
最近的 AI 突破 DALLE和 Stable Diffusion有什么共同点?
它们都使用 CLIP 架构的组件。 因此,如果你想掌握这些模型是如何工作的,了解 CLIP 是先决条件。
此外,CLIP 已被用于在 Unsplash 上索引照片。
但是 CLIP 做了什么,为什么它是 AI 社区的里程碑?
让我们开始吧!
推荐:使用 NSDT场景设计器 快速搭建 3D场景
1、CLIP概述
CLIP 代表 Contrastive Language-Image Pretraining:
CLIP 是一个开源、多模态、零样本模型。 给定图像和文本描述,该模型可以预测与该图像最相关的文本描述,而无需针对特定任务进行优化。
让我们分解一下这个描述:
- 开源:该模型由 OpenAI 创建并开源。 稍后我们将看到有关如何使用它的编程教程。
- 多模态:多模态架构利用多个领域来学习特定任务。 CLIP 结合了自然语言处理和计算机视觉。
- 零样本:零样本学习是一种在未见过的标签上进行泛化的方法,无需专门训练来对它们进行分类。 例如,所有 ImageNet 模型都经过训练以识别 1000 个特定类别。 CLIP 不受此限制的约束。
- Contrastive Language:使用这种技术,CLIP 被训练为理解相似的表示应该靠近潜在空间,而不同的表示应该相距很远。 这将在稍后通过示例变得更加清楚。
下面是一些关于 CLIP 的有趣事实
- CLIP 使用数量惊人的 4 亿图像文本对进行训练。 相比之下,ImageNet 数据集包含 120 万张图像。
- 最终调优的 CLIP 模型在 256 个 V100 GPU 上训练了两周。 对于 AWS Sagemaker 上的按需培训,这至少要花费 20 万美元!
- 该模型使用 32,768 张图像的小批量进行训练。
2、CLIP可以做什么
让我们直观地展示 CLIP 做了什么。 我们稍后将更详细地展示一个编码示例。
首先,我们从 Unsplash 中选择一张免费图片:

接下来,我们为 CLIP 提供以下提示(Prompt):
- ‘a girl wearing a beanie’.
- ‘a girl wearing a hat’.
- ‘a boy wearing a beanie’.
- ‘a girl riding a bike’.
- ‘a dog’.
显然,第一个提示更好地描述了图像。
CLIP 通过分配归一化概率自动找到哪个文本提示最能描述图像。 我们得到: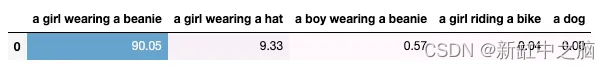
该模型成功地找到了最合适的图像描述。
此外,CLIP 可以准确识别它以前从未见过的类和对象。
如果你有一个大的图像数据集并且你想将这些图像标记为特定的类/类别/描述,CLIP 会自动为你做这件事!
接下来,我们将展示 CLIP 是如何工作的。
3、CLIP架构
CLIP 是一种深度学习模型,它使用了来自其他成功架构的新颖想法,并引入了一些自己的想法。
让我们从第一部分开始,对比预训练:
3.1 对比预训练
图 1 显示了对比预训练过程的概览。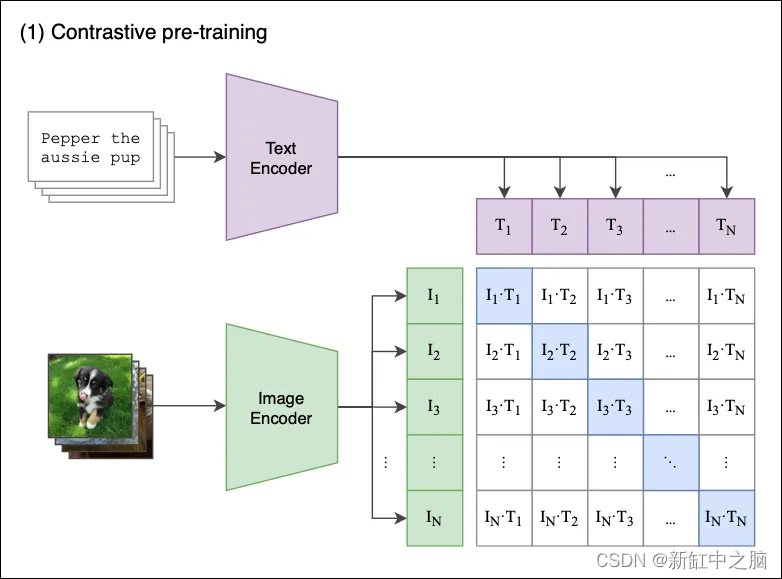
假设我们有一批 N 图像及其各自的描述配对,例如 <image1, text1>, <image2, text2>, <imageN, textN>。
