
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
Abstract
方法
- Transformers与轻量级多层感知器(MLP)统一起来
吸引人的特点
- 分层结构的transformers编码器,并且不需要位置编码- 从而避免了位置编码的内插。 当测试分辨率与训练分辨率不同时,位置编码会导致性能下降。- 位置编码的缺点;
- 2.避免使用复杂的解码器,MLP聚合了不同层的信息- 结合了局部和全局注意力来呈现强大的表征
效果
- 网络更小,效果也佳- 定量评估数据集- Cityscapes validation set- Cityscapes-C- ADE20K
Code
- github.com/NVlabs/SegFormer.
1 Introduction
开创性的工作
- FCN
语义分割的两条主线
- 设计主干- 主干的演变极大地推动了语义分割的性能边界
- 结构化预测问题- 设计模块和操作,有效捕捉上下文信息- 代表性例子:空洞卷积,增加了感受野
transformer引入计算机视觉
- ViT- 图像分类
- SETR- 证明了语义分割使用Transformer的可行性
方法的改进
- SETR采用ViT作为主干并结合几个CNN解码来扩大特征分辨率
- ViT的局限- 1. 输出但尺度低分辨率的特征而不是多尺度的特征- 1. 在大图像上的计算成本很高
- PVT拓展ViT- 使用了金字塔结构- 比起ResNet在目标检测和语义分割上更优越
- 还有SwinTransformer和Twins
具体方法
- 一种新的无位置编码的和分层的Transformer编码器
