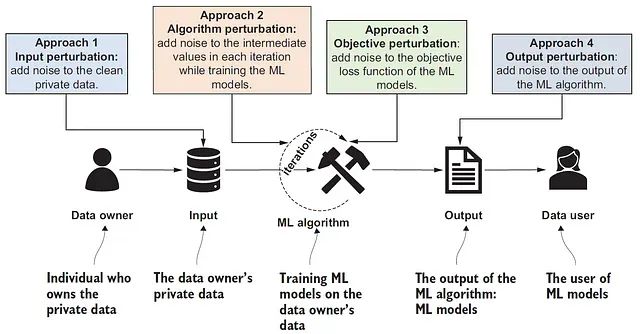
差分隐私机器学习:通过添加噪声让模型更安全,也更智能
本文探讨如何在模型训练过程中平衡实用性与形式化隐私保证这一关键问题。我们采用带有噪声梯度更新的模拟DP-SGD算法实现差分隐私机器学习。

告别低效代码:用对这10个Pandas方法让数据分析效率翻倍
本文将介绍 10 个在数据处理中至关重要的 Pandas 技术模式。这些模式能够显著减少调试时间,提升代码的可维护性,并构建更加清晰的数据处理流水线。

Python 3.14七大新特性总结:从t-string模板到GIL并发优化
本文基于当前最新的beta 2版本,深入分析了Python 3.14中的七项核心新特性。
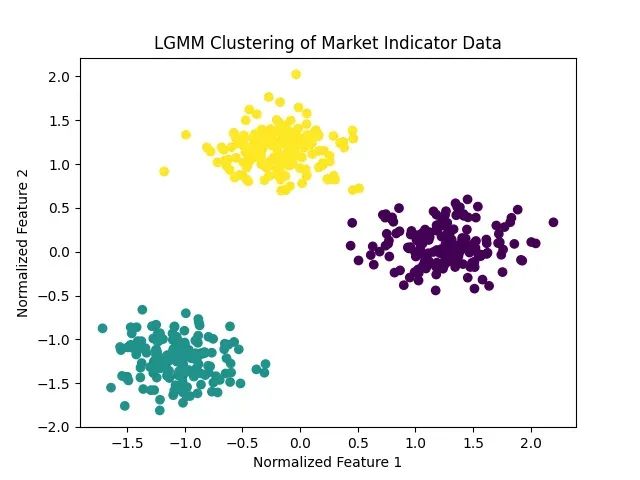
量化交易隐藏模式识别方法:用潜在高斯混合模型识别交易机会
本文将从技术实现角度阐述LGMM相对于传统方法的优势,通过图表对比分析展示其效果,并详细说明量化分析师和技术分析师如何应用此方法优化投资决策。
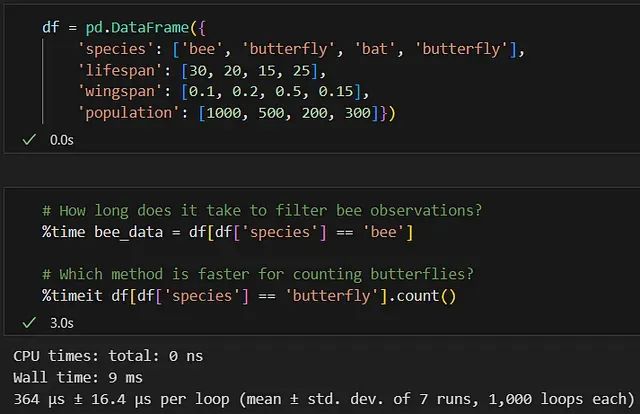
掌握这10个Jupyter魔法命令,让你的数据分析效率提升3倍
本文将详细介绍十个在实际数据科学项目中最为实用的魔法命令,并通过传粉者数据分析项目进行具体演示。
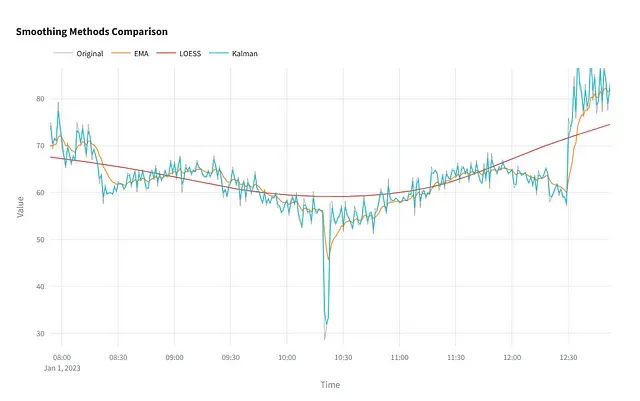
Python时间序列平滑技术完全指南:6种主流方法原理与实战应用
本文将系统介绍六种广泛应用的时间序列平滑技术,从技术原理、参数配置、性能特征以及适用场景等多个维度进行深入分析。
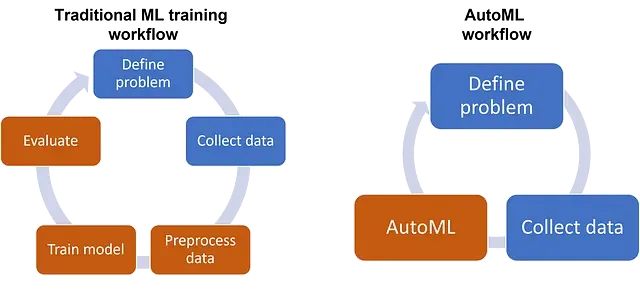
Python AutoML框架选型攻略:7个工具性能对比与应用指南
本文将系统介绍在实际项目中经过验证的主要Python AutoML库,分析各自的技术特点和适用场景。
大数据集特征工程实践:将54万样本预测误差降低68%的技术路径与代码实现详解