对比预训练旨在联合训练生成图像嵌入 [I1, I2 … IN] 和文本嵌入[T1, T2 … TN] 的图像和文本编码器,其方式如下:
- 正确的嵌入对<I1,T1>, <I2,T2>(其中 i=j)的余弦相似度被最大化。
- 以对比方式,不相似对 <I1,T2>, <I1,T3>… <Ii,Tj>(其中 i≠j)的余弦相似性被最小化。
让我们逐步看发生了什么:
- 模型接收一批 N 个 对。
- 文本编码器是一个标准的 Transformer 模型,具有 GPT2 风格的修改。 图像编码器可以是 ResNet 或视觉Transformer。
- 对于批中的每个图像,图像编码器计算一个图像向量。 第一个图像对应于 I1 向量,第二个图像对应于 I2 ,依此类推。 每个向量的大小为 de,其中 de 是潜在维度的大小。 因此,这一步的输出是 一个 N X de 的矩阵。
- 类似地,文本描述被压缩到文本嵌入[T1, T2 … TN] 中,产生一个 N X de 的矩阵。
- 最后,我们将这些矩阵相乘并计算每个图像和文本描述之间的成对余弦相似度。 这会产生一个 N X N 矩阵,如上图所示。
- 目标是最大化沿对角线的余弦相似度——这些是正确的 对。 以对比方式,非对角线元素的相似性应最小化(例如,I1 图像由 T1 而不是 T2、T2、T3 等描述)。
一些额外的评论:
- 该模型使用对称交叉熵损失作为其优化目标。 这种类型的损失最小化了图像到文本的方向以及文本到图像的方向(请记住,我们的对比损失矩阵保持 <I1,T2> 和 <I2,T1> 余弦相似性)。
- 对比预训练并不是全新的。 它在以前的模型中引入,在 CLIP中做了适应性调整。
3.2 零样本分类
我们现在已经预训练了图像和文本编码器,我们已准备好进行零样本分类。
- 基线
首先,让我们提供一些背景信息。 Pre-Transformer时代如何实现few-shot分类?
很简单:
- 下载一个高性能的预训练 CNN,例如 ResNet,并用它进行特征提取,得到图像特征。
- 然后,将这些特征用作标准分类器(例如逻辑回归)的输入。 分类器以监督方式进行训练,其中图像标签用作目标变量(图 2)。
- 如果你选择 K-shot 学习,你在分类阶段的训练集应该只包含每个类的 K 个实例。 当 K<10 时,该任务称为少样本分类学习。 因此,对于 K=1,我们有一次性分类学习。 如果我们使用所有可用数据,这就是一个完全监督的模型(老式的方式)。
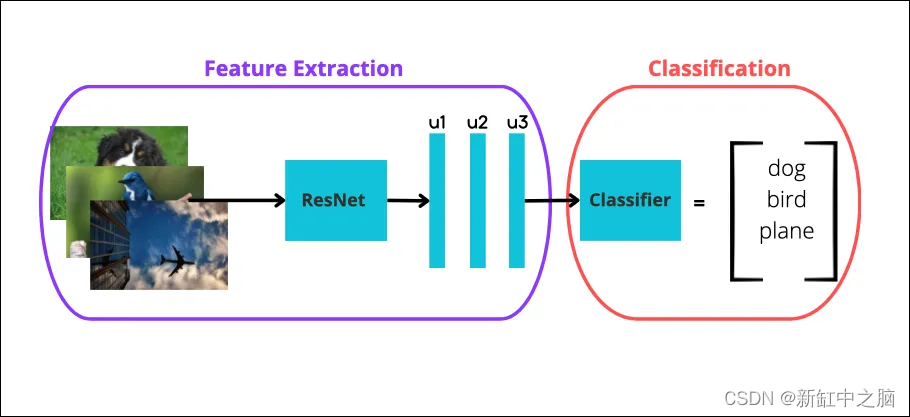
注意上面的关键字“监督”——分类器应该事先知道类标签。 使用与分类器配对的图像提取器也称为线性探针评估。
- CLIP的竞争优势
CLIP如何进行零样本分类的过程如图3所示:
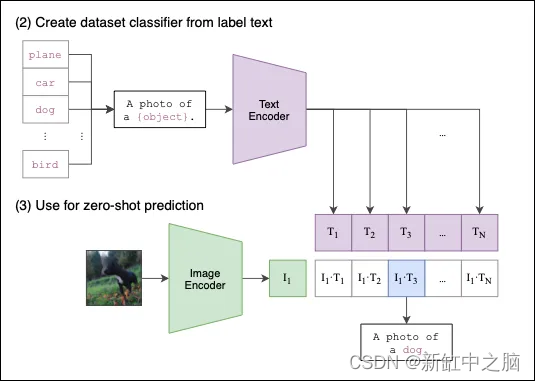
同样,这个过程很简单:
- 首先,我们提供一组文本描述,例如 a photo of a dog 或 a cat eating an ice-cream(我们认为能最好描述一个或多个图像的文本)。 这些文本描述被编码到文本嵌入中。
- 然后,我们对图像做同样的事情——图像被编码到图像嵌入中。
- 最后,CLIP 计算图像和文本嵌入之间的成对余弦相似度。 选择具有最高相似度的文本提示作为预测。
当然,我们可以输入多张图像。 CLIP 巧妙地缓存了输入文本嵌入,因此不必为其余输入图像重新计算它们。
就是这样! 我们现在已经总结了 CLIP 如何端到端地工作。
4、数据的问题
CLIP 使用 30 个公共数据集进行预训练。 用大量数据拟合大型语言模型很重要。
然而,很难找到具有配对图像-文本描述的稳健数据集。 大多数公共数据集,例如 CIFAR,都是只有一个单词标签的图像——这些标签是目标类别。 但是创建 CLIP 是为了使用完整的文本描述。
为了克服这种差异,作者没有排除这些数据集。 相反,他们进行了一些特征工程:将单个单词标签(例如 bird或 car)转换为句子: a photo of a dog或 a photo of bird。 在 Oxford-IIIT Pets 数据集上,作者使用了提示:A photo of a {label}, a type of pet。
有关预训练技术的更多信息,请查看原始论文 。
5、CLIP 对 AI 的影响
在文章开头,我们声称 CLIP 是 AI 社区的一个里程碑。
让我们看看为什么:
5.1 作为零样本分类器的卓越性能
CLIP 是一个零样本分类器,因此首先针对少样本学习模型测试 CLIP 是有意义的。
因此,作者针对由高质量预训练模型(例如 ResNet)之上的线性分类器组成的模型测试了 CLIP。
结果如图4所示:
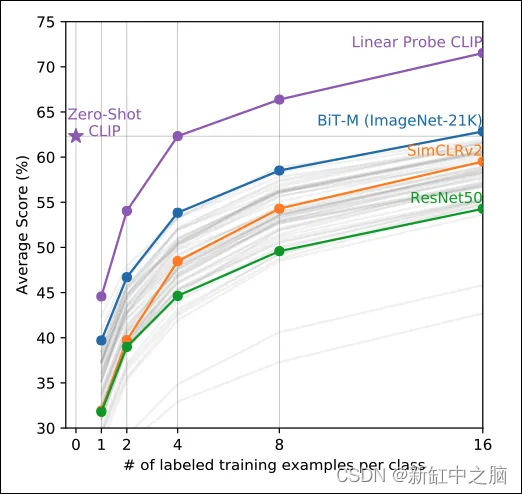
CLIP 明显优于其他分类器。
此外,CLIP 能够与 16-shot 线性分类器 BiT-M 的性能相媲美。 换句话说,BiT-M 的分类器必须在每个类别至少 16 个示例的数据集上进行训练,以匹配 CLIP 的分数——而 CLIP 无需微调即可获得相同的分数。
有趣的是,作者将 CLIP 评估为线性探针:他们仅使用 CLIP 的图像编码器来获取图像特征并将它们输入线性分类器——就像其他模型一样。 即使采用这种设置,CLIP 的小样本学习能力也非常出色。
5.2 对分布变化无与伦比的稳健性
分布漂移是一件大事,特别是对于生产中的机器学习系统。
注意:你可能将分布漂移视为概念漂移,尽管从技术上讲它们并不相同。
分布漂移(Distribution Shift) 是一种现象,当训练模型的数据随时间发生变化时会发生这种现象。 因此,随着时间的推移,模型的效率会降低,预测也会变得不准确。
事实上,分布漂移并不是意料之外的事情——它会发生。 问题是,如何及早发现这种现象,需要采取哪些措施来“重新校准”你的模型? 这并不容易解决,取决于许多因素。
幸运的是,关于人工智能的新研究正致力于创建能够适应分布变化的模型。
这就是作者将 CLIP 的稳健性用于测试的原因。 结果如图 5 所示:

关于 CLIP,这里有两点非常重要:
- CLIP 在 ImageNet 上实现了与 SOTA ResNet 模型相同的精度,尽管 CLIP 是零样本模型。
- 除了原始的 ImageNet 之外,我们还有类似的数据集作为分布偏移基准。 似乎 ResNet 正在努力处理这些数据集。 然而,CLIP 可以很好地处理未知图像——事实上,该模型在 ImageNet 的所有变体中保持相同的精度水平!
5.3 计算效率
在 GPT-2 之前,计算效率被认为是理所当然的(某种程度上)。
如今,在一个模型需要数周时间才能用数百个 8000 美元的 GPU 进行训练的时代,计算效率问题得到了更严重的解决。
CLIP 是一种对计算更友好的架构。 这一成功的部分原因是因为 CLIP 使用视觉Transformer作为默认的图像编码器组件。 结果如图6所示: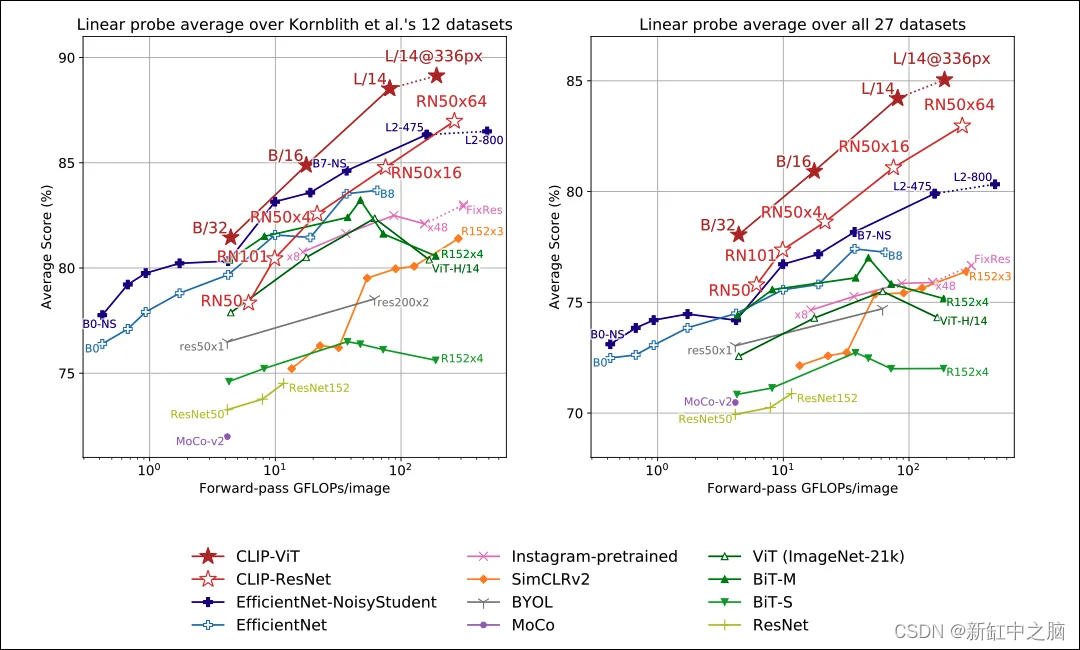
显然,与其他模型相比,CLIP 能够更好地利用硬件资源。 这也意味着在使用 AWS Sagemaker 等云服务进行培训时可以节省额外的费用。 此外,图 6 显示,与其他模型相比,CLIP 在硬件操作和准确度得分方面提供了更好的可扩展性。
仍然存在数据效率的问题。 作者表明,在零样本设置中,CLIP 比类似模型的数据效率更高。 但是,它们没有解决 CLIP 在预训练阶段的数据效率问题。 然而,在这方面可能没什么可做的,因为 CLIP 使用两种类型的 Transformers——而 Transformers 本质上是数据密集型模型。
5.4 研究兴趣增加
CLIP 的成功激发了人们对文本到图像模型的兴趣,并推广了对比预训练方法。
除了 DALLE 和稳定扩散之外,我们还可以使用 CLIP 作为 GAN 中的鉴别器。
此外,CLIP 的发布激发了类似的基于 CLIP 的出版物,这些出版物扩展了模型的功能,例如 DenseCLIP 和 CoCoOp。
此外,Microsoft 还发布了 X-CLIP,这是 CLIP 的最小扩展,用于视频语言理解。
额外信息:一个名为 paint.wtf 的类似 Pictionary 的应用程序使用 CLIP 对你的图画进行排名。 试一试——超级有趣!
6、如何使用 CLIP——编码示例
接下来,我们将展示如何使用 HugginFaces 库来使用 CLIP。
首先,让我们从 Unsplash 中选择 3 张图片。 我们之前使用了第一个:



我们将使用以下库:
import transformers
import datasets
import numpy as np
import pandas as pd
import torch
from PIL import Image
import requests
from transformers import CLIPTokenizerFast, CLIPProcessor, CLIPModel
接下来,我们加载 CLIP 模型的权重、分词器和图像处理器:
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "openai/clip-vit-base-patch32"
# we initialize a tokenizer, image processor, and the model itself
tokenizer = CLIPTokenizerFast.from_pretrained(model_id)
processor = CLIPProcessor.from_pretrained(model_id)
model = CLIPModel.from_pretrained(model_id).to(device)
此外,我们在 Python 中加载上述 Unsplash 图像:
urls=['https://images.unsplash.com/photo-1662955676669-c5d141718bfd?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=687&q=80',
'https://images.unsplash.com/photo-1552053831-71594a27632d?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=662&q=80',
'https://images.unsplash.com/photo-1530281700549-e82e7bf110d6?ixlib=rb-1.2.1&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=688&q=80']
images=[Image.open(requests.get(i, stream=True).raw) for i in urls]
最后,我们为 CLIP 提供了一些文本提示。
目标是让 CLIP 将 3 张 Unsplash 图片分类为特定的文字描述。 请注意,其中一个具有误导性——让我们看看是否可以混淆模型:
text_prompts=["a girl wearing a beanie", "a boy wearing a beanie", "a dog", "a dog at the beach"]
inputs = inputs = processor(text=text_prompts, images=images, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
pd.DataFrame(probs.detach().numpy()*100, columns=text_prompts, index=list(['image1','image2', 'image3'])).style.background_gradient(axis=None,low=0, high=0.91).format(precision=2)
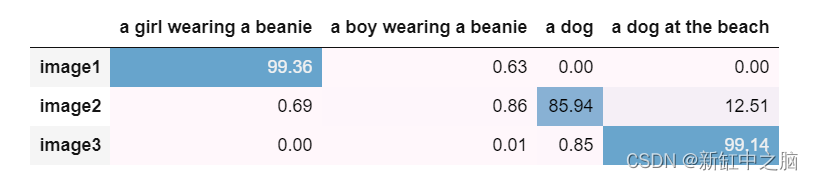
该模型成功地对所有 3 张图像进行了分类!
注意两点:
- CLIP 可以理解多个实体及其在每个图像中的动作。
- CLIP 为每个图像分配了最具体的描述。 例如,我们可以将第二张图片描述为“一只狗”和“海滩上的一只狗”。 然而,该模型正确地决定“狗”短语更好地描述了第二张图片,因为没有海滩。
随意尝试这个例子。 完整的例子在这里。将你的图像与文字描述结合使用,探索 CLIP 的工作原理。
7、CLIP局限性和未来的工作
虽然 CLIP 是一个革命性的模型,但仍有改进的空间。 作者指出了有可能取得进一步进展的领域。
- 准确度得分:CLIP 是最先进的零样本分类器,直接挑战特定任务的训练模型。
- CLIP 在 ImageNet 上与完全监督的 ResNet101 的准确性相匹配这一事实是惊人的。 然而,仍然有监督模型获得更高的分数。 作者强调,鉴于其惊人的可扩展性,CLIP 可能会获得更高的分数,但这需要大量的计算机资源。
- 多义性:作者指出 CLIP 存在多义性。 有时,由于缺乏上下文,模型无法区分某些单词的含义。 请记住,我们之前提到过某些图像仅使用类标签进行标记,而不使用全文提示。 作者提供了一个示例:在 Oxford-IIIT Pet 数据集中,“拳击手”一词指的是一种犬种,但其他图像将“拳击手”视为运动员。 在这里,罪魁祸首是数据的质量,而不是模型本身。
- 特定于任务的学习:虽然 CLIP 可以区分复杂的图像模式,但该模型在执行一些微不足道的任务时会失败。 例如,该模型难以处理手写数字识别任务(图 7)。 作者将这种类型的错误分类归因于训练数据集中缺少手写数字。

8、结束语
毫无疑问,CLIP 是 AI 社区的重要模型。
从本质上讲,CLIP 为彻底改变 AI 研究的新一代文本到图像模型铺平了道路。 当然,不要忘记这个模型是开源的。
最后但同样重要的是,还有很大的改进空间。 在整篇论文中,作者暗示 CLIP 的许多局限性是由于训练数据质量较低。
原文链接:OpenAI最有影响的模型 — BimAnt
版权归原作者 新缸中之脑 所有, 如有侵权,请联系我们删除。