Pytorch优化器全总结(三)牛顿法、BFGS、L-BFGS 含代码
这篇文章是优化器系列的第三篇,主要介绍牛顿法、BFGS和L-BFGS,其中BFGS是拟牛顿法的一种,而L-BFGS是对BFGS的优化,那么事情还要从牛顿法开始说起。L-BFGS即Limited-memory BFGS。 L-BFGS的基本思想就是通过存储前m次迭代的少量数据来替代前一次的矩阵,从而大
详解Pytorch中的torch.nn.MSELoss函,包括对每个参数的分析!
详解Pytorch中的torch.nn.MSELoss函数,包括对每个参数的分析!
欠拟合的原因以及解决办法(深度学习)
之前这篇文章,我分析了一下深度学习中,模型过拟合的主要原因以及解决办法:过拟合的原因以及解决办法(深度学习)_大黄的博客-CSDN博客这篇文章中写一下深度学习中,模型欠拟合的原因以及一些常见的解决办法。也就是为什么我们设计的神经网络它不收敛?这里还是搬这张图出来,所谓欠拟合(也就是神经网络不收敛),
YOLOv5网络结构,训练策略详解
前面已经讲过了Yolov5模型目标检测和分类模型训练流程,这一篇讲解一下yolov5模型结构,数据增强,以及训练策略。
MAE详解
目录一、介绍二、网络结构1. encoder2. decoder3. LOSS三、实验全文参考:论文阅读笔记:Masked Autoencoders Are Scalable Vision Learners_塔_Tass的博客-CSDN博客masked autoencoders(MAE)是hekai
图像处理中常见的几种插值方法:最近邻插值、双线性插值、双三次插值(附Pytorch测试代码)
在学习可变形卷积时,因为学习到的位移量Δpn可能是小数,因此作者采用双线性插值算法确定卷积操作最终采样的位置。通过插值算法我们可以根据现有已知的数据估计未知位置的数据,并且可以利用这种方法对图像进行缩放、旋转以及几何校正等任务。此处我通过这篇文章学习总结常见的三种插值方法,包括最近邻插值、双线性插值
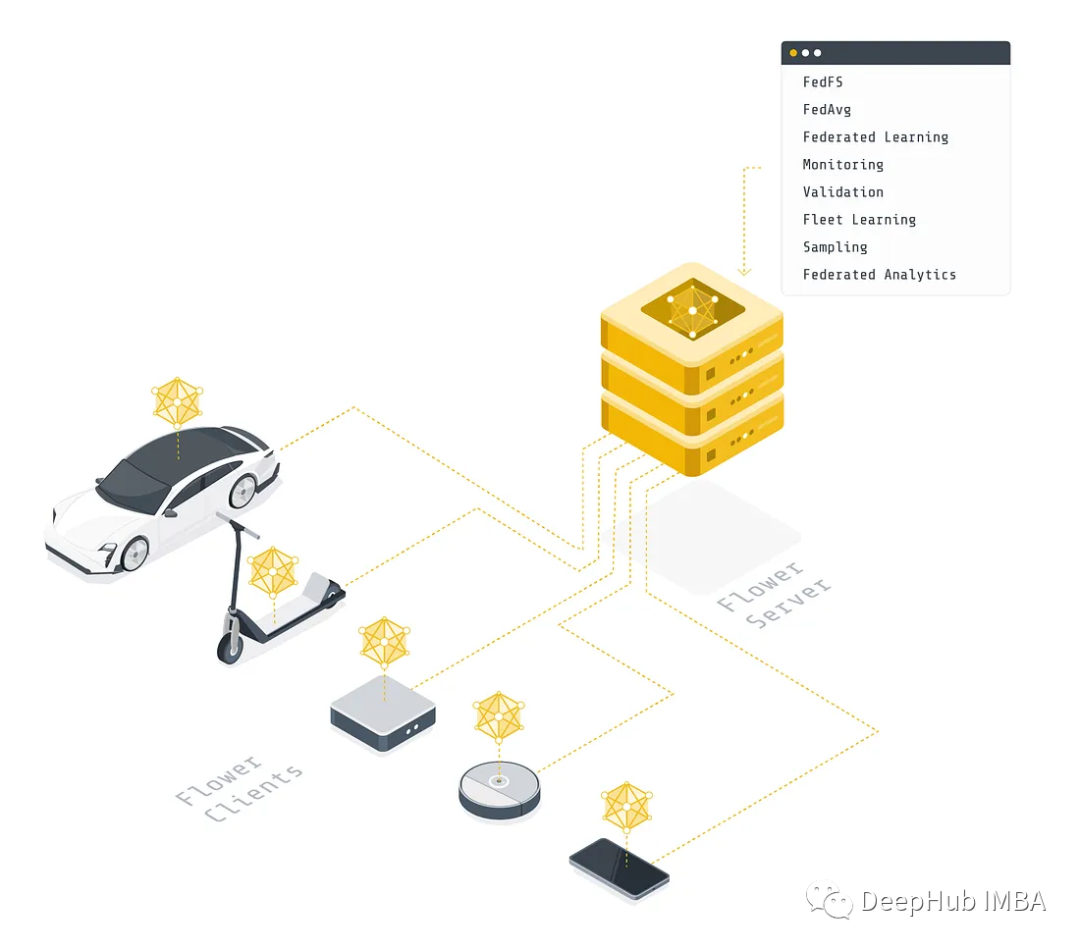
使用PyTorch和Flower 进行联邦学习
本文将介绍如何使用 Flower 构建现有机器学习工作的联邦学习版本。我们将使用 PyTorch 在 CIFAR-10 数据集上训练卷积神经网络,然后将展示如何修改训练代码以联邦的方式运行训练。
足够惊艳,使用Alpaca-Lora基于LLaMA(7B)二十分钟完成微调,效果比肩斯坦福羊驼
从上面可以看到,在一台8卡的A800服务器上面,基于Alpaca-Lora针对指令数据大概20分钟左右即可完成参数高效微调,相对于斯坦福羊驼训练速度显著提升。参考文档LLaMA:斯坦福-羊驼。
GAM注意力机制
GAM解析,使用Pytorch实现GAM attention
图像融合、Transformer、扩散模型
包大人说:“图像融合遇见Transformer,还是Transformer遇见图像融合?哪个更为贴切?”元芳回答:‘’都合适。‘’
