
1、分别表示什么

TP(true positive):表示样本的真实类别为正,最后预测得到的结果也为正;
FP(false positive):表示样本的真实类别为负,最后预测得到的结果却为正;
FN(false negative):表示样本的真实类别为正,最后预测得到的结果却为负;
TN(true negative):表示样本的真实类别为负,最后预测得到的结果也为负.
acc准确率
准确率表示预测正确的样本数占总样本数的比例。
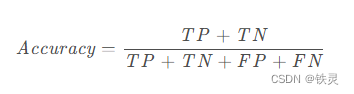
auc(area under the curve)
auc不像acc有准确的中文名称准确率,它是area under the curve首字母的缩写
从auc的全称里面可以得知它是曲线下的面积,,那么在计算auc之前,我们首先需要画一条曲线
ROC曲线受试者工作特征曲线 (receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve),我觉得在这里第二个名称更符合这里要做的事情(名称在这里并不重要)


FPR表示在所有真实negative中, 有多少是预测错误的
TPR表示在所有真实positive中,有多少是预测正确的
那么明显我们希望TPR越高越好,FPR越小越好
最好情况就是(0,1)这个点,最差是(1,0)这个点
那么出现一个问题,在预测时TP,FP,TN,FN都是确定的值,即FTP和TPR计算出来都是定值,在图中只会形成一个点,那么怎么会出现ROC曲线呢?
我们知道,在二分类(0,1)的模型中,一般我们最后的输出是一个概率值,表示结果是1的概率。那么我们最后怎么决定输入的x是属于0或1呢?我们需要一个阈值,超过这个阈值则归类为1,低于这个阈值就归类为0。所以,不同的阈值会导致分类的结果不同,也就是混淆矩阵(TP,FP,TN,FN)不一样了,FPR和TPR也就不一样了。所以当阈值从0开始慢慢移动到1的过程,就会形成很多对(FPR, TPR)的值,将它们画在坐标系上,就是所谓的ROC曲线了。
从上面这段话也可以感觉到感受性曲线这个名称可能更贴切我们做的工作
ROC曲线出来之后,就可以计算曲线下面积AUC了,AUC的取值范围 [0.5,1)
ROC曲线必经过(0,0)和(1,1)两个点
(0,0)表示全部预测为正例(positive)
(1,1)表示全部预测称负例(negative)

我们希望曲线向左上角靠近,所以AUC越大越好。。而AUC的最小值为0.5,表示分类器完全无效,同随机猜测正反面一样。
2、auc和acc之间的关系
没有关系,是两个评价指标
AUC有些很好的特性:如不用设定阈值、对测试集的正负样本数量比例不敏感、还有可以根据随机分类的AUC值为0.5易作为参考比较
其他的不再在这里进行讨论,这里讨论的是AUC对测试集的正负样本数量比例不敏感(数据不平衡的情况)
3、为什么又的论文里面只比较auc,但不比较acc
其中一个原因是acc需要设置阈值,而auc不需要设置阈值
4、loss、auc、acc的值是通用的,还是会根据代码中不同的设定,值也会发生变化?
计算loss有很多函数,如果选用不同的loss函数,那么结果也就不同
但如果选择同一个loss函数,是否可以横向比较模型的优劣
可以
下面是我看的一部分代码,在最后一行中loss是计算所以数据loss的和,所以只要是一样的数据集,就可以作为横向评价标准
for e in range(epoch):
losses = []
for batch in tqdm.tqdm(train_data, "Epoch %s" % e):
integrated_pred = self.dkt_model(batch)
batch_size = batch.shape[0]
loss = torch.Tensor([0.0])
for student in range(batch_size):
pred, truth = process_raw_pred(batch[student], integrated_pred[student], self.num_questions)
if pred.shape[0] != 0:
loss += loss_function(pred, truth.float())
acc一般不会根据代码中不同的设定,值发生变化,但要注意阈值的设定(但我不确定阈值如果设定的不一样,是否可以进行模型横向比较)
auc不用担心以上的问题,没有什么设定,计算公式也是一定的
参考:1、模型评估指标 AUC 和 ROC,这是我看到的最透彻的讲解 深入理解AUC——从概率意义的角度
版权归原作者 铁灵 所有, 如有侵权,请联系我们删除。