
 在快速发展的人工智能领域,自然语言处理已成为研究人员和开发人员关注的焦点。作为这一领域显著进步的证明,近年来出现了几种开创性的语言模型,突破了机器能够理解和生成的界限。在本文中,我们将深入研究大规模语言模型的最新进展,探讨每个模型引入的增强功能、它们的功能和潜在的应用程序。
在快速发展的人工智能领域,自然语言处理已成为研究人员和开发人员关注的焦点。作为这一领域显著进步的证明,近年来出现了几种开创性的语言模型,突破了机器能够理解和生成的界限。在本文中,我们将深入研究大规模语言模型的最新进展,探讨每个模型引入的增强功能、它们的功能和潜在的应用程序。
我们将从2018年的一个开创性的BERT模型开始,并以今年的最新突破结束,如Meta AI的LLaMA和OpenAI的GPT-4。如果您想跳过,以下是我们介绍的语言模型:
- BERT by Google
- GPT-3 by OpenAI
- LaMDA by Google
- PaLM by Google
- LLaMA by Meta AI
- GPT-4 by OpenAI
如果这些深入的教育内容对您有用,您可以订阅我们的人工智能研究邮件列表,以便在我们发布新材料时得到提醒
2024年最重要的大型语言模型
1.谷歌的BERT
摘要
2018年,谷歌人工智能团队推出了一种新的自然语言处理(NLP)尖端模型——BERT,即变形金刚的双向编码器表示。它的设计使模型能够考虑每个单词左右两侧的上下文。虽然概念上很简单,但BERT在11项NLP任务上获得了最先进的结果,包括问答、命名实体识别和其他与一般语言理解有关的任务。该模型标志着NLP的一个新时代,语言模型的预训练成为一种新标准。
目标是什么?
为了消除早期语言模型的局限性,特别是在预训练的表示是单向的方面,这限制了可用于预训练的架构的选择,并限制了微调方法。
- 例如,OpenAI的GPT v1使用了从左到右的架构,其中每个令牌只关注Transformer的自关注层中的先前令牌。
- 这种设置对于句子级任务来说是次优的,对于令牌级任务尤其有害,因为在令牌级任务中,结合双方的上下文很重要。
如何解决这个问题?
- 通过随机屏蔽一定比例的输入令牌来训练深度双向模型,从而避免单词可以间接“看到自己”的循环。
- 此外,通过构建一个简单的二元分类任务来预测句子B是否紧跟在句子a之后,从而使BERT能够更好地理解句子之间的关系,从而预训练句子关系模型。
- 用大量数据(33亿个单词语料库)训练一个大模型(24个Transformer块,1024个隐藏,340M个参数)。
结果是什么?
推进11项NLP任务的最先进技术,包括:
- GLUE得分为80.4%,比之前的最佳成绩提高了7.6%;
- 在SQuAD 1.1上实现了93.2%的准确率,并比人类性能高出2%。
- 提出了一个预先训练的模型,该模型不需要任何实质性的架构修改即可应用于特定的NLP任务。
在哪里可以了解更多关于这项研究的信息?
- Research paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Blog post: Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing by Google AI
从哪里可以获得实现代码?
- Google Research has released an official Github repository with Tensorflow code and pre-trained models for BERT.
- PyTorch implementation of BERT is also available on GitHub.