- 一个轻量级的ALL-MLP解码器设计
效果
- 在三个公开可用的语义分割数据集中,SegFormer在效率、准确性和稳健性方面达到了新的水平。
2 Related Work
Semantic Segmentation.
- FCN、改进- 扩大感受野- 细化上下文信息- 边界信息- 设计各种注意力模块- 使用AutoML技术- 这些方法显著提高了语义分割的性能,但代价是引入经验模块,使对算力有要求;最近的用于语义分割的Transformers,仍然对算力有需求
Transformer backbones.
- ViT- 将每张图片视为一个令牌序列,将其喂到多个Transformer层里分类
- DeiT- 为ViT探索有效的数据训练训练策略和蒸馏方法
- T2T ViT ,CPVT,TNT,CrossViT, LocalViT- 引入了对ViT针对性的修改,进一步提高分类性能
- PVT- 是第一个在Transformer里引入金字塔结构的工作
- Swin[9]、CvT[58]、CoaT[59]、LeViT[60]和 Twins[10]- 增强了特征的局部连续性,并删除了固定大小的位置嵌入,以提高transformer在密集预测任务中的性能
Transformers for specific tasks.
- DETR- 第一个使用transformers构建端对端对象检测框架并且没使用NMS的工作,
- SETR- 采用ViT作为主干提取特征,但是效率低,因此很难在实时应用中部署
3 Method
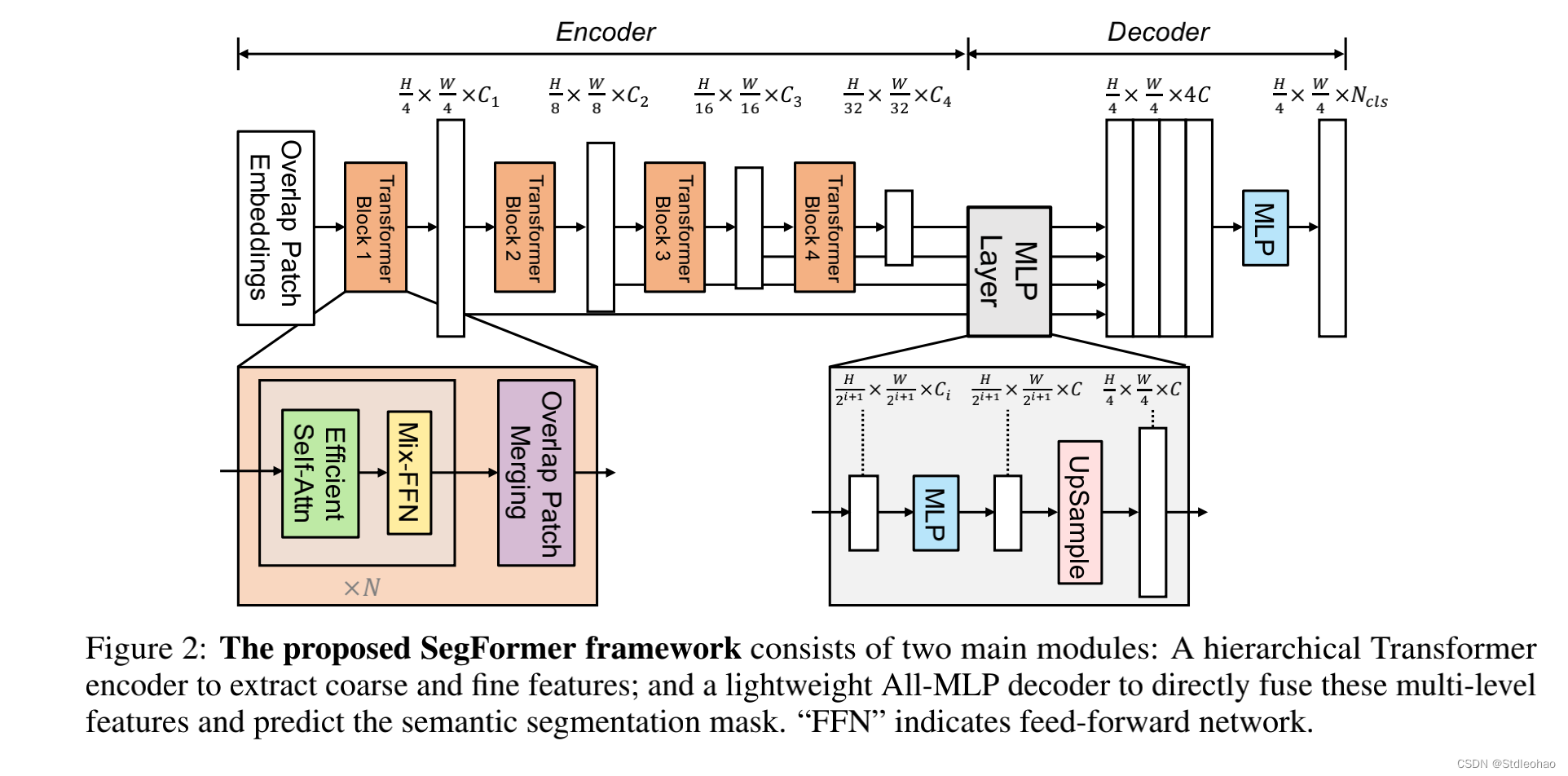
3.1 Hierarchical Transformer Encoder