本文通过实际案例演示特征工程在回归任务中的应用效果,重点分析包含数值型、分类型和时间序列特征的大规模表格数据集的处理方法。
混合效应模型原理与实现:从理论到代码的完整解析
混合效应模型并非神秘的技术,而是普通回归方法在层次化结构建模方面的原理性扩展。这种理解将成为机器学习工具箱中下一个技术突破的重要基础。
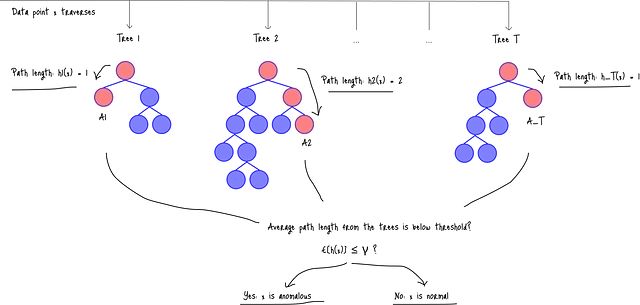
机器学习异常检测实战:用Isolation Forest快速构建无标签异常检测系统
本研究通过实验演示了异常标记如何逐步完善异常检测方案和主要分类模型在欺诈检测中的应用。实验结果表明,Isolation Forest作为一个强大的异常检测模型,无需显式建模正常模式即可有效工作,在处理未见风险事件方面具有显著优势。
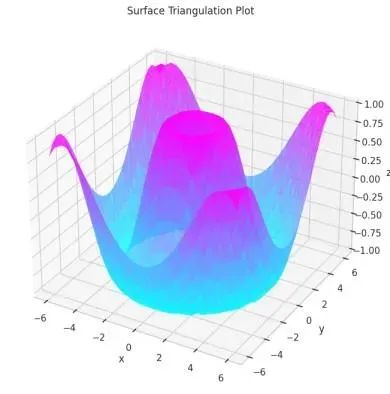
Python 3D数据可视化:7个实用案例助你快速上手
本文详细介绍了 Python 中基于 Matplotlib 库的七种核心三维数据可视化技术,从基础的线性绘图和散点图到高级的曲面建模和三角剖分方法。
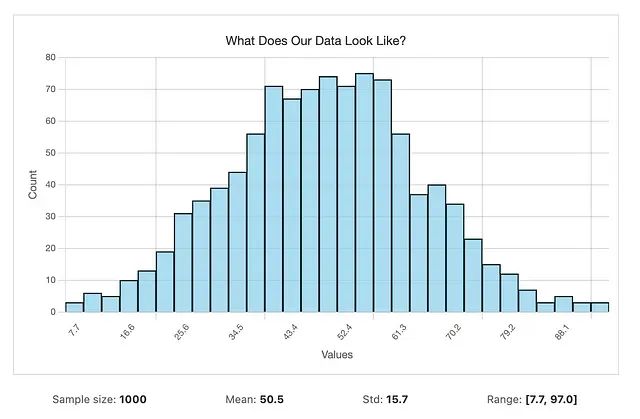
数据分布不明确?5个方法识别数据分布,快速找到数据的真实规律
本文介绍的方法和工具涵盖了大多数实际应用场景的需求。从基础的直方图分析开始,逐步深入到参数化和非参数化的分布拟合,再到结果验证和实际应用,形成了完整的技术体系。
DROPP算法详解:专为时间序列和空间数据优化的PCA降维方案
*DROPP (Dimensionality Reduction for Ordered Points via PCA) 是一种专门针对有序数据的降维方法。本文将详细介绍该算法的理论基础、实现步骤以及在降维任务中的具体应用。*
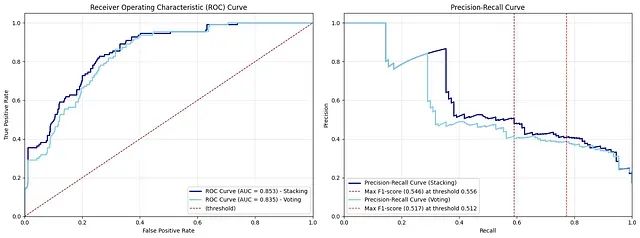
朴素贝叶斯处理混合数据类型,基于投票与堆叠集成的系统化方法理论基础与实践应用
本文深入探讨朴素贝叶斯算法的数学理论基础,并重点分析其在处理混合数据类型中的应用。