2. GPT-3 by OpenAI
摘要
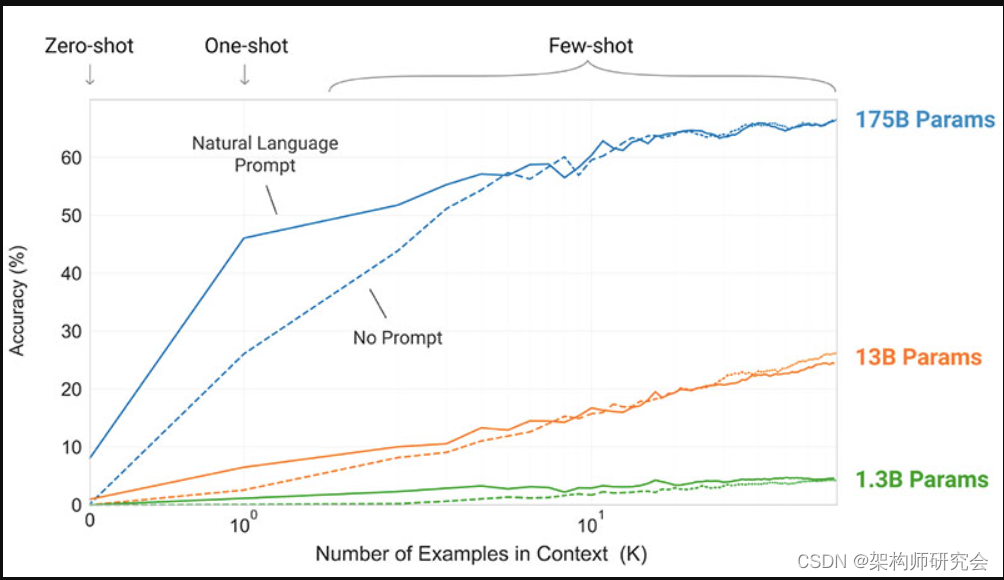
OpenAI团队引入了GPT-3,作为为每个新的语言任务提供标记数据集的替代方案。他们建议,扩大语言模型的规模可以提高与任务无关的少镜头性能。为了测试这一建议,他们训练了一个175B参数的自回归语言模型,称为GPT-3,并评估了它在二十多个NLP任务上的性能。在少快照学习、一次快照学习和零样本学习下的评估表明,GPT-3取得了可喜的结果,甚至偶尔优于精细调整模型取得的最新结果
目标是什么?
- 当每个新的语言任务都需要一个标记的数据集时,为现有问题提出一个替代解决方案。
如何解决这个问题?
- 研究人员建议扩大语言模型的规模,以提高与任务无关的少镜头表现
- GPT-3模型使用与GPT-2相同的模型和架构,包括修改初始化、预规范化和可逆标记化。
- 然而,与GPT-2相比,它在转换器的层中使用交替的密集和局部带状稀疏注意力模式,就像在稀疏转换器中一样。
 结果是什么?
结果是什么?
- 没有微调的GPT-3模型在许多NLP任务上取得了有希望的结果,甚至偶尔会超过为该特定任务微调的最先进模型: - 在CoQA基准测试中,与微调SOTA获得的90.7 F1分数相比,零样本设置中的F1分数为81.5,单射设置中的F184.0,少射设置中为85.0。- 在TriviaQA基准测试中,零样本设置的准确率为64.3%,一射设置的准确度为68.0%,少射设置的精确度为71.2%,超过了最新技术(68%)3.2%。- 在LAMBADA数据集上,零样本设置的准确率为76.2%,一次性设置为72.5%,少量快照设置为86.4%,超过当前技术水平(68%)18%。
- 根据人类评估,175B参数GPT-3模型生成的新闻文章很难与真实的区分开来(准确率略高于约52%的概率水平)
- 尽管GPT-3表现出色,但人工智能界对它的评价褒贬不一: - “GPT-3的炒作太过分了。它给人留下了深刻印象(感谢大家的赞美!),但它仍然有严重的弱点,有时还会犯非常愚蠢的错误。人工智能将改变世界,但GPT-3只是一个很早的一瞥。我们还有很多事情要弄清楚。”——OpenAI首席执行官兼联合创始人Sam Altman。- Gradio首席执行官兼创始人Abubakar Abid表示:“我感到震惊的是,从GPT-3中生成与暴力……或被杀无关的关于穆斯林的文本是多么困难。”。- “不。GPT-3从根本上不了解它所谈论的世界。进一步增加语料库将使它能够产生更可信的模仿,但不能解决它对世界根本缺乏理解的问题。GPT-4的演示仍然需要人类采摘樱桃。”——Robust.ai首席执行官兼创始人Gary Marcus。- “将GPT3的惊人性能外推到未来,表明生命、宇宙和一切的答案只有4.398万亿个参数。”——图灵奖得主杰弗里·辛顿。
在哪里可以了解更多关于这项研究的信息?
