
最近在看arxiv的时候发现了一个有意思的框架:LLM-Blender,它可以使用Ensemble 的方法来对大语言模型进行集成。
官方介绍如下:LLM-Blender是一个集成框架,可以通过利用多个开源大型语言模型(llm)的不同优势来获得始终如一的卓越性能。
LLM集成
我们都知道集成学习是一种机器学习方法,旨在提高预测模型的性能和鲁棒性。它通过将多个不同的学习器(如决策树、神经网络等)结合成一个整体,来取得比单个学习器更好的预测效果。比如最常见的Kaggle比赛中就广泛的使用了这种方法。
那么大语言模型有必要进行集成吗
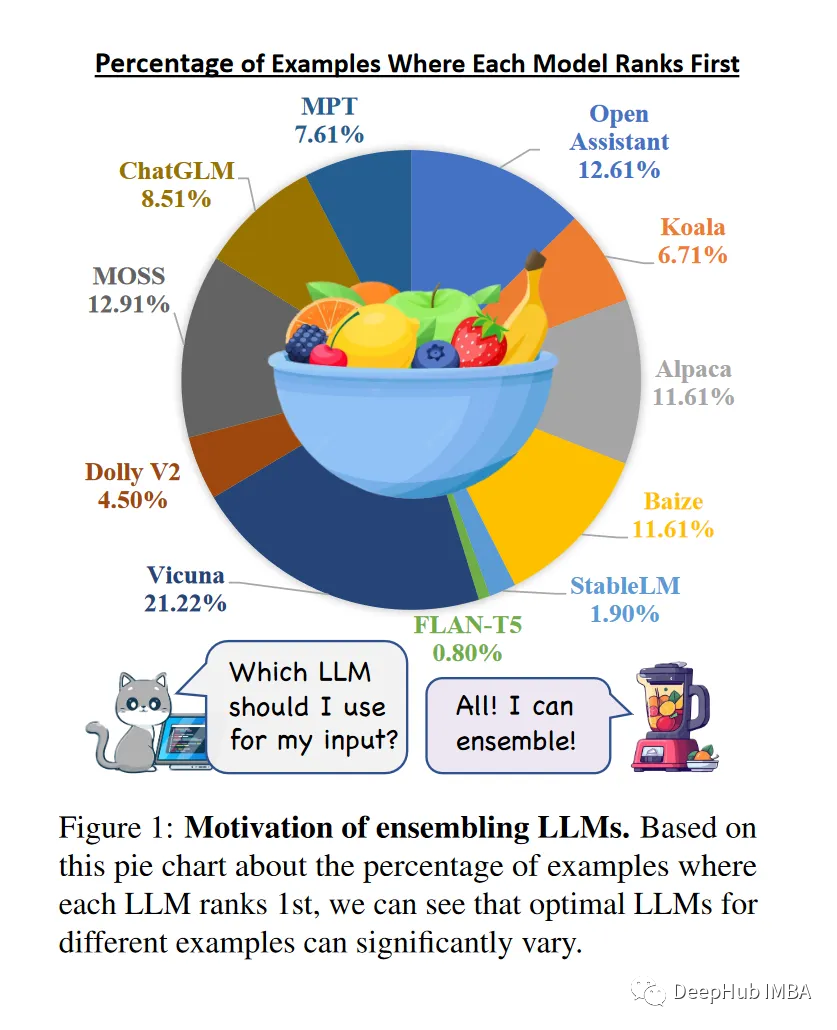
论文给出了以下观点:
由于数据、架构和超参数的变化,LLM表现出不同的优势和劣势,使它们互补。并且目前不存在一个开源LLM在所有例子中都占主导地位。可以集成LLM的输出(基于输入、任务和领域),以便在不同的示例中提供一致的卓越性能。结合他们独特的贡献;可以减轻个别LLM的偏差、误差和不确定性,从而使产出与人类偏好保持一致。
LLM-Blender
所以论文就给出了一个框架LLM-Blender
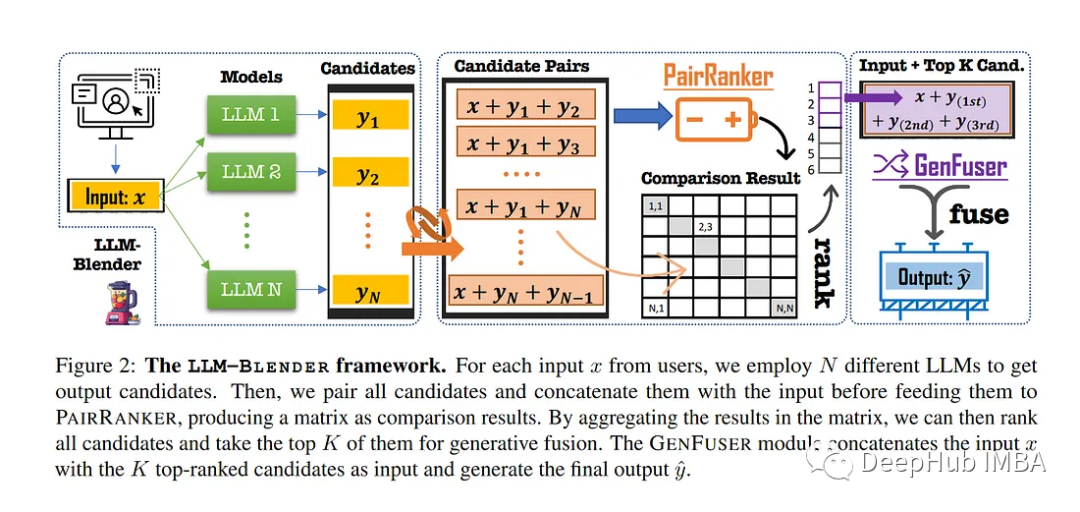
LLM-Blender有两个模块:PairRanker和GenFuser。PairRanker比较多个模型的输出,给出排名最高的输出。然后GenFuser将前几个排名靠前的输出融合在一起,生成最终输出。
1、PairRanker是如何工作的
PairRanker模块用于有效地识别候选模型输出之间的细微差异,并根据它们的质量对它们进行排名。收集N个模型的输出,并以总共N(N-1)/2种方式进行配对(从总共N个项目中选择2个项目的组合次数)。然后根据以下条件对结果进行评估:给定输入提示,哪个候选人的输出更好。