- MiT-B0到B5具有相同的结构但尺寸不同。设计部分受到ViT的启发,但为语义分割量身定制和优化
- Hierarchical Feature Representation.- 这些特征提供了高分辨率的粗粒度特征和低分辨率的细粒度特征。
- Overlapped Patch Merging.- 使用一个重叠的补丁合并过程
- Efficient Self-Attention.- 计算瓶颈主要来自注意力层,减小K的大小
- Mix-FFN.- 我们认为位置编码对于语义分割来说实际上是没有必要的- 表明3×3卷积足以为Transfermer提供位置信息- 还是用了深度可分离卷积,减少参数数量,提高效率
3.2 Lightweight All-MLP Decoder
- MLP四步
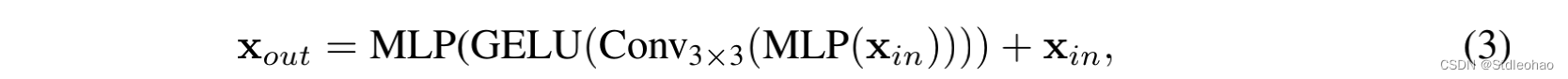
- Effective Receptive Field Analysis. -
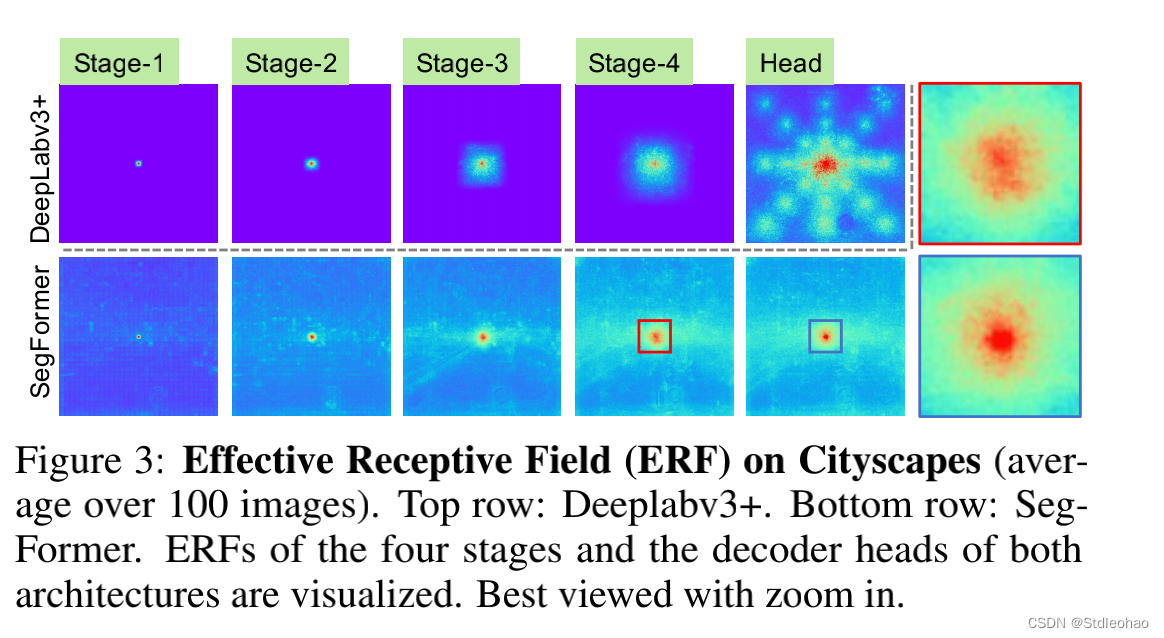 - 保持大的感受野以包括上下文信息一直是一个核心问题- 有效感受野(ERF)作为一个工具箱来可视化和解释为什么我们的MLP解码器设计在Transformer上是如此有效
- 保持大的感受野以包括上下文信息一直是一个核心问题- 有效感受野(ERF)作为一个工具箱来可视化和解释为什么我们的MLP解码器设计在Transformer上是如此有效 - 得益于Transformer里面的非局部注意,导致了更大的接收区域而不复杂- 与ASPP不同- ASPP扩大了感受野,但变得沉重- 在CNN主干中并不能很好地工作,因为整体的感受野有上限
3.3 Relationship to SETR.
- 我们在ImageNet-1K中预训练,ViT在更大的ImageNet-22k中预训练- 预训练更快
- SegFormer的编码器有一个分层结构,比ViT更小,并且可以捕捉到高分辨率的粗略特征和低分辨率的精细特征,相比之下,SETR的ViT编码器可以只能生成单一的低分辨率特征图。- 分层结构
- 我们删除了编码器中的位置嵌入,而SETR使用固定形状的位置嵌入。 当推理时的分辨率与训练时的分辨率不同时,会降低准确性。- 位置嵌入
- 我们的MLP解码器比SETR中的解码器更紧凑,计算要求更低。 这导致了可忽略不计的计算开销。相比之下,SETR需要繁重的解码器与 多个3×3的卷积。- 计算开销更小
4 Experiments
4.1 Experimental Settings
- Datasets:- Cityscapes- 是一个用于语义分割的驱动数据集,包括5000张精细注释的高分辨率图像,有19个类别。- ADE20k- 是一个场景解析数据集,涵盖150个细粒度的语义概念,由20210张图片组成。- COCOStuff- 涵盖172个标签,由以下内容组成164k图像。118k用于训练,5k用于验证,20k用于测试开发,20k用于测试挑战。
- Implementation details:- 8 Tesla V100.- 在ImageNet-1k数据集上编码器进行预训练,并随即初始化解码器。- 在训练过程中,我们通过比例为0.5,2.0的随机大小调整、随机水平翻转和随机裁剪来到512x512,1024x1024,512x512分别对ADE20K,Cityscapes和cocostuff- ADE20K的裁剪尺寸设定为640×640 的最大模型B5的裁剪尺寸- 我们使用AdamW优化器在ADE20K、Cityscapes上对模型进行了16万次迭代的训练。在COCO-Stuff上80K迭代。在消融实验上,40K次迭代- …- 为简单起见,我们没有采用广泛使用的技巧,如OHEM、辅助损失或类平衡损失。
4.2 Ablation Studies
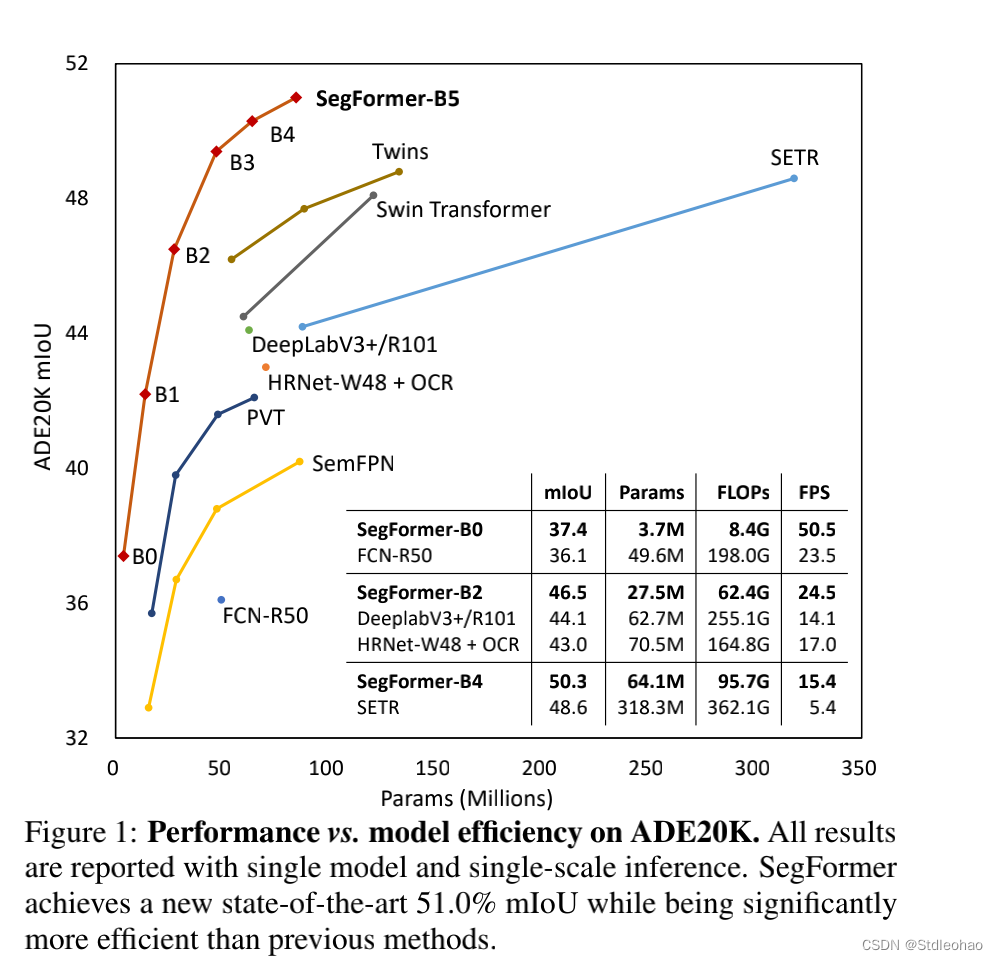
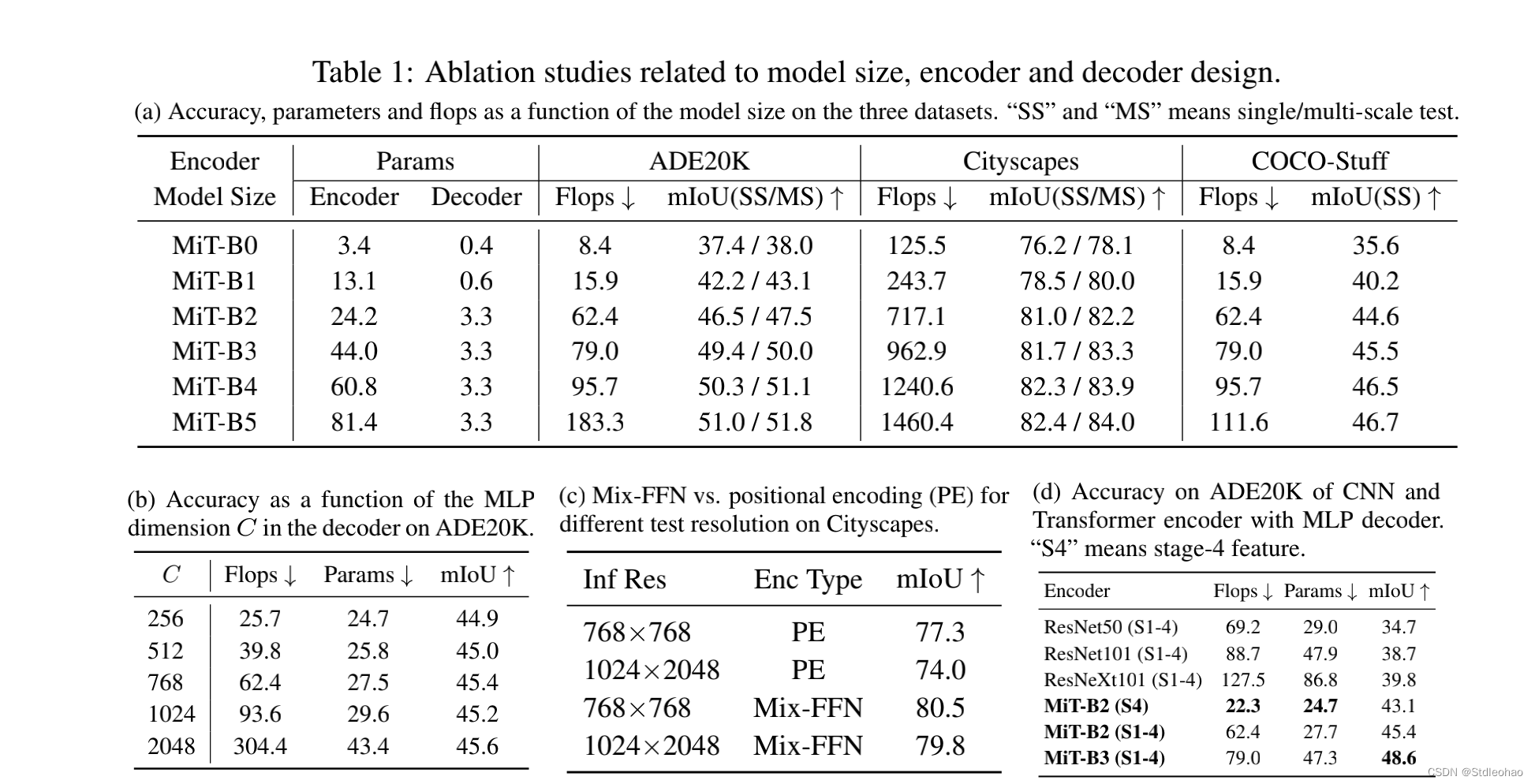
- Influence of the size of model.- 图一,显示了ADE20K的性能与模型效率的关系。ADE20k的性能与模型效率的关系是编码器大小的- 与编码器相比,解码器的大小只有0.4M- 我们的轻量级模型SegFormer-B0结构紧凑、效率高- 增加编码器的规模可以在所有的,数据集上产生一致的改进。
- Influence of C, the MLP decoder channel dimension.
- Mix-FFN vs. Positional Encoder (PE).
- Effective receptive field evaluation.
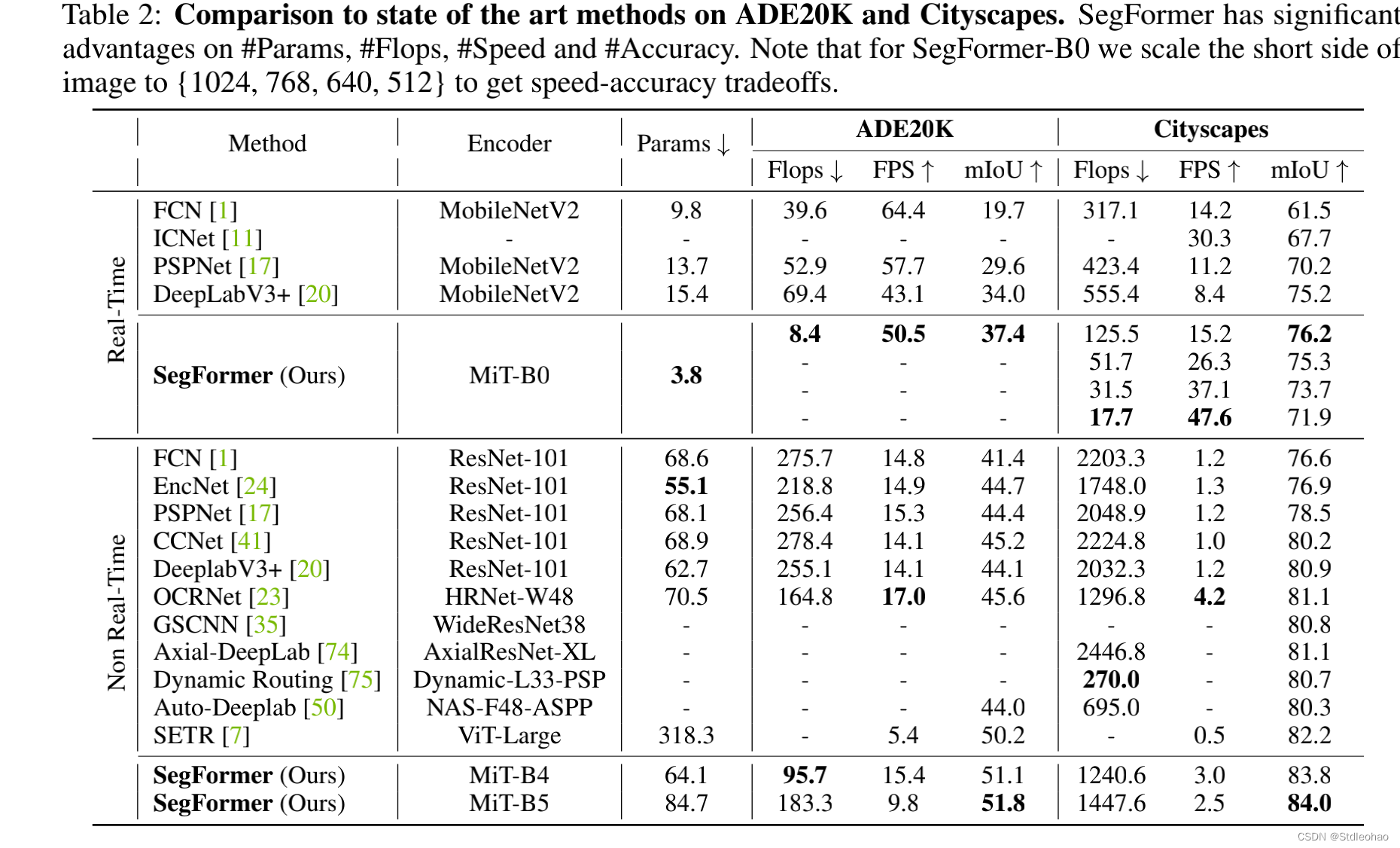
4.3 Comparison to state of the art methods
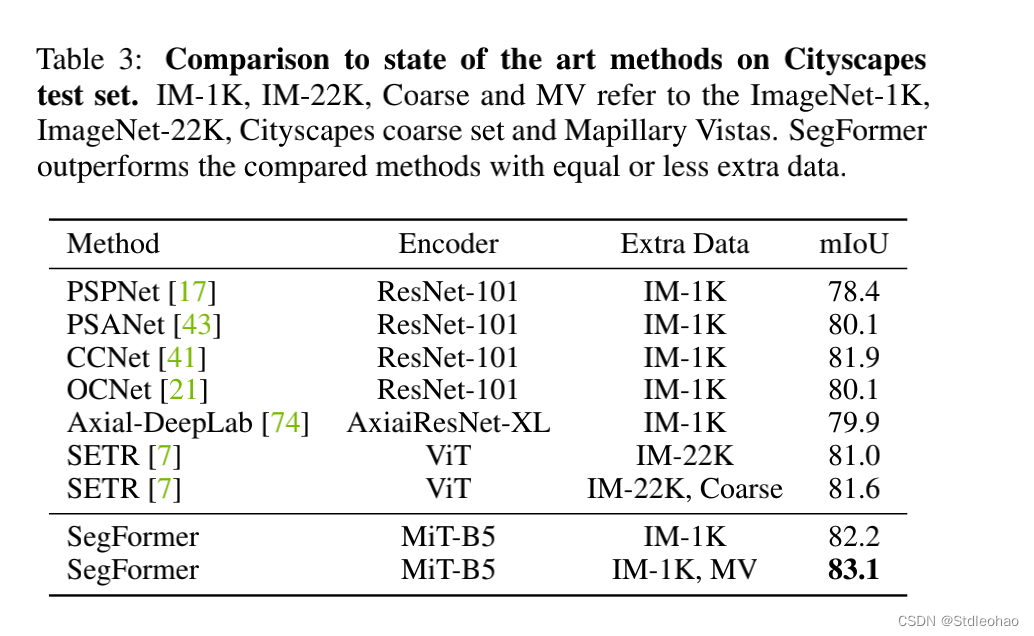
- ADE20K and Cityscapes:
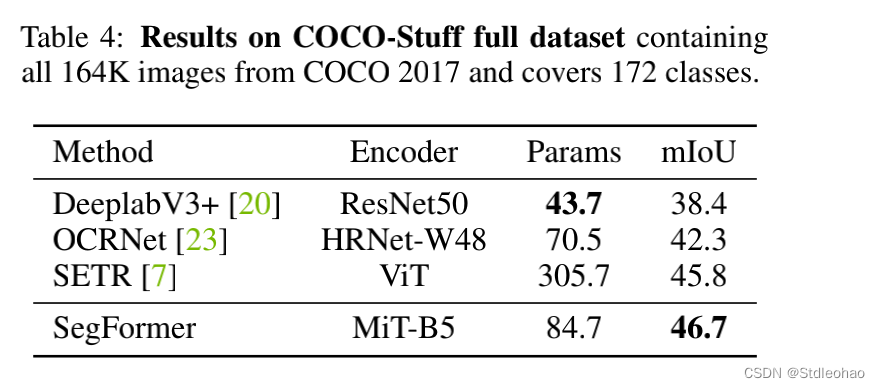
- COCO-Stuff.
