【人工智能】AI 人工智能技术近十年演变发展历程
人工智能是指通过计算机技术和算法实现模拟人类智能的能力。计算机视觉:通过计算机算法实现对图像和视频的理解和分析。自然语言处理:通过计算机算法实现对文字和语言的理解和分析。机器学习:通过大量数据和算法训练,使计算机能够自动学习和改进。深度学习:机器学习的一种,通过多层神经网络实现计算机对复杂问题的处理
【时间序列数据挖掘】ARIMA模型
ARIMA模型
实施 AI 最大的困难是什么?
虽然我们讨论的是专业知识,但考虑到 AI 在学习和教育中的概念有多新,可以肯定地说,找到具备必要知识和技能的人是一项相当大的挑战。尽管寻找可以将您的公司过渡到机器学习的供应商是一个可行的解决方案,但具有前瞻性思维的公司得出的结论是,从长远来看,投资于您的内部知识库更有益。换句话说,他们建议对您的员工

用于数据增强的十个Python库
在本文中,我们将介绍数据增强的十个Python库,并为每个库提供代码片段和解释。
“智慧时代的引领者:探索人工智能的无限可能性“
人工智能是一项具有非常广泛的应用前景和发展前景的技术。它在各个领域都产生了深远的影响,正在逐渐改变我们的生活、工作和社会。随着人工智能技术的不断创新和进步,未来的发展前景也将更加广阔。同时,人工智能技术的发展也面临着一些挑战和问题,例如数据隐私、算法偏见、人机关系等。因此,保障人工智能技术的安全、公
范数详解-torch.linalg.norm计算实例
本文以torch.linalg.norm(),详细讲解二范数、F范数、核范数、无穷范数、L1范数、L2范数的定义和计算。
如何用Python找出一组线性变化的数据中出现突变的值
通过计算每个数据点与前一个数据点之间的斜率差异,我们可以快速找到一组线性变化的数据中的突变点。使用Python实现此过程非常简单,只需要使用一个循环和一些数学运算即可。在实际数据分析中,我们可以根据具体情况调整阈值,以达到更好的结果。
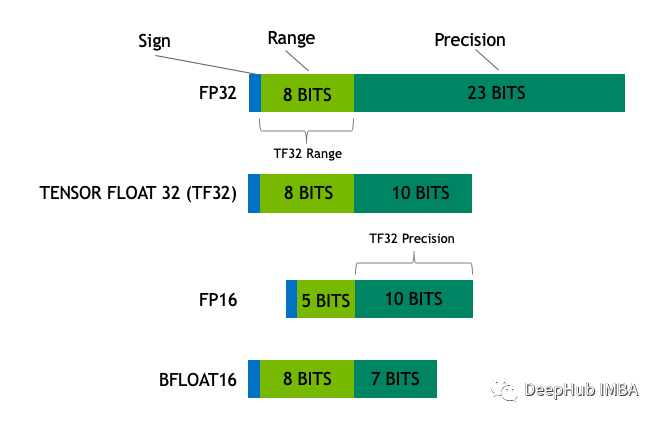
16,8和4位浮点数是如何工作的
在本文中,我们将介绍最流行的浮点格式,创建一个简单的神经网络,并了解它是如何工作的。
【人工智能】《大模型十问》—— 我们认为大模型值得探索的十个问题
看过有些评论说,大模型出现后NLP没什么好做的了。在我看来,在像大模型这样的技术变革出现时,虽然有很多老的问题解决了、消失了,同时我们认识世界、改造世界的工具也变强了,会有更多全新的问题和场景出现,等待我们探索。所以,不论是自然语言处理还是其他相关人工智能领域的学生,都应该庆幸技术革命正发生在自己的
【人工智能】大脑传:人类对大脑的认识与历史
尽管人工智能在模拟人脑过程方面取得了显著进展,但相比人类大脑的本质,仍有许多挑战等待我们去解决。随着相关研究逐渐深入,我们期待未来人工智能能够更进一步地发展,更好地理解和模仿人类大脑,为人类社会的发展做出更大的贡献。