在推理过程中,计算一个包含表示两两比较结果的对数的矩阵。给定该矩阵确定并选择排名前k的输出用于GenFuser模块。
2、GenFuser是如何工作的
GenFuser模块使用PairRanker模块排名靠前的输出,为最终用户生成潜在的改进输出。该模块融合了排名前n位的结果中的前K位,并产生了改进的输出,利用他们的优势和减轻他们的弱点。
基准测试
论文介绍了一个名为mixdirective的新数据集,用于对llm在指令跟随任务中的集成模型进行基准测试。该数据集拥有来自Alpaca-GPT4、Dolly-15K、GPT4-ALL-LAION和ShareGPT的大规模指令示例集。有10万例用于训练,5万例用于验证,5万例用于测试。
使用N = 11个流行的开源LLM进行测试。候选的输出使用ChatGPT对所有候选对进行评估。对于每一对,ChatGPT被要求判断那个是更好的。
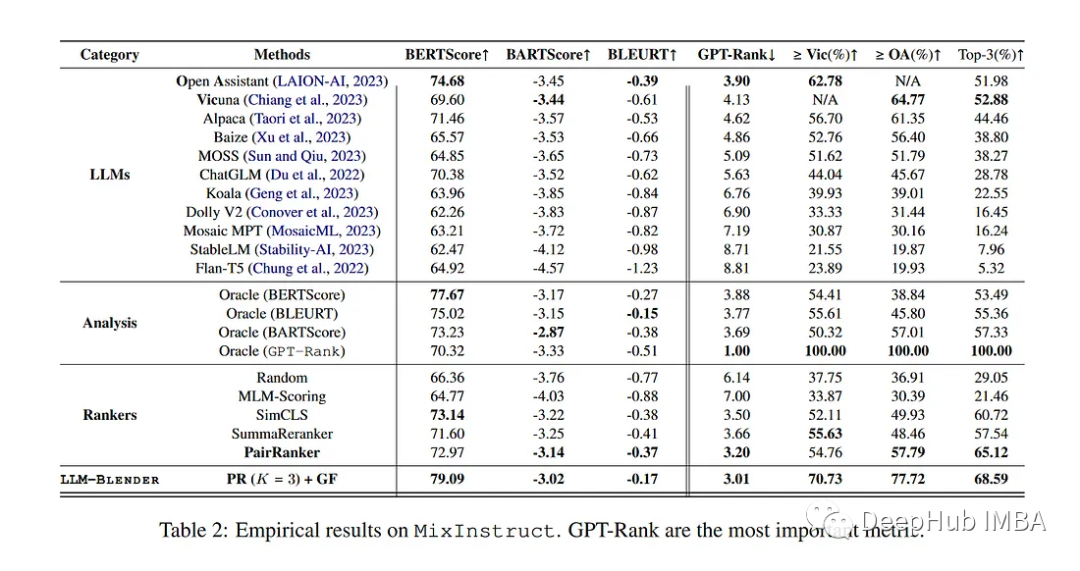
可以看到各个LLM有不同的优势和劣势。顶尖的LLM在测试中并不总是最优的。PairRanker优于其他LLM。LLM-Blender组合比其他任何单个模型更好。
限制
最主要的还是效率,因为对PairRanker中top-K输出进行排序的过程需要调用模型O(n²)次才能获得最佳性能。解决这个问题的一种方法是使用多轮气泡排序方法来减少所需的推断数量。另一种提高时间效率的方法是并行执行PairRanker的推理,因为它们是独立的,也就是多个模型同时推理。
目前论文使用的是在ChatGPT帮助下的自动评估。虽然自动评估是一个很好的选择,但人工评价可以提供更可靠、更全面的评价结果。
这时一个很有意思的项目,有兴趣的可以看看他的论文还有源代码: