【机器学习】yolov5训练结果分析
yolov5模型训练后的结果会保存到当前目录下的run文件夹下里面的train中下面对训练结果做出分析。
Transformer中的Q/K/V理解
详细解释了Transformer中的Q/K/V矩阵的作用和意义。
quality focal loss & distribute focal loss 解说(附代码)
quality focal loss
2022年顶会、顶刊SNN相关论文
2022年顶会、顶刊脉冲神经网络相关优秀论文收集
基础GAN实例(pytorch代码实现)
输出是长度为100的噪声(正态分布随机数)输出为(1,28,28)的图片linear1100---256linear2256--512linear3reshapenn.Tanh()#对于生成器,最后一个激活函数是tanh,值域-1到1)#定义前向传播#x表示长度为100的noise输入img=img
多目标跟踪MOT(Multiple Object Tracking)最全综述
多目标跟踪,一般简称为MOT(Multiple Object Tracking),也有一些文献称作MTT(Multiple Target Tracking)。在事先不知道目标数量的情况下,对视频中的行人、汽车、动物等多个目标进行检测并赋予ID进行轨迹跟踪。不同的目标拥有不同的ID,以便实现后续的轨迹
【前沿技术】文心一言 PK Chat Gpt
综上所述,文心一言和ChatGPT都是值得关注和研究的语言模型,它们在语言表达、适用场景和应用能力等方面都有自己的优缺点。在选择语言模型时,需要根据实际应用场。
智能优化算法:卷积优化算法-2023 附代码
将二维卷积运算引入智能优化算法的种群位置更新过程,提出一种新的智能优化算法,即卷积优化算法(Convolution Optimization Algorithm,COA)。该算法主要包括卷积搜索和解质量增强 2 种机制:在卷积搜索过程中,分别定义纵向卷积核、横向卷积核和区域卷积核,依次进行二维卷积运
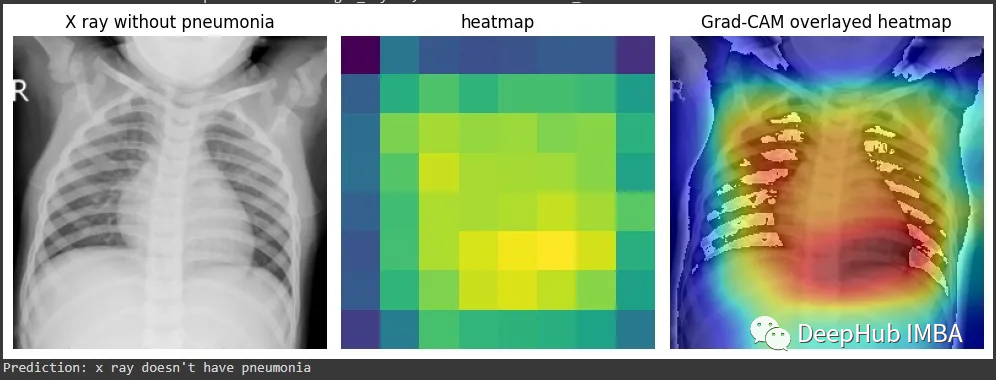
Grad-CAM的详细介绍和Pytorch代码实现
Grad-CAM (Gradient-weighted Class Activation Mapping) 是一种可视化深度神经网络中哪些部分对于预测结果贡献最大的技术。它能够定位到特定的图像区域,从而使得神经网络的决策过程更加可解释和可视化。
Amazon SageMaker:搭建企业级AI模型的完整解决方案
和现有的机器学习平台相比,Amazon SageMaker核心在于快速构建、训练和部署机器学习应用,非常适合和各个应用领域结合,快速提供搭建企业级AI模型的完整解决方案
基于Wav2Lip+GFPGAN的高清版AI主播
继上一篇的内容之后很多小伙伴反应一个问题就是生成的AI人物并不是很清晰,尤其是放到编辑器里会出现明显的痕迹,因此这次带来的了高清版的内容,如果不太了解这个项目实做什么的可以来先看一下效果。该项目暂时没有中文介绍,我这个应该是首发。基于Wav2Lip自制高清版,用自己形象做数字人清楚多了虽然说是自制但
【图像异常检测】 Anomalib
图像异常检测综述
目标检测算法——YOLOv5/YOLOv7改进之结合ASPP(空洞空间卷积池化金字塔)
目标检测算法——YOLOv5/YOLOv7改进之结合ASPP。ASPP对所给定的输入以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文。
【深度学习】——LSTM参数设置
LSTM的批大小可以根据训练数据集的大小和计算资源的限制来确定。一般而言,批大小,训练速度越快,但可能会导致过拟合和内存限制。批大小越小,训练速度越慢,但对于较大的数据集和内存限制较严格的情况下会更加稳定。在实践中,可以通过尝试不同的批大小来找到最优的批大小。一种常用的方法是开始使用较小的批大小,然
扩散模型与生成模型详解
详细介绍了扩散模型的原理及其使用
DenseNet代码复现+超详细注释(PyTorch)
DenseNet代码复现(PyTorch),每一行都有超详细注释,新手小白都能看懂,亲测可运行
涨点技巧:Detect系列---Yolov5/Yolov7加入ASFF特征金字塔融合方法,涨点明显
多尺度特征特别是特征金字塔FPN是解决目标检测中跨尺度目标的最常用有效的解决方法,特征金字塔融合方法ASFF与yolov5/yolov7结合可以有效涨点
ChatGPT的平替来了?一文总结 ChatGPT 的开源平替,你值得拥有
2023 年,聊天机器人领域似乎只剩下两个阵营:「OpenAI 的 ChatGPT」和「其他」。再加上前段时间 GPT-4 的发布,ChatGPT 也有了更强大的推理和多模态能力,OpenAI 几乎不可能将其开源。然而,表现欠佳的「其他」阵营却一直在做开源方面的努力。本文总结了目前业界开源且适合中文
GPT-4 介绍
本文根据openAI的2023年3月的《GPT-4 Technical Report 》翻译总结的。原文确实没有GPT-4 具体的模型结构,openAI向盈利组织、非公开方向发展了。也没透露硬件、训练成本、训练数据、训练方法等。不过也透露了一些思想,比如提出了根据模型小的时候,预测模型大的时候的表现
使用YOLOV5训练自己的数据集(以王者荣耀为例)
使用yolov5训练自己的数据集