提升模型泛化能力:PyTorch的L1、L2、ElasticNet正则化技术深度解析与代码实现
本文将深入探讨L1、L2和ElasticNet正则化技术,重点关注其在PyTorch框架中的具体实现。关于这些技术的理论基础,建议读者参考相关理论文献以获得更深入的理解。
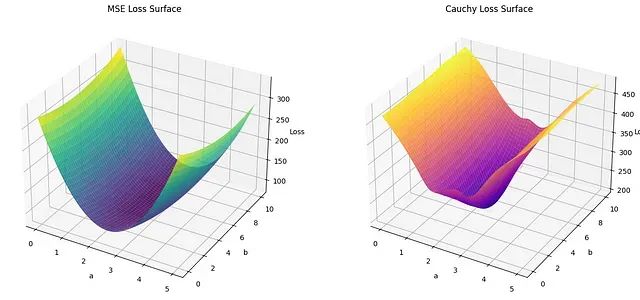
让回归模型不再被异常值"带跑偏",MSE和Cauchy损失函数在噪声数据环境下的实战对比
本文通过实证研究,系统比较了MSE损失函数和Cauchy损失函数在线性回归中的表现,重点分析了两种损失函数在噪声数据环境下的差异。

BayesFlow:基于神经网络的摊销贝叶斯推断框架
**BayesFlow** 是一个开源 Python 库,专门设计用于通过**摊销(Amortization)神经网络**来**加速和扩展贝叶斯推断**的能力。该框架通过训练神经网络来学习逆问题(从观测数据推断模型参数)或正向模型(从参数生成观测数据)的映射关系,
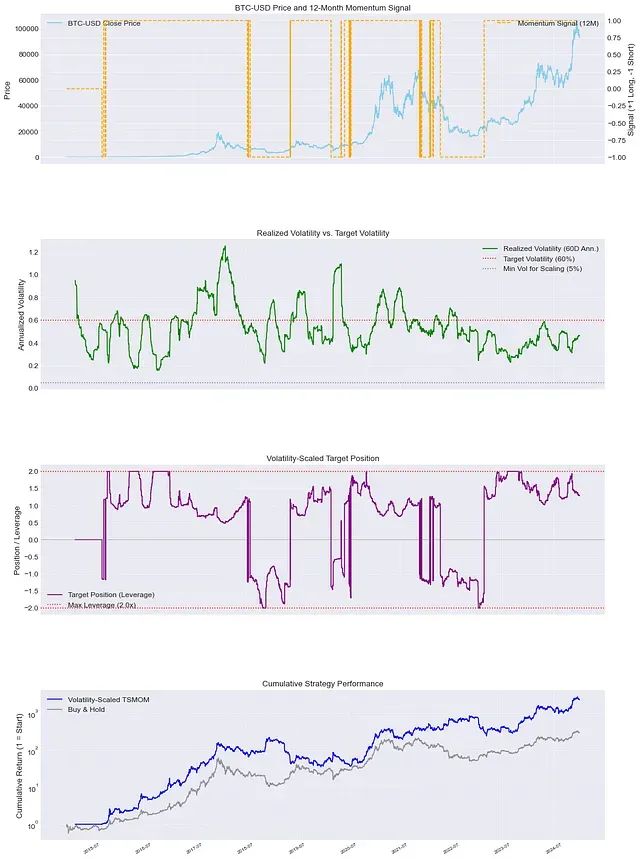
Python实现时间序列动量策略:波动率标准化让量化交易收益更平稳
本文将系统性地分析波动率调整时间序列动量策略的机制原理、实施方法以及其在现代量化投资框架中的重要地位。

解读 Python 3.14:模板字符串、惰性类型、Zstd压缩等7大核心功能升级
本文将深入分析 Python 3.14 中最为显著的**七项核心技术特性**,探讨它们对开发效率与应用架构的实际影响。
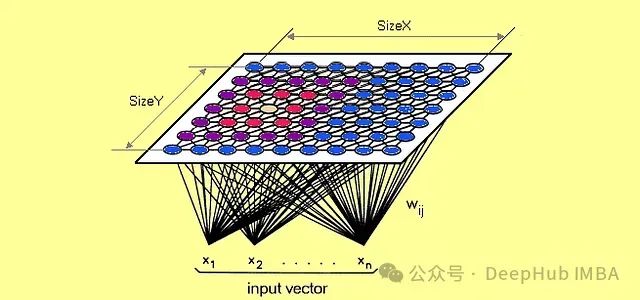
面向概念漂移的动态自组织映射(SOM)及其在金融风险预警中的效能评估
自组织映射(Self-Organizing Maps),又称**Kohonen映射**,是由芬兰学者**Teuvo Kohonen**在20世纪80年代提出的一种无监督神经网络模型。其核心功能是将高维数据空间投影到低维(通常为二维)网格结构中。