LabVIEW AI视觉工具包(非NI Vision)下载与安装教程
LabVIEW AI视觉工具包(非NI Vision)下载与安装教程
YOLOv5系列 1、制作自己的数据集
文章目录前言一、下载Labelme二、Labelme使用步骤1.打开Labelme2.Labelme标记数据集3.保存为json格式三、json格式转换为txt格式四、建立自己的Yolov5数据集前言本文所使用的Yolov5为6.1版本,所用为GPU版(亲测CPU也一样能跑,只是速度会慢很多),使用
【ChatGPT】ChatGPT使用指南——文本生成
文本摘要任务指的是用精炼的文本来概括整篇文章的大意,使得用户能够通过阅读摘要来大致了解文章的主要内容。抽取式摘要:从原文档中提取现成的句子作为摘要句。压缩式摘要:对原文档的冗余信息进行过滤,压缩文本作为摘要。生成式摘要:基于NLG技术,根据源文档内容,由算法模型自己生成自然语言描述。以下是一个基于m
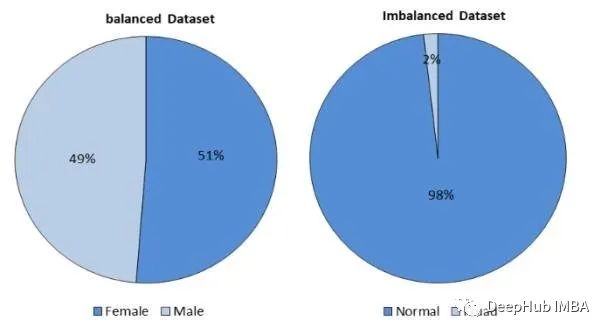
处理不平衡数据的十大Python库
在本文中,我们将介绍用于处理机器学习中不平衡数据的十大Python库,并为每个库提供代码片段和解释。
【人工智能的数学基础】圆周率(Ratio of Circumference to Diameter)的计算
圆周率π,在几何学中定义为圆的周长与直径之比,在分析学中定义为满足sinx0的最小正实数,其数值约为3.1415926。1988年3月14日,旧金山科学博物馆的物理学家组织博物馆的员工围绕博物馆纪念碑371722圈,并一起吃水果派。之后每年旧金山科学博物馆会在当天举办庆祝活动。2019年11月2
机器学习中的分类问题:如何选择和理解性能衡量标准
对于这些问题,我们需要一种方式来评估模型的性能,以便选择最合适的模型、调整参数,并最终在实际应用中做出可靠的决策。不同的问题可能需要不同的度量标准。绘制这两种曲线的过程相似,通常需要使用模型的预测概率来确定不同的阈值,并计算相应的性能指标。ROC曲线是另一种用于评估分类模型性能的工具,它关注的是模型
前向传播(Forward Propagation)与反向传播(Back Propagation)举例
前向传播(Forward Propagation)与反向传播(Back Propagation)
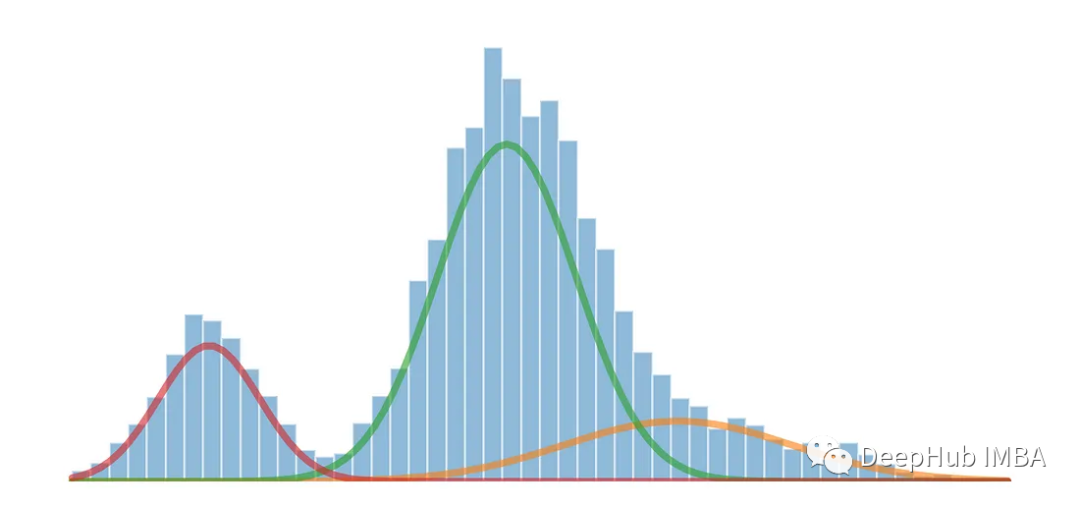
使用高斯混合模型拆分多模态分布
本文介绍如何使用高斯混合模型将一维多模态分布拆分为多个分布。
从AI 大模型到 AGI 通用人工智能 “世界模型”的演进路径
从AI人工智能到通用人工智能的演进,是一个不断探索和拓展智慧边界的过程。大型语言模型作为当前AI技术的代表,为我们提供了一个理解和生成语言的强大工具。然而,要实现通用人工智能,我们还需要构建更为复杂和完善的世界模型,模拟人类的认知和行为能力。通过研究和实践,我们相信通用人工智能终将成为现实,为人类带



