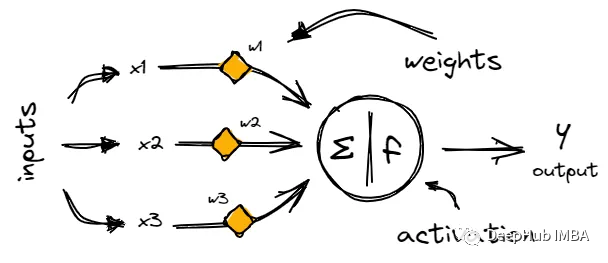
神经网络初学者的激活函数指南
如果你刚刚开始学习神经网络,激活函数的原理一开始可能很难理解。但是如果你想开发强大的神经网络,理解它们是很重要的。
学习笔记 | 多层感知机(MLP)、Transformer
多层感知机(MLP)、Transformer、Memory Bank
Segment Anything CV界的GPT—prompt-based里程碑式研究成果
Segment Anything由Meta AI发布,估计将成为计算机视觉界颠覆性成果,甚至可能重塑“计算机视觉”的概念。本文主要描述Segment AI的研究成果和简单应用,简明扼要提取有关论文的信息。
物理信息神经网络PINNs : Physics Informed Neural Networks 详解
本博客主要分为两部分:1、PINN模型论文解读2、PINN模型相关总结一、PINN模型论文解读1、摘要:基于物理信息的神经网络(Physics-informed Neural Network, 简称PINN),是一类用于解决有监督学习任务的神经网络,同时尊重由一般非线性偏微分方程描述的任何给定的物理
带你一文透彻学习【PyTorch深度学习实践】分篇——线性模型 & 梯度下降
鉴于PyTorch深度学习实践系列文章,篇幅较长,有粉丝朋友反馈说不便阅读。因此这里将会分篇发布,以便于大家阅读。本次发布的是 “基础 模型&算法 回顾”章节中的线性模型、Gradient Descent(梯度下降)。
【ChatGPT】ChatGPT-5 强到什么地步?
ChatGPT的能力,为什么停止训练ChatGPT
Swin Transformer原理详解篇
CV攻城狮入门VIT(vision transformer)之旅——近年超火的Transformer你再不了解就晚了!🍁🍁🍁CV攻城狮入门VIT(vision transformer)之旅——VIT原理详解篇🍁🍁🍁CV攻城狮入门VIT(vision transformer)之旅——VIT
超越ShuffleNet、MobileNet、MobileViT等模型的新backbone FasterNet
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。为了实现更快的网络,作者重新回顾了FLOPs的运算符,并证明了如此低的FLOPS主要是由于运算符的频繁内存访
深度学习中的卷积神经网络
2012年,AlexNet横空出世,卷积神经网络从此火遍大江南北。此后无数人开始研究,卷积神经网络终于在图像识别领域超过人类,那么卷积神经网络有什么神奇?下面我们来了解了解。
PyTorch之F.pad的使用与报错记录
这一函数用于实现对高维tensor的形状补齐操作。模式中,padding的数量不得超出原始tensor对应维度的大小。常见的错误主要是因为padding的数量超过了对应模式的要求。模式中,padding的数量必须小于对应维度的大小。对于padding并没有限制。
语义分割数据集:Cityscapes的使用
本文主要介绍Cityscapes在语义分割方向上的理解和使用。其中包括Cityscapes具体构建流程和使用方法。并提供了具体代码和pytorch dataset代码。
Notion AI vs ChatGPT vs New Bing 三款AI软件使用体验对比
三款AI问答软件均师出同门,全部基于OpenAI公司开发的GPT-3模型(其中Chatgpt使用的应是ChatGPT3.5版本的模型)。本篇文章从多个维度对比三款软件使用的优缺点,帮助大家了解它们的使用方式,以及应该如何更好地使用它们作为自己的辅助。
【深度学习】预训练语言模型-BERT
BERT是一种预训练语言模型(pre-trained language model, PLM),其全称是Bidirectional Encoder Representations from Transformers。
2023年4月的12篇AI论文推荐
GPT-4发布仅仅三周后,就已经随处可见了。本月的论文推荐除了GPT-4以外还包括、语言模型的应用、扩散模型、计算机视觉、视频生成、推荐系统和神经辐射场。
【论文笔记】—低光图像增强—Supervised—URetinex-Net—2022-CVPR
【题目】:URetinex-Net: Retinex-based Deep Unfolding Network for Low-light Image Enhancement 提出了一种基于Retinex的 deep unfolding network (URetinex-Net),它将一个优化问题
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
全网最详细的YOLOv5项目源码解读之训练部分train. py。全文近5万字!代码逐行注释,逐段讲解,小白入门必备!
摄像头标定--camera_calibration
用于指明标定板的内角点数量,如下图每个红圈的位置就是一个内角点,我所使用的GP290标点板有横向有11个内角点,纵向有8个内角点。当所有进度条都变成绿色后,CALIBRATE按钮由灰色变成深绿色,点击CALIBRATE,点击一下后,界面会卡住,此时不要做任何操作,直到运行标定程序的终端输出标定的结果
图解transformer | The Illustrated Transformer
写在最前边看transformer相关文章的时候发现很多人用了相同的图。直到我搜到作者的原文……于是决定翻译一下无删改的原文。翻译讲究:信、达、雅。要在保障意思准确的情况下传递作者的意图,并且尽量让文本优美。但是大家对我一个理工科少女的语言要求不要太高,本文只能保证在尽量通顺的情况下还原原文。作者博
PyTorch中的可视化工具
本文主要介绍Pytorch中的一些可视化工具
ChatGLM-6B 类似ChatGPT功能型对话大模型 部署实践
ChatGLM(alpha内测版:QAGLM)是一个初具问答和对话功能的中英双语模型,当前仅针对中文优化,多轮和逻辑能力相对有限,但其仍在持续迭代进化过程中,敬请期待模型涌现新能力。中英双语对话 GLM 模型:ChatGLM-6B,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量