【数据挖掘】期末复习题库集
【数据挖掘】期末复习题库集
【深度学习】——循环神经网络RNN及实例气温预测、单层lstm股票预测
密集连接网络和卷积神经网络都有主要的特点,那就是它们没有记忆。它们单独处理每个输入,在输入和输入之间没有保存任何状态。举个例子:当你在阅读一个句子的时候,你需要记住之前的内容,我们才能动态的了解这个句子想表达的含义。生物智能已渐进的方式处理信息,同时保存一个关于所处理内容的内部模型,此模型是根据过去
IDDPM官方gituhb项目--训练
IDDPM官方gituhb项目--训练
【YOLO】YOLOv8实操:环境配置/自定义数据集准备/模型训练/预测
yolov8实操
斯坦福大学开源Alpaca模型源码,性能与GPT-3.5相当比GPT4逊色,训练成本不到100美元(教程含源码)
GPT-3.5 (text-davinci-003)、ChatGPT、Claude 和 Bing Chat 等指令遵循模型现在被许多用户广泛使用,包括用于与工作相关的任务。然而,尽管它们越来越受欢迎,但这些模型仍然存在许多需要解决的缺陷。虚假信息、社会刻板印象和有毒语言是与这些模型相关的一些问题。为
Tiny ImageNet 数据集分享
Tiny Image Net 数据集分享
【使用Pytorch实现ResNet网络模型:ResNet50、ResNet101和ResNet152】
在深度学习和计算机视觉领域取得了一系列突破。尤其是随着非常深的卷积神经网络的引入,这些模型有助于在图像识别和图像分类等问题上取得最先进的结果。因此,多年来,深度学习架构变得越来越深(添加更多层)以解决越来越复杂的任务,这也有助于提高分类和识别任务的性能并使其变得健壮。但是当我们继续向神经网络添加更多
基于深度学习的车型识别系统(Python+清新界面+数据集)
基于深度学习的车型识别系统用于识别不同类型的车辆,应用YOLO V5算法根据不同尺寸大小区分和检测车辆,并统计各类型数量以辅助智能交通管理。本文详细介绍车型识别系统,在介绍算法原理的同时,给出Python的实现代码以及PyQt的UI界面。在界面中可以选择各种图片、视频进行检测识别;可对图像中存在的多
图像修复(Image Inpainting)任务中常用的掩码数据集
目前图像修复任务中最长用的数据集是来自于 Liu 等人2018年发布的论文, 该论文中提出用部分卷积解决inpainting的任务的同时,也公布了一个大型的mask数据集,该数据集在之后的 Inpainting 任务中被大量使用。作者对mask的孔洞大小进行了分类。每个种类有孔洞靠近边界的mask和
Pytorch 2.0来了!来看看新特性怎么应用到自己的代码里
Pytorch2.0和GPT4、文心一言同一时间段发布,可谓是热闹至极,我看了看Pytorch 2.0的文档,一句话概括下,2.0的功能介绍,核心就是加入这行代码就能优化你的模型,优化后的模型和往常使用方式一样,推理速度会提升,比较重要的一点是,可以用于训练或者部署,训练可以传梯度,这次是带有AOT