- Research paper: Language Models are Few-Shot Learners
从哪里可以获得实现代码?
- The code itself is not available, but some dataset statistics together with unconditional, unfiltered 2048-token samples from GPT-3 are released on GitHub.
3. LaMDA by Google
摘要
对话应用程序语言模型(LaMDA)是通过微调一组专门为对话设计的基于Transformer的神经语言模型而创建的。这些模型最多有137B个参数,并经过训练使用外部知识来源。LaMDA开发人员心中有三个关键目标——质量、安全和基础。结果表明,微调可以缩小与人类水平的质量差距,但该模型在安全性和基础性方面的性能仍低于人类水平
谷歌的Bard最近作为ChatGPT的替代品发布,由LaMDA提供动力。尽管巴德经常被贴上无聊的标签,但这可以被视为谷歌致力于优先考虑安全的证据,即使在谷歌和微软为在生成人工智能领域建立主导地位而展开的激烈竞争中也是如此。
目标是什么?
- 为开放域对话应用程序建立一个模型,在该模型中,对话代理能够以合理、特定于上下文、基于可靠来源和道德的响应来谈论任何主题。
如何解决这个问题?
- LaMDA基于Transformer,这是谷歌研究公司于2017年发明并开源的一种神经网络架构。 - 与包括BERT和GPT-3在内的其他大型语言模型一样,LaMDA在TB的文本数据上进行训练,以学习单词之间的关系,然后预测接下来可能出现的单词- 然而,与大多数语言模型不同的是,LaMDA接受了对话训练,以了解开放式对话与其他形式语言之间的细微差别。
- 该模型也经过了微调,以提高其反应的敏感性、安全性和特异性。虽然像“那很好”和“我不知道”这样的短语在许多对话场景中都有意义,但它们不太可能导致有趣和引人入胜的对话。 - LaMDA生成器首先生成几个候选响应,这些响应都是根据它们的安全性、合理性、特异性和趣味性来评分的。筛选出安全性得分较低的响应,然后选择排名靠前的结果作为响应。
 结果是什么?
结果是什么?
- 大量实验表明,LaMDA可以参与各种主题的开放式对话。
- 一系列定性评估证实,该模型的反应往往是明智、具体、有趣的,并基于可靠的外部来源,但仍有改进的空间。
- 尽管迄今为止取得了所有进展,但作者认识到,该模型仍有许多局限性,可能导致产生不适当甚至有害的反应。
在哪里可以了解更多关于这项研究的信息?
- Research paper: LaMDA: Language Models for Dialog Applications
- Blog posts by the Google Research team: - LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything- LaMDA: our breakthrough conversation technology- Understanding the world through language
从哪里可以获得实现代码?
- An open-source PyTorch implementation for the pre-training architecture of LaMDA is available on GitHub.
4. PaLM by Google
摘要
路径语言模型(Pathways Language Model,PaLM)是一个5400亿参数的基于Transformer的语言模型。PaLM使用Pathways在6144个TPU v4芯片上进行训练,Pathways是一种新的ML系统,用于跨多个TPU吊舱进行高效训练。该模型展示了在少量学习中扩展的好处,在数百种语言理解和生成基准上取得了最先进的结果。PaLM在多步推理任务上优于经过微调的最先进模型,并在BIG基准测试上超过了平均人工性能。
目标是什么?
- 提高对大型语言模型的缩放如何影响少镜头学习的理解。
如何解决这个问题?
- 关键思想是利用Pathways系统扩展5400亿参数语言模型的训练: - 该团队在两个Cloud TPU v4 Pod之间使用Pod级别的数据并行性,同时在每个Pod中使用标准数据和模型并行性。- 他们能够将训练扩展到6144个TPU v4芯片,这是迄今为止用于训练的最大的基于TPU的系统配置。- 该模型实现了57.8%的硬件FLOP利用率的训练效率,正如作者所说,这是该规模的大型语言模型迄今为止实现的最高训练效率
- PaLM模型的训练数据包括英语和多语言数据集的组合,其中包含高质量的网络文档、书籍、维基百科、对话和GitHub代码。
 结果是什么?
