervised Multitask Learners
[10] BART Model for Text Autocompletion in NLP
[11] Byte Pair Encoding
[12] WordPiece Tokenization
[13] Two minutes NLP — A Taxonomy of Tokenization Methods
[14] Subword Tokenizer Comparison
[15] How BERT Leverage Attention Mechanism and Transformer to Learn Word Contextual Relations
[16] List of Pre-trained Models
[17] Hugging Face Tokenizers Library
[18] Pre-Tokenization Documentation