4.4 Robustness to natural corruptions
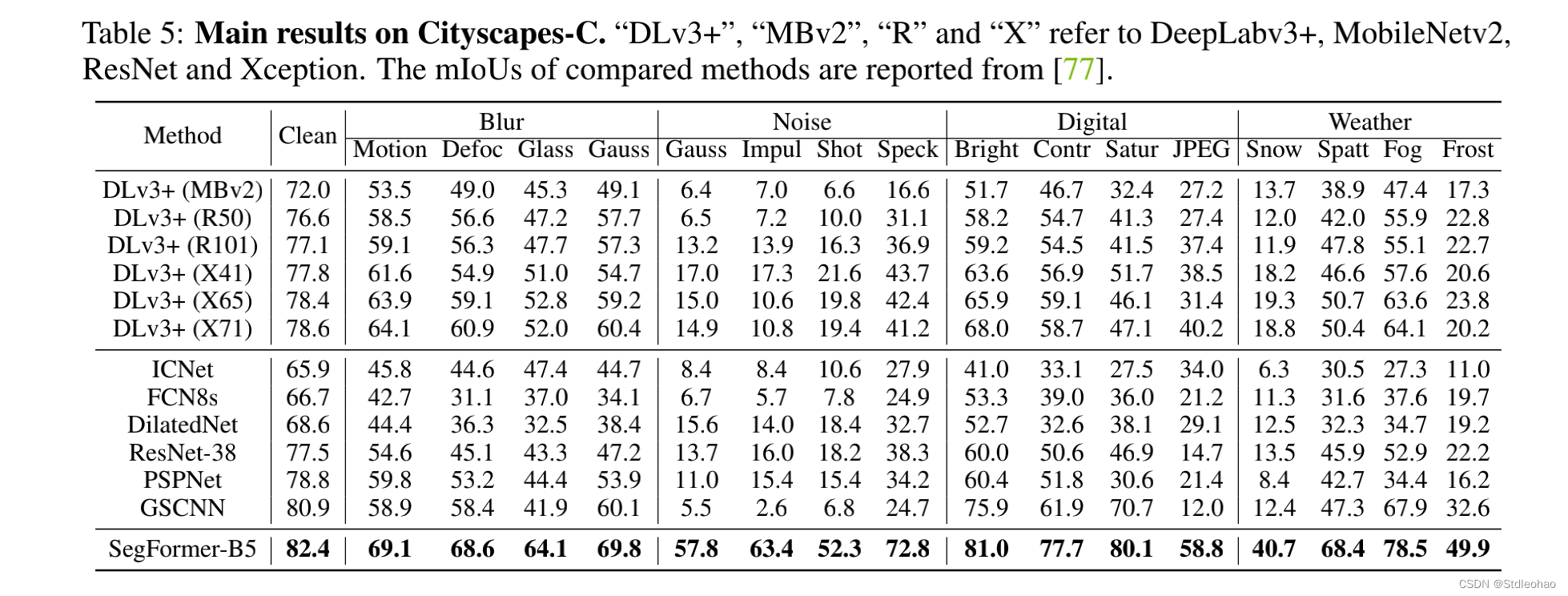
5 Conclusion
在本文中,我们提出了一种简单、干净而又强大的语义分割方法,它包含一个无位置编码的分层转换编码器和一个轻量级的All-MLP解码器。它避免了以往方法中常见的复杂设计,从而实现了高效率和性能。SegFromer不仅在公共数据集上获得了新的结果,而且还显示在零样本上的强鲁棒性。我们希望我们的方法能够作为语义分割的坚实基础,并激发进一步的研究。一个限制是,虽然我们最小的3.7M参数modEl比已知的CNN模型要小,目前尚不清楚它是否能在只有100k内存的边缘设备芯片上工作良好。
本文转载自: https://blog.csdn.net/stdleohao/article/details/124763831
版权归原作者 Stdleohao 所有, 如有侵权,请联系我们删除。
版权归原作者 Stdleohao 所有, 如有侵权,请联系我们删除。