结果是什么?
- 大量实验表明,随着团队规模扩大到他们最大的模型,模型性能急剧提高。
- PaLM 540B在多项非常困难的任务上取得了突破性的性能: - 语言理解和生成。所引入的模型在29项任务中的28项上超过了先前大型模型的少镜头表现,这些任务包括问答任务、完形填空和句子完成任务、上下文阅读理解任务、常识推理任务、SuperGLUE任务等。PaLM在BIG工作台任务中的表现表明,它可以区分因果关系,并在适当的上下文中理解概念组合。- 推理。在8次提示下,PaLM解决了GSM8K中58%的问题,GSM8K是数千道具有挑战性的小学级数学问题的基准,优于之前通过微调GPT-3 175B模型获得的55%的高分。PaLM还展示了在需要多步骤逻辑推理、世界知识和深入语言理解的复杂组合的情况下生成明确解释的能力。- 代码生成。PaLM的性能与经过微调的Codex 12B不相上下,同时使用的Python代码减少了50倍用于训练,这证实了大型语言模型更有效地转移了对其他编程语言和自然语言数据的学习。
在哪里可以了解更多关于这项研究的信息?
- An unofficial PyTorch implementation of the specific Transformer architecture from the PaLM research paper is available on GitHub. It will not scale and is published for educational purposes only.
5. LLaMA by Meta AI
摘要
Meta AI团队声称,在更多代币上训练的较小模型更容易重新训练和微调特定的产品应用程序。因此,他们引入了LLaMA(大型语言模型元AI),这是一组具有7B到65B参数的基础语言模型。LLaMA 33B和65B在1.4万亿代币上进行了训练,而最小的模型LLaMA 7B在1万亿代币上训练。他们只使用公开可用的数据集,而不依赖于专有或受限数据。该团队还实施了关键的体系结构增强和训练速度优化技术。因此,LLaMA-13B的性能优于GPT-3,比GPT-3小了10多倍,LLaMA-65B表现出与PaLM-540B的竞争性能。
目标是什么?
- 证明仅在可公开访问的数据集上训练性能最佳的模型的可行性,而不依赖于专有或受限的数据源。
- 为研究社区提供更小、更具性能的模型,从而使那些无法访问大量基础设施的人能够研究大型语言模型。
如何解决这个问题?
- 为了训练LLaMA模型,研究人员只使用了公开的、与开源兼容的数据。
- 他们还对标准Transformer架构进行了一些改进: - 采用GPT-3方法,通过对每个变压器子层的输入进行归一化,而不是对输出进行归一化,增强了训练的稳定性。- 受PaLM模型的启发,研究人员用SwiGLU激活函数取代了ReLU非线性,以提高性能。- 受Su等人(2021)的启发,他们取消了绝对位置嵌入,而是在网络的每一层引入了旋转位置嵌入(RoPE)。
- 最后,Meta AI团队通过以下方式提高了模型的训练速度: - 通过不存储注意力权重或计算掩蔽键/查询分数,使用高效的因果多头注意力实现。- 使用检查点来最大限度地减少反向过程中重新计算的激活。- 重叠激活的计算和GPU之间通过网络的通信(由于所有减少操作)。
结果是什么?
尽管LLaMA-13B比GPT-3小了10倍多,但它还是超过了GPT-3,而LLaMA-65B在对抗PaLM-540B时保持了自己的优势。
在哪里可以了解更多关于这项研究的信息?
- Research paper: LLaMA: Open and Efficient Foundation Language Models
- Blog post: Introducing LLaMA: A foundational, 65-billion-parameter large language model by Meta AI
从哪里可以获得实现代码?
- Meta AI provides access to LLaMA to academic researchers, individuals associated with government, civil society, academic institutions, and global industry research labs on an individual case evaluation basis. To apply, go to the following GitHub repository.
6. GPT-4 by OpenAI
摘要
GPT-4是一个大规模的多模式模型,它接受图像和文本输入并生成文本输出。出于竞争和安全考虑,有关模型架构和培训的具体细节被保留。在性能方面,GPT-4在传统基准测试上超越了以前的语言模型,并在用户意图理解和安全属性方面显示出显著的改进。该模型在各种考试中也达到了人类水平的表现,包括在模拟的统一律师考试中获得最高10%的分数。
目标是什么?
- 开发一个可以接受图像和文本输入并产生文本输出的大规模多模式模型
- 开发基础设施和优化方法,使其在大范围内具有可预测的性能。
如何解决这个问题?
- 由于竞争环境和安全影响,OpenAI决定保留架构、模型大小、硬件、训练计算、数据集构建和训练方法的细节。
- 他们披露: - GPT-4是一个基于Transformer的模型,经过预训练可以预测文档中的下一个令牌。- 它利用了公开可用的数据和第三方许可的数据。- 使用来自人类反馈的强化学习(RLHF)对模型进行了微调。
 结果是什么?
结果是什么?
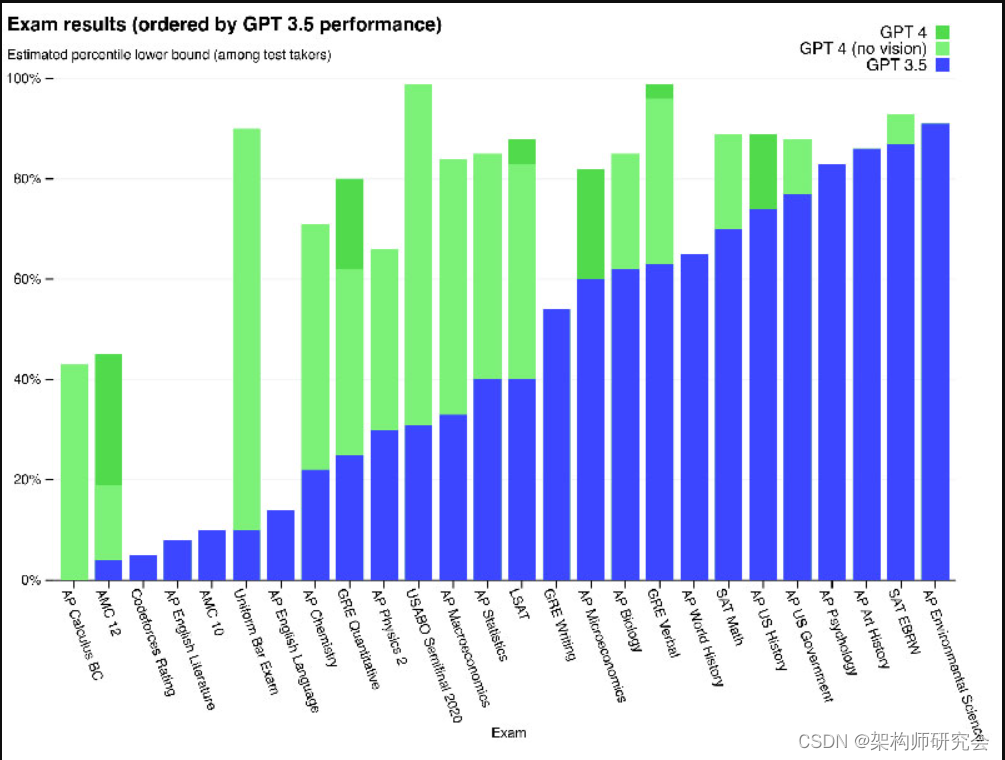
- GPT-4在大多数专业和学术考试中都取得了人类水平的成绩,尤其是在模拟的统一律师考试中得分前10%。
- 预训练的基础GPT-4模型在传统NLP基准测试上优于现有语言模型和先前最先进的系统,而无需特定于基准测试的手工制作或额外的训练协议。
- 在ChatGPT和OpenAI API的5214个提示中,GPT-4的响应比GPT-3.5的响应更受欢迎,这表明GPT-4在遵循用户意图方面有了实质性的改进。
- 与GPT-3.5相比,GPT-4的安全性能有了显著改善,对不允许的内容请求的响应减少了82%,对敏感请求(如医疗建议和自残)策略的遵守率增加了29%。
在哪里可以了解更多关于这项研究的信息?
- Research paper: GPT-4 Technical Report by OpenAI
- Blog post: GPT-4 by OpenAI
从哪里可以获得实现代码?
- Code implementation of GPT-4 is not available.
大型语言模型在现实世界中的应用
近年来最重要的人工智能研究突破来自在巨大数据集上训练的大型人工智能模型。这些模型展示了令人印象深刻的性能,思考人工智能如何彻底改变整个行业,如客户服务、营销、电子商务、医疗保健、软件开发、新闻业和许多其他行业,令人着迷。
大型语言模型在现实世界中有许多应用。GPT-4列出了以下内容:
- 聊天机器人和虚拟助理的自然语言理解和生成。
- 语言之间的机器翻译。
- 文章、报告或其他文本文档的摘要。
- 市场研究或社交媒体监控的情绪分析。
- 用于营销、社交媒体或创意写作的内容生成。
- 用于客户支持或知识库的问答系统。
- 垃圾邮件过滤、主题分类或文档组织的文本分类。
- 个性化的语言学习和辅导工具。
- 代码生成和软件开发协助。
- 医疗、法律和技术文件分析和协助。
- 残疾人无障碍工具,如文本到语音和语音到文本转换。
- 语音识别和转录服务。
关注最近的人工智能突破并思考它们在现实世界中的潜在应用是非常令人兴奋的。然而,在现实生活中部署这些模型之前,我们需要解决相应的风险和限制,不幸的是,这些风险和限制非常重要。
风险和限制
如果你询问GPT-4的风险和局限性,它可能会为你提供一长串相关问题。在筛选了这个列表并添加了一些额外的注意事项后,我最终发现了现代大型语言模型所具有的以下一组关键风险和限制:
- 偏见和歧视:这些模型从大量的文本数据中学习,这些数据往往包含偏见和歧视性内容。因此,产生的产出可能会无意中使刻板印象、攻击性语言和基于性别、种族或宗教等因素的歧视永久化。
- 错误信息:大型语言模型可能生成事实上不正确、误导或过时的内容。虽然模型是在各种来源上训练的,但它们可能并不总是提供最准确或最新的信息。这种情况经常发生,因为模型优先生成语法正确或看起来连贯的输出,即使它们具有误导性。
- 缺乏理解:尽管这些模型似乎能理解人类语言,但它们主要通过识别训练数据中的模式和统计关联来运作。他们对自己生成的内容没有深入的理解,这有时会导致荒谬或无关的输出。
- 不恰当的内容:语言模型有时会生成冒犯性、有害或不恰当的属性。尽管人们努力将此类内容最小化,但由于训练数据的性质和模型无法辨别上下文或用户意图,这种情况仍有可能发生。
结论
大型语言模型无疑彻底改变了自然语言处理领域,并在提高各种角色和行业的生产力方面显示出巨大的潜力。他们能够生成类似人类的文本,自动化日常任务,并在创造性和分析过程中提供帮助,这使他们在当今快节奏、技术驱动的世界中成为不可或缺的工具。
然而,承认和理解这些强大模型的局限性和风险是至关重要的。偏见、错误信息和恶意使用的可能性等问题不容忽视。随着我们继续将这些人工智能驱动的技术融入我们的日常生活,在利用它们的能力和确保人类监督之间取得平衡至关重要,尤其是在敏感和高风险的情况下。
如果我们成功地负责任地采用生成性人工智能技术,我们将为人工智能和人类专业知识共同推动创新和为所有人创造一个更美好世界的未来铺平道路。
本文:【NLP】2023年改变人工智能的前六大NLP语言模型 | 开发者开聊
自我介绍
- 做一个简单介绍,酒研年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师研究会】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。全网同号【架构师研究会】

欢迎收藏 【全球IT瞭望】,【架构师酒馆】和【开发者开聊】.
版权归原作者 架构师研究会 所有, 如有侵权,请联系我们删除。